OCLC – GBV – SUB Göttingen
1 Goals and underlying assumptions *
2 Participants and their respective role, organizational structure *
3 Methodological approach *
3.1 Processing of Set1 *
3.2 Processing of Set2 *
3.3 Further investigations *
4 Results *
4.1 Categories *
4.2 Reuse of existing data *
4.2.1 Name authorities *
4.2.2 Corporate bodies / Entries under names for persons and corporate bodies *
4.2.3 Title entries *
4.2.4 Multi-volume publications and other hierarchical structures *
4.2.5 Conclusions from 4.2 *
4.3 Future conditions for more efficient reuse *
4.3.1 Name authorities *
4.3.2 Title entries *
4.3.3 Multi-volume publications and other hierarchical structures *
4.3.4 Romanization *
4.4 REUSE results and possible links to ‘Functional requirements ...’ as a future modeling frame for bibliographic objects *
4.4.1 Some remarks on the possible relevance of the „Functional Requirements ..." study to the REUSE project *
4.4.2 Remark on ‘Metadata’ *
4.4.3 Personal Names *
4.4.4 Multi-part Publications *
5 Relation to other projects *
5.1 BSB *
5.2 USEMARCON (EU) / DDB and JOUVE *
5.3 Workshop on UNIMARC and EU Projects *
5.4 OCLC - National Library of Russia *
5.5 International Conference on the Principles and Future Development of AACR *
6 Concluding remarks *
The overall goal of the reuse project is to contribute to the enhancement of international bibliographic compatibility within the specific working context of German libraries and library networks. The project has been launched by OCLC, GBV/BRZN and SUB Göttingen in January 1996 and was concluded with a final meeting 13th of March 1997 in Dublin / Ohio. A follow-up activity (reuse+) will investigate questions that have not been completely dealt with during the project’s lifetime (namely bibliographic hierarchies).
The present document recapitulates the goals and assumptions agreed upon by the participants in September 1995 (1), lists the participants involved and describes the organizational structure of the project (2), gives a short account of the methodological approach adopted (3), gives an account of the results achieved (4), briefly discusses possible relations with ongoing activities in the field (5) and concludes with a series of general statements / observations that might be taken up again in different contexts. Some of these statements specifically relate to the „Functional requirements of bibliographic records" prepared by an IFLA Study Group.
Two observations originally led to the definition of the goals of reuse:
Two factors usually are held responsible for this situation: incompatibility of the formats for data exchange (MAB vs. USMARC) and incompatibility of the cataloguing rules used in the respective contexts (RAK vs. AACR2).
At the beginning of the project it was assumed, that the incompatibility of the formats used should not be considered a major influencing factor because existing conversion utilities as well as MAB in its new version (MAB2) should allow for a formally sufficient representation of data from the Anglo-American context within German cataloguing systems.
It was suggested therefore that the main obstacle preventing massive reuse of these data resides in the differences between the underlying cataloguing rules (AACR2 resp. RAK-WB). These differences (mainly in the representation of bibliographic hierarchies and the rules for generating and handling of authority information) were supposed to account for the need of heavy manual/intellectual modification of data received from LC, BNB or OCLC when reused in German union-catalogues such as the Pica-System of GBV (Gemeinsamer Bibliotheksverbund) or the Südwestdeutscher Bibliotheksverbund (SWB) by partners like Göttingen State Library or University Library in Heidelberg.
In order to address these issues of formal and semantic incompatibilities two main tasks have been defined for the project (further referred to as WP1 and WP2):
WP1: Systematic identification/description of the main differences in the representation of bibliographic objects according to AACR2 resp. RAK. It was assumed that the crucial areas to be investigated are multi-volume and serial publications as well as the use of authority files. This was to be achieved in comparing sets of data from OCLC and from German partners referring to identical bibliographic entities. Two pairs of data sets have been chosen for this comparison: SET1 consists of records created by SUB Göttingen in the GBV database according to RAK as compared to corresponding records extracted from the OCLC database by the use of an identifying matchkey, SET2 is composed from records created by UB Heidelberg in modifying OCLC title records as compared to the records originally supplied by OCLC in the late eighties. Within both SET1 and SET2, ‘a’ signifies German records and ‘b’ signifies OCLC-records.
WP2: Make a serious attempt to develop algorithmic methods for data conversion which would go beyond methods of basically mechanical tag-mapping and which might result in a significantly higher degree of ‘RAK-conformance’ of data received from OCLC. Ideally, these algorithms should produce results almost identical to SET1a and SET2a in processing the respective b-sample. It was suggested to combine these algorithmic procedures with attempts to build multilingual authority files.
WP 1 and WP2 have been carried out in an interconnected, iterative approach involving documentation activities and the building of prototypes.
Depending on the results of this methodological approach substantial enhancements were expected mainly in two areas:
Positive results from the algorithms implemented in WP2 would lead to the operational routines, which would substantially raise the attractiveness of data such as provided by OCLC on the German market.
Negative results from WP2 should lead GBV and others to seriously question the future justification of a specific German cataloguing policy (RAK). As the project partners are seriously convinced that international bibliographic compatibility will be of increasing -- and prevailing -- importance for German librarians, remaining incompatibilities even after applying the methods to be developed in WP2 should lead to the alignment of cataloguing rules as the only alternative available. Not everybody in Germany is aware, however, that the AACR2 rules do not "tell the whole story" about the content of USMARC records: the LC Rule Interpretations have to be taken into account as well, and these are even more voluminous.
The steering committee was composed of Monika Münnich (chairman of Germany’s Expert Group RAK [EG-RAK] at the Deutsches Bibliotheksinstitut), David Buckle (subsequently replaced, after his retirement, by Janet Mitchell) and Glenn Patton (OCLC), Barbara Tillett (LC, acting as an advisor for OCLC in the project), Cornelia Katz (Bibliotheksservicezentrum Konstanz), Bernhard Eversberg (University Library of Braunschweig), Elmar Mittler (SUB Göttingen) and Stefan Gradmann (GBV/BRZN).
The project has been entirely funded by OCLC.
Staff of GBV/BRZN (with substantial help from OCLC) has carried out the core work on WP2 and WP1; Bernhard Eversberg, Monika Münnich and Barbara Tillett supplied major contributions with respect to the differing cataloguing rules and data models. Monika Münnich integrated important comments from members of EG-RAK.
Furthermore, a number of persons were actively involved in work related to the project at different stages without formally being part of the project group. Contributions were received from Claudia Fabian (Bayerische Staatasbibliothek, München, and member of EG-RAK), Emma Lee Yu (City University of New York), Jürgen Braun (GBV/BRZN), Michael Rzehak (GBV/BRZN) and Feruzan Akdogan (GBV/BRZN).
SET 1a contains 16.380 records in PICA+-format. A file containing the corresponding matchkeys had been sent to OCLC and as a result 9.159 (55,92% of SET1a) records representing exact matches in OCLC’s database were returned to GBV/BRZN in MARC-format. GBV/BRZN did carry out some (limited) investigation concerning the more than 7.000 records that were not matched or that led to ambiguous results. As a result from these investigations three general remarks can be made concerning the impressive number of unmatched records / ambiguous results:
Some of the many unmatched records would probably have found a counterpart if the process of gathering candidates in the OCLC-database would have been repeated with - either - a refined and adapted matchkey definition (although the key used in the tapecon-procedure is fairly elaborate already) or combined with a suitable pre-processing of source tag contents that were the basis for building the matchkeys. The findings mentioned further down under 4.2 might provide elements for both (matchkey refinement and contents preprocessing) -- still we do not expect dramatically improved results from such an attempt.
The high number of ambiguous results (2 or more hits) is a significant result in itself as it is probably due to structural discrepancies between the underlying data models. A main entry for a multi-volume publication issued from the German context (and combined with numerous analytical records for the individual volumes in the GBV-database) did in many cases meet a ‘flat’ representation of the same entities in the OCLC-database (i. e. many volume records each containing the same ‘main title’ tag, and this typically results in a 1-n relation).
Finally -- and as a result of this last remark -- the results from the subsequent processing of the actual pairs retained have to be interpreted cautiously: these basic sets already exclude the whole range of structurally divergent entities and thus suggest a higher degree of matching precision in the multi-volume-area than can actually be achieved!
Two assumptions have been made before processing these records. German partners in reuse came from different library networks (Gemeinsamer Bibliotheksverbund / GBV, Südwestdeutscher Bibliotheksverbund / SWB) using proprietary data structures and formats as well as proprietary conversion routines as a consequence. The only generic data format transcending these different contexts is MAB2. The only available non-proprietary conversion tool that all the partners are more or less familiar with is allegro C. It was thus decided to convert both subsets to MAB2 using allegro C in order to obtain comparable subsets.
Two databases have been built from these subsets whose contents are linked on record level (where possible): it is thus possible to do intellectual ad-hoc-comparisons of records originated from GBV and from OCLC in a very comfortable way. Besides, two databases in the respective source-formats (PICA+/USMARC) have been built which allow the inspection of the original, unmodified records. These databases were the core working-tool for the project and can be inspected via Internet (Telnet to 134.169.20.3, login as ‘opac’ with password ‘opac’ and then select ‘reuse’ option). In order to deal with minor incompatibilities of MAB and MARC some non-standard additions to MAB have been defined. These extensions are clearly identifiable using an additional extension of MAB tag-indicators.
For the creation of SET2 MAB records had been supplied by SWB and did not present major problems for processing. The next task was to extract the corresponding, unmodified records from the OCLC database. The records supplied by SWB still contained OCLC’s identifying number in MAB tag 572. A TAPECON file containing this ID-number instead of a matchkey therefore was prepared by GBV/BRZN and sent to OCLC. The resulting file supplied by OCLC was processed using the same conversion procedures as used for SET 1 and two databases for comparison were created analogously to the processing of SET 1.
Processing of SET 2 has been given less attention in favor of SET1 for several reasons:
SET2 was much easier to process (SWB had provided MAB-records already, no new conversion routines will have to be defined for the corresponding subset received from OCLC; retrieval of the corresponding set by OCLC was not a major problem due to the presence of the original ID-numbers)
Results from the comparison of the SET 2-subsets were expected to be less clear and maybe difficult to determine, because it was impossible to reconstruct one important intermediary stage: SET 2-records had been delivered by OCLC in MARC-format and converted by DDB to MAB1 before handing the records over to SWB, where a second conversion was done before integrating the records in the SWB-database. As the result of intermediary conversions, data is definitely lost and it often is impossible to pinpoint who or which agency was the instance responsible for changes to the records.
As far as structural differences between the respective data models in the crucial field of multi-volume publications are concerned SET 2 is close to insignificant: 7138 out of the 7379 records supplied by SWB in fact are records of MAB type ‘h’ (main records), 218 are of type ‘n’ and only seven of the records originally supplied by OCLC have been transformed into ‘type u’ records (analytical records for parts of multi-volume publications). It is thus evident that the records supplied to SWB by OCLC have been used systematically and almost exclusively for the generation of catalog records for ‘simple’ monograph publications (isolated or with a series statement). This was logical in the original cataloguing context: librarians did use only those records that could be integrated in the German catalogue environment without major structural changes - although quite some work was necessary to establish links to German authority records - and thus did their job efficiently. Still this seriously affects the significance of SET 2 in the reuse context: major problematic cases were systematically excluded in this approach.
Finally, one should bear in mind, that SET2 reflects the situation of the late 1980s and thus may partly be of historical interest only, because RAK rules have changed since then.
Following the steering group meeting in June 1996, the databases for comparative work resulting from the first processing of SET 1 and SET 2 were installed at the partner sites working on WP1.1 by GBV/BRZN, extensive printable listings asked for by these partners were supplied by BRZN as well.
Processing of both sets has subsequently been refined by GBV/BRZN with a focus on basic structural differences on record level (presence / absence of fields in the respective records, identity / non-identity of field contents), structural and semantic differences on field level (identity / non-identity of field contents further analyzed: identical substrings, typically differing substrings?) and on complex differences (partly) reaching beyond record level (multi-record structures vs. flat representations of bibliographical hierarchies) and thus to cover the categories 4 and 5 (also mentioned under section 4).
Monika Münnich, Barbara Tillett and Glenn Patton carried out parallel investigations concerning these focal points; their comments were integrated in the refinement of the set processing by GBV/BRZN.
The final report was drafted by GBV/BRZN together with Monika Münnich and Barbara Tillett in January/February 1997; the other members of the project group supplied valuable comments to this final document in the last stage of the drafting process.
The following presentation of the overall project results does not attempt to give a detailed account of all observations made during analysis of the reuse corpus but tries to sum up and synthesize these results.
Generally, the following two areas should be distinguished in this respect:
Furthermore, five distinct categories for further investigation had been defined in the June 1996 steering group meeting. Accordingly, this overview is organized along these categories within the sections 4.2, 4.3 and 4.4. The five focal points for further analysis of representation differences are given below together with some general comments.
Name authorities: Although no authority records were delivered for persons/personal names it seems possible to generate brief authority records from the OCLC-file, these authority records could subsequently be mapped to those present in the GBV-database. Parallel activities are currently carried out in Germany for systematic comparison of the respective authority files on a national level (PND vs. Name Authorities, Die Deutsche Bibliothek is cooperating with LC in this field in the CoCat-project). It was decided to link project work to these external activities as much as possible but at the same time to compare name entries in the two sets (the relation that can be established between the differing name entries via the common context of the bibliographical entity may serve as a valuable complement for systematic comparison of authority files). The overall aim in this field was to contribute to the building of a conceptual framework for multilingual authority files for personal names.
Corporate bodies: The situation is fairly more complex for names of corporate bodies. Although it is technically possible to generate authority records from the OCLC-file the mapping of these to records of the German GKD (National Database for Corporate Authorities) seems to make little sense due to the fundamental semantic differences in the respective concepts of what is considered a corporate body (meeting-entries/Konferenzen are a particular problem in this field). Still, some systematic comparison work was done on the respective corporate entries in the two file sets mainly based on automated mapping routines provided by GBV/BRZN. Work in this field was linked to ongoing activities in Germany, too (project carried out by Ms. Hoffmann at HBZ/Cologne). A working group of EG RAK has been set up that is mainly analyzing examples taken from GKD and the corresponding entities (that were retrieved from the ‘Name Authorities’ File by LC).
Title entries: Special attention was given to the comparative analysis of title entries in the record sets. All relevant tag contents were be indexed by GBV/BRZN and printable lists containing entry pairs were provided to help the partners involved in this work.
Multi-volume publications: At least two different representations strategies can be distinguished in the OCLC-file (one record per volume with volume-titles in MARC 245 + title of MV-publication vs. one record for MV-publication containing volumes in MARC 505/contents note). The same general structural discrepancy can be observed for contained items. In both cases the mapping to multi-volume data structures as they are commonly used in German databases was expected to be possible and was seriously attempted subsequently. Mechanisms for the mechanical mapping of such structures provided by GBV/BRZN should be the basis for further analysis by the other partners leading to recommendations for refined algorithms to be re-implemented by GBV/BRZN.
Other hierarchical structures: It was decided to systematically investigate the possibility of mapping the structures used for contained/added items (MARC 245 / Contents note vs. multi-record representations) and for items linked to series information.
Work on multi-volume and other hierarchical structures is of specific interest not only for the German context: LC is very interested in making use of bibliographic data issued from Germany. Although reuse is clearly focused on transfer of MARC-data to Germany, this aspect of project work should provide elements for improving data transfer in the opposite direction.
The observations presented in the following section are derived mainly from the processing of SET 1 and subsequent statistical analyses. No fundamentally divergent observations have been made in processing SET 2, and the various reasons given above under 3.3 led us to the assumption, that observations drawn from SET 2 should be given a very limited significance, anyway.
Assessment of the perspectives for reuse of existing catalog data should be done with a clear notion of the relevant working context, i. e. bearing in mind what these records could typically be used for: catalog conversion, reconversion and upgrading of existing databases are expected to be the relevant activities in this respect rather than current cataloguing of newly acquired material (this latter activity will be covered by the 4.3 section of this report). Section 4.2.5 (‘Conclusions from 4.2’) attempts to set out some of the perspectives, that can be derived from the analytical work provided by GBV/BRZN in this sense.
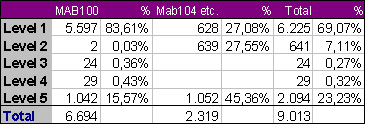
9.013 Name entries contained in the OCLC-records as part of SET1-pairs have been checked against the respective entries contained in PICA-records. Five different levels of similarity are distinguished in the table below:
A further distinction is made between levels of similarity for ‘First Author’ tags (MAB100) vs. ‘Other Persons’ in MAB104 etc.
The main differences typically encountered among the 2.094 differing entry forms are:
OCLC typically contains more entries in the case of several contributors (RAK limits entries to the first editor / contributor in such cases)
Different handling of Anglo-American compound surname (e. g. Sparck Jones, Karen vs. Jones, Karen Sparck)
The following section is based on the statistical data as given in the annex. Out of 657 corporate bodies in MAB200 only 88 were identical, differing forms were found in 270 cases, in 299 cases no counterpart was found for a corporate body present in the OCLC record.
As far as the actual differences between the corresponding entries are concerned, the remarks in 4.2.1.2 are valid also for the differing forms in SET1; the reader is thus referred to this section.
In order to explain some of the - far more intriguing - cases of structural difference (non-correspondent entities) the following remarks on principles for the creation of entries are given. They apply both to names of persons and those of corporate bodies (these should be considered in a common context in this case) and mostly refer to RAK rules §§ 6XX. According to the general remarks on entries (cf. below under 4.3), no difference is made between main and added entries. Furthermore, no rules for special material types (such as non-book materials or cartographic material) are taken into account.
GBV/BRZN exclusively concentrated on the main title entry (MAB331) as the central identifying element and the key factor for matching operations (cf. below under 4.2.5).
Results (as shown in the annex) are encouraging: there are no major rule dependent differences between the respective entries, the degree of matching is high (81.03%) even when comparing ‘raw’ title strings. Differences occur mainly as a result of misspellings, different spelling conventions (e. g. ss vs. ß) and differing transliteration conventions. These differences can efficiently be resolved using simple and comparatively robust normalization routines. This results in a significantly increased identity factor (93.11%) in the second pass. The remaining differences are due to remaining transliteration effects and mainly to different interpretations of what is to be considered an addition to the main title (MAB331 vs. MAB335).
Both focal points are presented together in this paragraph, because one of the main lessons to be learned from this part of our work is, that the distinction currently made in the German environment is not applicable to the data originated from the Anglo-American context.
The following three main models for the representation of hierarchical bibliographic structures were found in the sets processed by BRZN:
or
Linking structures complying to the data models currently used in German applications might eventually be derived from model b). Decomposition of MARC 505 is a very complex task (close to impossible, the distinction between intellectual and physical volumes as part of this tag is not algorithmically possible). Moreover, the criteria for use of either of these models in the OCLC database (and in U.S. cataloging practice in general) have varied over time. Decisions on creation of a single record for a multi-volume work versus individual records tied together with series entries (4XX and/or 8XX fields) have been made based on local needs (we recognize another structure for in-analytics with 7XX added entries is possible, but we did not encounter examples in our test sets). The use of complex contents notes in field 505 has increased as libraries have moved into online catalogs which have provided indexing for those fields and which have removed some of the difficulty of maintaining contents notes that existed in card catalogs.
The possible use of yet another modeling approach involving the use of MARC field 774 for downward linking has been discussed without decisive results, this discussion is meant to be finished in the frame of reuse+.
A potentially viable strategy of consistently mapping these conflicting models to a common target model in record conversion would require a radical decision in the German target environment: giving up of the distinction between MV-works and monographs as parts of serial publications (and using a uniform linking structure in both cases), eventually even replacing the ID-numbers used as pointers to authority records today with textual links, all this together with a complete re-conversion of existing databases for cooperative cataloguing and re-conversion of their local derivatives (OPAC systems, circulation control applications etc.)
And even such a decision probably would lead to an unsatisfactory situation: due to the differing and sometimes conflicting representation models used in the Anglo-American source files the application needed for the subsequent record conversion would have to be a full grown AI-application ...
If one considers the conditions for reuse of existing data as briefly discussed at the beginning of this chapter it is evident, that the efforts necessary for the creation of such a (highly experimental) scenario together with the subsequent complications and risks for existing databases (and applications tailored to these structures) largely exceed the eventual profit to be expected from such an activity, as far as multi-volume publications are concerned.
Three general conclusions should be retained from our work on the two sets.
It is possible to efficiently enhance bibliographic compatibility as long as records are structurally compatible (this is typically the case with monographs). This can be illustrated by a diagram derived from statistical analysis of SET1. This set has been processed twice and an attempt has been made to enhance the degree of identity for the contents of tags highly present in both subsets. Relatively simple normalization routines have been used in these cases. As the combination of high overall frequency together with high similarity of contents was considered to be significant in the sense of identifying relevance of a given tag each tag has been attributed a ‘matching relevance’ factor ([(occurrence*10+identity*5) / 15.37] in order to match 100% for ‘main title’). This relevance factor has been significantly increased for a core set of tags from pass 1 to pass 2 as shown in the following diagram:
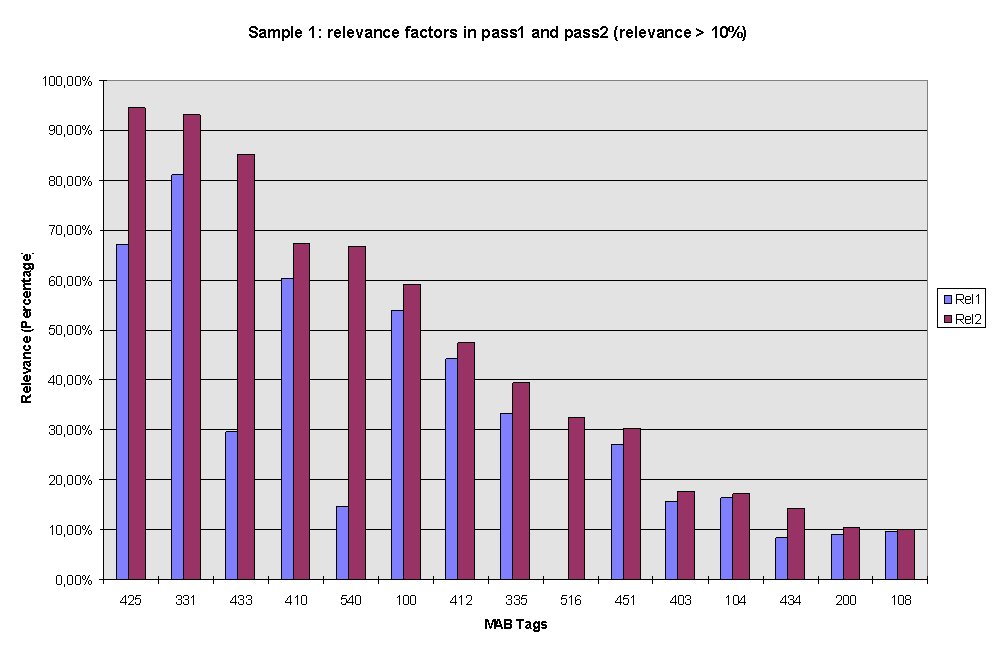
Thus, for ‘simple’ monograph publications not only can the degree of ‘reusability’ efficiently be enhanced but - and this is most important for conclusion (3) below - this can be done concentrating on five identifying elements highly relevant for matching operations
These five elements may be considered the core matching elements with regard to the proposal made in conclusion (3) below. Even if ‘first author’ / MAB100 has a comparable matching relevance and thus one could think of including this field in the ‘matching core’ such a decision would probably have unwanted systematic effects: the five elements retained here present the advantage of containing no linked information and can be treated independently without having to deal with the more complex data structures related to authority records. This possibility of establishing robust matching operations that are relatively simple to administrate will reveal its specific value in the proposal made below under (3).
In the field of complex record structures two cases should be distinguished. As far as hierarchy-clusters are concerned the conclusion concerning existing data is deceiving: no reasonable effort leading to a substantially improved situations seems possible without major structural alignments both in the German and in the Anglo-American environments. This may lead to constructive proposals under 4.3/4.4, however, for existing databases and data resources, the prerequisite re-conversion efforts seem prohibitive.
The situation is different for clusters built from the combination of title records and linked authority records for persons, corporate bodies and subject headings. The observations made in this field in fact lead to a proposal for a possible continuation activity that would require (large scale) contributions from at least OCLC and GBV/BRZN with the aim of providing substantial building blocks for future language independent authority files including mechanisms for ‘NLS’ (National Language Support), or - to choose a newly invented and maybe more adequate term - ‘CCS’ („Cultural Context Support"). This activity is intended to be performed without human intervention.
The basic observation is the possibility of substantially enhancing the compatibility of core matching elements in the large field of ‘simple’ monograph publications. This would allow GBV - to point out one possible scenario - to integrate Subject Headings (as we already do), together with entries for personal names and corporate bodies from external sources in GBV title records.
This not only results in a substantially enriched database (new access points for OPAC retrieval are created from these external elements increasing recall without harming precision), but moreover the most important result of such an operation would be a stable and reliable context for combined culturally dependent entry forms for the same entities (in many cases at least): co-occurrence in the same bibliographic context (eventually combined with significant string identity and / or lexicon-based mapping) may well be a more reliable basis for creating a starting point for multilingual authority records than mere comparison of strings taken from the respective isolated authority files!
Co-occurring terms could be extracted in a second step and be stored in relational tables using statistical counters for re-occurrence of a given pair/cluster of terms: relations between co-occurring terms would be stabilized according to counter values judged sufficient for establishing solid links between these terms ...
Such methods of statistical clustering combined with linguistic tools for lexical and morpho-syntactical normalization based on term recurrent co-occurrence in bibliographic contexts may be a promising help in attempts for establishing authority records that would afterwards contain culturally dependent entries referring to the same entities, future applications would only have to establish links between bibliographic records and such authority records and pick out the entry form relevant for the application context for retrieval and presentation operations.
One advantage of this approach is its statistical aspect: valid results do not depend on 100% success of matching operations. A significantly high number of successful matches would be completely sufficient to create a reliable context for combining terms in at least something like a proto-authority record.
Another advantage of this approach would be the fact that after the creation of multilingual authority records the subsequent problem of linking existing bibliographic records to these new synthetically clustered authorities could be easily resolved: clustering would only have to preserve the original bibliographic context of each entry in order to obtain back-linking information.
Needless to say, such a concept heavily depends on successfully established common concepts for the entities to be finally referred. This may be relatively easy for persons, it may be a very difficult task as far as corporate bodies are concerned. This aspect of the problem is covered in sections 4.3/4.4 of this report.
The REUSE Project has certainly had an enormous impact on the work of Expert Group RAK (of Deutsches Bibliotheksinstitut). The idea of converging rules and of finding mechanisms for more efficient reuse of each other’s data records was established as one of the major goals for work to be done in the near future the need for this kind of bibliographic convergence was integrated in the current main activity of the Expert Group as one of the leading principles in the ongoing work on RAK for online catalogs.
The Expert Group tried to divide rule and format differences into minor and major problems.
As "minor" problems we consider ISBD and Main Entry Principle:
ISBD
As the name indicates the use of ISBD is comparably standard. The German rules apply ISBD with slight variations. A comparison of ISBDs has already been made by EG RAK, an evaluation has to follow: we will either use the same as AACR2 or define the differences for data exchange. The missing area 3 can hopefully be reproduced (as it is tagged and provided with description signs).
The descriptive notes in ISBD (including introductory wording in the note area) should be acceptable when they are in any of the major European languages.
Main Entry Principle
Librarians and especially catalogers increasingly have to justify their work. A thorough revision of the card catalog philosophy might help to make the cataloger’s work more clear and efficient.
Experience in the Southwest German Library Network is that there is a lot of absolutely useless exchange of online messages, especially concerning the problem of main or added entries. For many librarians the main and added entry principle has already lost its central importance: In OPACs every access point can be chosen for editing and searching, there is no primary or secondary aspect as far as the „classic" access points are concerned.
Lists and indexes can be adapted to any users’ need. As for citing titles the Expert Group RAK has recommended the following:
Major problems
OCLC – GBV – SUB Göttingen
1 Goals and underlying assumptions *
2 Participants and their respective role, organizational structure *
3 Methodological approach *
3.1 Processing of Set1 *
3.2 Processing of Set2 *
3.3 Further investigations *
4 Results *
4.1 Categories *
4.2 Reuse of existing data *
4.2.1 Name authorities *
4.2.2 Corporate bodies / Entries under names for persons and corporate bodies *
4.2.3 Title entries *
4.2.4 Multi-volume publications and other hierarchical structures *
4.2.5 Conclusions from 4.2 *
4.3 Future conditions for more efficient reuse *
4.3.1 Name authorities *
4.3.2 Title entries *
4.3.3 Multi-volume publications and other hierarchical structures *
4.3.4 Romanization *
4.4 REUSE results and possible links to ‘Functional requirements ...’ as a future modeling frame for bibliographic objects *
4.4.1 Some remarks on the possible relevance of the „Functional Requirements ..." study to the REUSE project *
4.4.2 Remark on ‘Metadata’ *
4.4.3 Personal Names *
4.4.4 Multi-part Publications *
5 Relation to other projects *
5.1 BSB *
5.2 USEMARCON (EU) / DDB and JOUVE *
5.3 Workshop on UNIMARC and EU Projects *
5.4 OCLC - National Library of Russia *
5.5 International Conference on the Principles and Future Development of AACR *
6 Concluding remarks *
The overall goal of the reuse project is to contribute to the enhancement of international bibliographic compatibility within the specific working context of German libraries and library networks. The project has been launched by OCLC, GBV/BRZN and SUB Göttingen in January 1996 and was concluded with a final meeting 13th of March 1997 in Dublin / Ohio. A follow-up activity (reuse+) will investigate questions that have not been completely dealt with during the project’s lifetime (namely bibliographic hierarchies).
The present document recapitulates the goals and assumptions agreed upon by the participants in September 1995 (1), lists the participants involved and describes the organizational structure of the project (2), gives a short account of the methodological approach adopted (3), gives an account of the results achieved (4), briefly discusses possible relations with ongoing activities in the field (5) and concludes with a series of general statements / observations that might be taken up again in different contexts. Some of these statements specifically relate to the „Functional requirements of bibliographic records" prepared by an IFLA Study Group.
Two observations originally led to the definition of the goals of reuse:
Two factors usually are held responsible for this situation: incompatibility of the formats for data exchange (MAB vs. USMARC) and incompatibility of the cataloguing rules used in the respective contexts (RAK vs. AACR2).
At the beginning of the project it was assumed, that the incompatibility of the formats used should not be considered a major influencing factor because existing conversion utilities as well as MAB in its new version (MAB2) should allow for a formally sufficient representation of data from the Anglo-American context within German cataloguing systems.
It was suggested therefore that the main obstacle preventing massive reuse of these data resides in the differences between the underlying cataloguing rules (AACR2 resp. RAK-WB). These differences (mainly in the representation of bibliographic hierarchies and the rules for generating and handling of authority information) were supposed to account for the need of heavy manual/intellectual modification of data received from LC, BNB or OCLC when reused in German union-catalogues such as the Pica-System of GBV (Gemeinsamer Bibliotheksverbund) or the Südwestdeutscher Bibliotheksverbund (SWB) by partners like Göttingen State Library or University Library in Heidelberg.
In order to address these issues of formal and semantic incompatibilities two main tasks have been defined for the project (further referred to as WP1 and WP2):
WP1: Systematic identification/description of the main differences in the representation of bibliographic objects according to AACR2 resp. RAK. It was assumed that the crucial areas to be investigated are multi-volume and serial publications as well as the use of authority files. This was to be achieved in comparing sets of data from OCLC and from German partners referring to identical bibliographic entities. Two pairs of data sets have been chosen for this comparison: SET1 consists of records created by SUB Göttingen in the GBV database according to RAK as compared to corresponding records extracted from the OCLC database by the use of an identifying matchkey, SET2 is composed from records created by UB Heidelberg in modifying OCLC title records as compared to the records originally supplied by OCLC in the late eighties. Within both SET1 and SET2, ‘a’ signifies German records and ‘b’ signifies OCLC-records.
WP2: Make a serious attempt to develop algorithmic methods for data conversion which would go beyond methods of basically mechanical tag-mapping and which might result in a significantly higher degree of ‘RAK-conformance’ of data received from OCLC. Ideally, these algorithms should produce results almost identical to SET1a and SET2a in processing the respective b-sample. It was suggested to combine these algorithmic procedures with attempts to build multilingual authority files.
WP 1 and WP2 have been carried out in an interconnected, iterative approach involving documentation activities and the building of prototypes.
Depending on the results of this methodological approach substantial enhancements were expected mainly in two areas:
Positive results from the algorithms implemented in WP2 would lead to the operational routines, which would substantially raise the attractiveness of data such as provided by OCLC on the German market.
Negative results from WP2 should lead GBV and others to seriously question the future justification of a specific German cataloguing policy (RAK). As the project partners are seriously convinced that international bibliographic compatibility will be of increasing -- and prevailing -- importance for German librarians, remaining incompatibilities even after applying the methods to be developed in WP2 should lead to the alignment of cataloguing rules as the only alternative available. Not everybody in Germany is aware, however, that the AACR2 rules do not "tell the whole story" about the content of USMARC records: the LC Rule Interpretations have to be taken into account as well, and these are even more voluminous.
The steering committee was composed of Monika Münnich (chairman of Germany’s Expert Group RAK [EG-RAK] at the Deutsches Bibliotheksinstitut), David Buckle (subsequently replaced, after his retirement, by Janet Mitchell) and Glenn Patton (OCLC), Barbara Tillett (LC, acting as an advisor for OCLC in the project), Cornelia Katz (Bibliotheksservicezentrum Konstanz), Bernhard Eversberg (University Library of Braunschweig), Elmar Mittler (SUB Göttingen) and Stefan Gradmann (GBV/BRZN).
The project has been entirely funded by OCLC.
Staff of GBV/BRZN (with substantial help from OCLC) has carried out the core work on WP2 and WP1; Bernhard Eversberg, Monika Münnich and Barbara Tillett supplied major contributions with respect to the differing cataloguing rules and data models. Monika Münnich integrated important comments from members of EG-RAK.
Furthermore, a number of persons were actively involved in work related to the project at different stages without formally being part of the project group. Contributions were received from Claudia Fabian (Bayerische Staatasbibliothek, München, and member of EG-RAK), Emma Lee Yu (City University of New York), Jürgen Braun (GBV/BRZN), Michael Rzehak (GBV/BRZN) and Feruzan Akdogan (GBV/BRZN).
SET 1a contains 16.380 records in PICA+-format. A file containing the corresponding matchkeys had been sent to OCLC and as a result 9.159 (55,92% of SET1a) records representing exact matches in OCLC’s database were returned to GBV/BRZN in MARC-format. GBV/BRZN did carry out some (limited) investigation concerning the more than 7.000 records that were not matched or that led to ambiguous results. As a result from these investigations three general remarks can be made concerning the impressive number of unmatched records / ambiguous results:
Some of the many unmatched records would probably have found a counterpart if the process of gathering candidates in the OCLC-database would have been repeated with - either - a refined and adapted matchkey definition (although the key used in the tapecon-procedure is fairly elaborate already) or combined with a suitable pre-processing of source tag contents that were the basis for building the matchkeys. The findings mentioned further down under 4.2 might provide elements for both (matchkey refinement and contents preprocessing) -- still we do not expect dramatically improved results from such an attempt.
The high number of ambiguous results (2 or more hits) is a significant result in itself as it is probably due to structural discrepancies between the underlying data models. A main entry for a multi-volume publication issued from the German context (and combined with numerous analytical records for the individual volumes in the GBV-database) did in many cases meet a ‘flat’ representation of the same entities in the OCLC-database (i. e. many volume records each containing the same ‘main title’ tag, and this typically results in a 1-n relation).
Finally -- and as a result of this last remark -- the results from the subsequent processing of the actual pairs retained have to be interpreted cautiously: these basic sets already exclude the whole range of structurally divergent entities and thus suggest a higher degree of matching precision in the multi-volume-area than can actually be achieved!
Two assumptions have been made before processing these records. German partners in reuse came from different library networks (Gemeinsamer Bibliotheksverbund / GBV, Südwestdeutscher Bibliotheksverbund / SWB) using proprietary data structures and formats as well as proprietary conversion routines as a consequence. The only generic data format transcending these different contexts is MAB2. The only available non-proprietary conversion tool that all the partners are more or less familiar with is allegro C. It was thus decided to convert both subsets to MAB2 using allegro C in order to obtain comparable subsets.
Two databases have been built from these subsets whose contents are linked on record level (where possible): it is thus possible to do intellectual ad-hoc-comparisons of records originated from GBV and from OCLC in a very comfortable way. Besides, two databases in the respective source-formats (PICA+/USMARC) have been built which allow the inspection of the original, unmodified records. These databases were the core working-tool for the project and can be inspected via Internet (Telnet to 134.169.20.3, login as ‘opac’ with password ‘opac’ and then select ‘reuse’ option). In order to deal with minor incompatibilities of MAB and MARC some non-standard additions to MAB have been defined. These extensions are clearly identifiable using an additional extension of MAB tag-indicators.
For the creation of SET2 MAB records had been supplied by SWB and did not present major problems for processing. The next task was to extract the corresponding, unmodified records from the OCLC database. The records supplied by SWB still contained OCLC’s identifying number in MAB tag 572. A TAPECON file containing this ID-number instead of a matchkey therefore was prepared by GBV/BRZN and sent to OCLC. The resulting file supplied by OCLC was processed using the same conversion procedures as used for SET 1 and two databases for comparison were created analogously to the processing of SET 1.
Processing of SET 2 has been given less attention in favor of SET1 for several reasons:
SET2 was much easier to process (SWB had provided MAB-records already, no new conversion routines will have to be defined for the corresponding subset received from OCLC; retrieval of the corresponding set by OCLC was not a major problem due to the presence of the original ID-numbers)
Results from the comparison of the SET 2-subsets were expected to be less clear and maybe difficult to determine, because it was impossible to reconstruct one important intermediary stage: SET 2-records had been delivered by OCLC in MARC-format and converted by DDB to MAB1 before handing the records over to SWB, where a second conversion was done before integrating the records in the SWB-database. As the result of intermediary conversions, data is definitely lost and it often is impossible to pinpoint who or which agency was the instance responsible for changes to the records.
As far as structural differences between the respective data models in the crucial field of multi-volume publications are concerned SET 2 is close to insignificant: 7138 out of the 7379 records supplied by SWB in fact are records of MAB type ‘h’ (main records), 218 are of type ‘n’ and only seven of the records originally supplied by OCLC have been transformed into ‘type u’ records (analytical records for parts of multi-volume publications). It is thus evident that the records supplied to SWB by OCLC have been used systematically and almost exclusively for the generation of catalog records for ‘simple’ monograph publications (isolated or with a series statement). This was logical in the original cataloguing context: librarians did use only those records that could be integrated in the German catalogue environment without major structural changes - although quite some work was necessary to establish links to German authority records - and thus did their job efficiently. Still this seriously affects the significance of SET 2 in the reuse context: major problematic cases were systematically excluded in this approach.
Finally, one should bear in mind, that SET2 reflects the situation of the late 1980s and thus may partly be of historical interest only, because RAK rules have changed since then.
Following the steering group meeting in June 1996, the databases for comparative work resulting from the first processing of SET 1 and SET 2 were installed at the partner sites working on WP1.1 by GBV/BRZN, extensive printable listings asked for by these partners were supplied by BRZN as well.
Processing of both sets has subsequently been refined by GBV/BRZN with a focus on basic structural differences on record level (presence / absence of fields in the respective records, identity / non-identity of field contents), structural and semantic differences on field level (identity / non-identity of field contents further analyzed: identical substrings, typically differing substrings?) and on complex differences (partly) reaching beyond record level (multi-record structures vs. flat representations of bibliographical hierarchies) and thus to cover the categories 4 and 5 (also mentioned under section 4).
Monika Münnich, Barbara Tillett and Glenn Patton carried out parallel investigations concerning these focal points; their comments were integrated in the refinement of the set processing by GBV/BRZN.
The final report was drafted by GBV/BRZN together with Monika Münnich and Barbara Tillett in January/February 1997; the other members of the project group supplied valuable comments to this final document in the last stage of the drafting process.
The following presentation of the overall project results does not attempt to give a detailed account of all observations made during analysis of the reuse corpus but tries to sum up and synthesize these results.
Generally, the following two areas should be distinguished in this respect:
Furthermore, five distinct categories for further investigation had been defined in the June 1996 steering group meeting. Accordingly, this overview is organized along these categories within the sections 4.2, 4.3 and 4.4. The five focal points for further analysis of representation differences are given below together with some general comments.
Name authorities: Although no authority records were delivered for persons/personal names it seems possible to generate brief authority records from the OCLC-file, these authority records could subsequently be mapped to those present in the GBV-database. Parallel activities are currently carried out in Germany for systematic comparison of the respective authority files on a national level (PND vs. Name Authorities, Die Deutsche Bibliothek is cooperating with LC in this field in the CoCat-project). It was decided to link project work to these external activities as much as possible but at the same time to compare name entries in the two sets (the relation that can be established between the differing name entries via the common context of the bibliographical entity may serve as a valuable complement for systematic comparison of authority files). The overall aim in this field was to contribute to the building of a conceptual framework for multilingual authority files for personal names.
Corporate bodies: The situation is fairly more complex for names of corporate bodies. Although it is technically possible to generate authority records from the OCLC-file the mapping of these to records of the German GKD (National Database for Corporate Authorities) seems to make little sense due to the fundamental semantic differences in the respective concepts of what is considered a corporate body (meeting-entries/Konferenzen are a particular problem in this field). Still, some systematic comparison work was done on the respective corporate entries in the two file sets mainly based on automated mapping routines provided by GBV/BRZN. Work in this field was linked to ongoing activities in Germany, too (project carried out by Ms. Hoffmann at HBZ/Cologne). A working group of EG RAK has been set up that is mainly analyzing examples taken from GKD and the corresponding entities (that were retrieved from the ‘Name Authorities’ File by LC).
Title entries: Special attention was given to the comparative analysis of title entries in the record sets. All relevant tag contents were be indexed by GBV/BRZN and printable lists containing entry pairs were provided to help the partners involved in this work.
Multi-volume publications: At least two different representations strategies can be distinguished in the OCLC-file (one record per volume with volume-titles in MARC 245 + title of MV-publication vs. one record for MV-publication containing volumes in MARC 505/contents note). The same general structural discrepancy can be observed for contained items. In both cases the mapping to multi-volume data structures as they are commonly used in German databases was expected to be possible and was seriously attempted subsequently. Mechanisms for the mechanical mapping of such structures provided by GBV/BRZN should be the basis for further analysis by the other partners leading to recommendations for refined algorithms to be re-implemented by GBV/BRZN.
Other hierarchical structures: It was decided to systematically investigate the possibility of mapping the structures used for contained/added items (MARC 245 / Contents note vs. multi-record representations) and for items linked to series information.
Work on multi-volume and other hierarchical structures is of specific interest not only for the German context: LC is very interested in making use of bibliographic data issued from Germany. Although reuse is clearly focused on transfer of MARC-data to Germany, this aspect of project work should provide elements for improving data transfer in the opposite direction.
The observations presented in the following section are derived mainly from the processing of SET 1 and subsequent statistical analyses. No fundamentally divergent observations have been made in processing SET 2, and the various reasons given above under 3.3 led us to the assumption, that observations drawn from SET 2 should be given a very limited significance, anyway.
Assessment of the perspectives for reuse of existing catalog data should be done with a clear notion of the relevant working context, i. e. bearing in mind what these records could typically be used for: catalog conversion, reconversion and upgrading of existing databases are expected to be the relevant activities in this respect rather than current cataloguing of newly acquired material (this latter activity will be covered by the 4.3 section of this report). Section 4.2.5 (‘Conclusions from 4.2’) attempts to set out some of the perspectives, that can be derived from the analytical work provided by GBV/BRZN in this sense.
9.013 Name entries contained in the OCLC-records as part of SET1-pairs have been checked against the respective entries contained in PICA-records. Five different levels of similarity are distinguished in the table below:
A further distinction is made between levels of similarity for ‘First Author’ tags (MAB100) vs. ‘Other Persons’ in MAB104 etc.
The main differences typically encountered among the 2.094 differing entry forms are:
OCLC typically contains more entries in the case of several contributors (RAK limits entries to the first editor / contributor in such cases)
Different handling of Anglo-American compound surname (e. g. Sparck Jones, Karen vs. Jones, Karen Sparck)
The following section is based on the statistical data as given in the annex. Out of 657 corporate bodies in MAB200 only 88 were identical, differing forms were found in 270 cases, in 299 cases no counterpart was found for a corporate body present in the OCLC record.
As far as the actual differences between the corresponding entries are concerned, the remarks in 4.2.1.2 are valid also for the differing forms in SET1; the reader is thus referred to this section.
In order to explain some of the - far more intriguing - cases of structural difference (non-correspondent entities) the following remarks on principles for the creation of entries are given. They apply both to names of persons and those of corporate bodies (these should be considered in a common context in this case) and mostly refer to RAK rules §§ 6XX. According to the general remarks on entries (cf. below under 4.3), no difference is made between main and added entries. Furthermore, no rules for special material types (such as non-book materials or cartographic material) are taken into account.
GBV/BRZN exclusively concentrated on the main title entry (MAB331) as the central identifying element and the key factor for matching operations (cf. below under 4.2.5).
Results (as shown in the annex) are encouraging: there are no major rule dependent differences between the respective entries, the degree of matching is high (81.03%) even when comparing ‘raw’ title strings. Differences occur mainly as a result of misspellings, different spelling conventions (e. g. ss vs. ß) and differing transliteration conventions. These differences can efficiently be resolved using simple and comparatively robust normalization routines. This results in a significantly increased identity factor (93.11%) in the second pass. The remaining differences are due to remaining transliteration effects and mainly to different interpretations of what is to be considered an addition to the main title (MAB331 vs. MAB335).
Both focal points are presented together in this paragraph, because one of the main lessons to be learned from this part of our work is, that the distinction currently made in the German environment is not applicable to the data originated from the Anglo-American context.
The following three main models for the representation of hierarchical bibliographic structures were found in the sets processed by BRZN:
or
Linking structures complying to the data models currently used in German applications might eventually be derived from model b). Decomposition of MARC 505 is a very complex task (close to impossible, the distinction between intellectual and physical volumes as part of this tag is not algorithmically possible). Moreover, the criteria for use of either of these models in the OCLC database (and in U.S. cataloging practice in general) have varied over time. Decisions on creation of a single record for a multi-volume work versus individual records tied together with series entries (4XX and/or 8XX fields) have been made based on local needs (we recognize another structure for in-analytics with 7XX added entries is possible, but we did not encounter examples in our test sets). The use of complex contents notes in field 505 has increased as libraries have moved into online catalogs which have provided indexing for those fields and which have removed some of the difficulty of maintaining contents notes that existed in card catalogs.
The possible use of yet another modeling approach involving the use of MARC field 774 for downward linking has been discussed without decisive results, this discussion is meant to be finished in the frame of reuse+.
A potentially viable strategy of consistently mapping these conflicting models to a common target model in record conversion would require a radical decision in the German target environment: giving up of the distinction between MV-works and monographs as parts of serial publications (and using a uniform linking structure in both cases), eventually even replacing the ID-numbers used as pointers to authority records today with textual links, all this together with a complete re-conversion of existing databases for cooperative cataloguing and re-conversion of their local derivatives (OPAC systems, circulation control applications etc.)
And even such a decision probably would lead to an unsatisfactory situation: due to the differing and sometimes conflicting representation models used in the Anglo-American source files the application needed for the subsequent record conversion would have to be a full grown AI-application ...
If one considers the conditions for reuse of existing data as briefly discussed at the beginning of this chapter it is evident, that the efforts necessary for the creation of such a (highly experimental) scenario together with the subsequent complications and risks for existing databases (and applications tailored to these structures) largely exceed the eventual profit to be expected from such an activity, as far as multi-volume publications are concerned.
Three general conclusions should be retained from our work on the two sets.
It is possible to efficiently enhance bibliographic compatibility as long as records are structurally compatible (this is typically the case with monographs). This can be illustrated by a diagram derived from statistical analysis of SET1. This set has been processed twice and an attempt has been made to enhance the degree of identity for the contents of tags highly present in both subsets. Relatively simple normalization routines have been used in these cases. As the combination of high overall frequency together with high similarity of contents was considered to be significant in the sense of identifying relevance of a given tag each tag has been attributed a ‘matching relevance’ factor ([(occurrence*10+identity*5) / 15.37] in order to match 100% for ‘main title’). This relevance factor has been significantly increased for a core set of tags from pass 1 to pass 2 as shown in the following diagram:
Thus, for ‘simple’ monograph publications not only can the degree of ‘reusability’ efficiently be enhanced but - and this is most important for conclusion (3) below - this can be done concentrating on five identifying elements highly relevant for matching operations
These five elements may be considered the core matching elements with regard to the proposal made in conclusion (3) below. Even if ‘first author’ / MAB100 has a comparable matching relevance and thus one could think of including this field in the ‘matching core’ such a decision would probably have unwanted systematic effects: the five elements retained here present the advantage of containing no linked information and can be treated independently without having to deal with the more complex data structures related to authority records. This possibility of establishing robust matching operations that are relatively simple to administrate will reveal its specific value in the proposal made below under (3).
In the field of complex record structures two cases should be distinguished. As far as hierarchy-clusters are concerned the conclusion concerning existing data is deceiving: no reasonable effort leading to a substantially improved situations seems possible without major structural alignments both in the German and in the Anglo-American environments. This may lead to constructive proposals under 4.3/4.4, however, for existing databases and data resources, the prerequisite re-conversion efforts seem prohibitive.
The situation is different for clusters built from the combination of title records and linked authority records for persons, corporate bodies and subject headings. The observations made in this field in fact lead to a proposal for a possible continuation activity that would require (large scale) contributions from at least OCLC and GBV/BRZN with the aim of providing substantial building blocks for future language independent authority files including mechanisms for ‘NLS’ (National Language Support), or - to choose a newly invented and maybe more adequate term - ‘CCS’ („Cultural Context Support"). This activity is intended to be performed without human intervention.
The basic observation is the possibility of substantially enhancing the compatibility of core matching elements in the large field of ‘simple’ monograph publications. This would allow GBV - to point out one possible scenario - to integrate Subject Headings (as we already do), together with entries for personal names and corporate bodies from external sources in GBV title records.
This not only results in a substantially enriched database (new access points for OPAC retrieval are created from these external elements increasing recall without harming precision), but moreover the most important result of such an operation would be a stable and reliable context for combined culturally dependent entry forms for the same entities (in many cases at least): co-occurrence in the same bibliographic context (eventually combined with significant string identity and / or lexicon-based mapping) may well be a more reliable basis for creating a starting point for multilingual authority records than mere comparison of strings taken from the respective isolated authority files!
Co-occurring terms could be extracted in a second step and be stored in relational tables using statistical counters for re-occurrence of a given pair/cluster of terms: relations between co-occurring terms would be stabilized according to counter values judged sufficient for establishing solid links between these terms ...
Such methods of statistical clustering combined with linguistic tools for lexical and morpho-syntactical normalization based on term recurrent co-occurrence in bibliographic contexts may be a promising help in attempts for establishing authority records that would afterwards contain culturally dependent entries referring to the same entities, future applications would only have to establish links between bibliographic records and such authority records and pick out the entry form relevant for the application context for retrieval and presentation operations.
One advantage of this approach is its statistical aspect: valid results do not depend on 100% success of matching operations. A significantly high number of successful matches would be completely sufficient to create a reliable context for combining terms in at least something like a proto-authority record.
Another advantage of this approach would be the fact that after the creation of multilingual authority records the subsequent problem of linking existing bibliographic records to these new synthetically clustered authorities could be easily resolved: clustering would only have to preserve the original bibliographic context of each entry in order to obtain back-linking information.
Needless to say, such a concept heavily depends on successfully established common concepts for the entities to be finally referred. This may be relatively easy for persons, it may be a very difficult task as far as corporate bodies are concerned. This aspect of the problem is covered in sections 4.3/4.4 of this report.
The REUSE Project has certainly had an enormous impact on the work of Expert Group RAK (of Deutsches Bibliotheksinstitut). The idea of converging rules and of finding mechanisms for more efficient reuse of each other’s data records was established as one of the major goals for work to be done in the near future the need for this kind of bibliographic convergence was integrated in the current main activity of the Expert Group as one of the leading principles in the ongoing work on RAK for online catalogs.
The Expert Group tried to divide rule and format differences into minor and major problems.
As "minor" problems we consider ISBD and Main Entry Principle:
ISBD
As the name indicates the use of ISBD is comparably standard. The German rules apply ISBD with slight variations. A comparison of ISBDs has already been made by EG RAK, an evaluation has to follow: we will either use the same as AACR2 or define the differences for data exchange. The missing area 3 can hopefully be reproduced (as it is tagged and provided with description signs).
The descriptive notes in ISBD (including introductory wording in the note area) should be acceptable when they are in any of the major European languages.
Main Entry Principle
Librarians and especially catalogers increasingly have to justify their work. A thorough revision of the card catalog philosophy might help to make the cataloger’s work more clear and efficient.
Experience in the Southwest German Library Network is that there is a lot of absolutely useless exchange of online messages, especially concerning the problem of main or added entries. For many librarians the main and added entry principle has already lost its central importance: In OPACs every access point can be chosen for editing and searching, there is no primary or secondary aspect as far as the „classic" access points are concerned.
Lists and indexes can be adapted to any users’ need. As for citing titles the Expert Group RAK has recommended the following:
Major problems that severely impede data exchange (and thus dealt with in detail in the following paragraphs) are
The Expert Group RAK has been working especially on name authorities and title entries. As the organization of German rule making groups is going to be revised the decisions of EG RAK are only proposals. They will be presented to the German „Rule Conferences" which are expected to decide on the principles of future rules. The major issue - here again - will be data exchange with the Anglo-American library world.
If German librarians really want data exchange the goal has to be participation in AAAF, LC’s NACO Program, or perhaps an international authority file (IAF). This future file should allow national headings for each participating country. Thus every library community can maintain their used heading. The only problem is agreeing on the distinctive entities to be matched.
4.3.1.1 Names for persons
As for name headings the German rules have to be changed in the area of differentiation. Except for ancient and medieval names, names of rulers and nobility and names for subject headings there is no addition provided in RAK for identical names so far.
Another rule that influenced also title entries has been revised (as proposal for the Rule Conference): prefixes preceding a family name will be entered as they occur on the item. So far they have been entered as one filing word (in both name and title entries).
4.3.1.2 Names for corporate bodies
In order to reach the same number of entities the names of corporate bodies had to be examined thoroughly. Colleagues of the Library of Congress checked every example of RAK corporate bodies with LC Name Authorities. A small working group of Hochschulbibliothekszentrum (North-Rhine-Westphalia Library Network) and Südwestverbund (Southwestern Library Network) analyzed the compared examples.
Monika Münnich made a working translation of RAK rules §§ 400 (with the help of Glenn Patton). This version is supposed to help in the discussion of creating the same number of entities.
The following is an overview of the main differences as far as entities are concerned:
The Rule Conference again has to agree to the convergence and possible participation in IAF. Organizing the participation will be the next step.
In the title area EG RAK has done substantial work.
Collection (two and more works by one author = Sammlung). EG RAK has „pre-decided" that the term „Sammlung" will be coded in RAK2. The code can be exchanged as collective title, though without distinguishing between complete works, selections and works in a single form. The language will be coded as well and thus be exchangeable.
Title proper (Hauptsachtitel). The title proper in RAK-WB is manipulated, that is, the title in many cases is not entered as it appears in the item. Especially signs as hyphens, slashes and other marks are handled in a different way in RAK than in AACR2. RAK has introduced the following regulations in order to provide filing words or sequences, e.g.:
The former rule to add the full form of an abbreviated term has been replaced by the form as it occurs in the item.
During the last two conferences of EG RAK (June and November 1996) major steps towards convergence were reached by tendency voting (awaiting final agreement of the German „Rule Conference"):
This way the title proper will be very close to AACR. The compound regulation is a grammar question in the German language, so this had to be regulated.
Title proper as heading (Ansetzungssachtitel). In addition to title proper German rules provide a so called "Ansetzungssachtitel" (AST) - the form of the title proper that is used for heading or rather filing. The main rule says: volume statements at the beginning, within or at the end of a title will not be entered as part of the title. The declination has to be altered if necessary. Any names of authors are ignored when occurring at the beginning or end of the title., e.g.:
Furthermore, the Ansetzungssachtitel is used for subseries, e.g. Cataloging news / A (any further terms are left off).
The AST title proper as separate (primary) heading will be dropped. Additional access titles or key words for some parts of the "former" Ansetzungssachtitel are discussed for string search. As far as subseries are concerned the additional filing title is really desirable.
Most of the existing records (within Germany) will be automatically transferred (so far the main entry was made under or with Ansetzungssachtitel.) As for data exchange to the Anglo-American library world, the additional AST could easily be dropped.
Form titles (part of uniform titles in AACR). Form titles as Festschrift, Vertrag (treaty) and Verfassung (constitution) should not be a problem as they can be coded and easily exchanged.
There are different kinds of hierarchical structures in the German MAB format (Maschinelles Austauschform für Bibliotheken). Most of them are applied throughout the German regional networks. The structures are not necessarily different due to rule variations of AACR2 and RAK. RAK does not mention a set structure at all (unlike AACR). The format designers have decided for or against hierarchical set structure.
Parts of a multi-volume work are entered as separate records if there is a part title or volume statement with the following structure:
Holding records are added to all of the described bibliographic records in the regional networks. They are transferred to the local systems. Some of the local systems add item records (without bibliographical designations) in their systems.
The big difference of handling the volumes seems to be that in Germany they are part of the bibliographical record. In the US the work of establishing item records for individual volumes is done locally (for circulation and inventory control) -- in local systems, while in German library networks, the work is done only once for all local libraries.
Except for informational discussions EG RAK so far has not been working on solutions for multi-volume works. Results of this project will certainly be a basis for further work.
The use of UNICODE is a mutual goal for the future. LC is exploring enhancement of the USMARC format in order to accommodate field-level information about language, script, script direction, transliteration scheme and original characters in addition to romanized forms. A similar solution should be considered seriously by MAB-Ausschuß.
One of the global observations in REUSE was that some of the most striking structural discrepancies are not caused (in a strict sense) by the respective cataloguing rules (or formats). Any attempt to deal with such differences in the sense of differing logical data models would require a Common Object Model and a Common Functional Model (in a technical sense) for bibliographic entities (i. e. something cataloguing rules and data formats were not made for). Even if the difficult task of defining such a model is further complicated by the troubling internal inconsistencies of all bibliographic databases it was felt that it should be one major goal of the project to contribute to the establishment of such a model. „Functional requirements of bibliographic records" prepared by an IFLA Study Group was supposed to be one of the most relevant document in this field and it was decided to make this study the point of reference for this aspect of REUSE.
The following section thus attempts to give a comment on the "Functional Requirements" document with specific respect to the basic question, whether the approach chosen therein might help to overcome the conceptual inconsistencies underlying the differing / conflicting data models that are fundamentally responsible for some of the crucial bibliographic incompatibilities.
One might hope to find in this study a fresh approach at a functionally oriented new design of library data structures. The "entity analysis technique" is being employed to develop an entity-relationship model of bibliographic data, focusing first on the objects that need to be described and accessed in a library, then looking at the tasks users need to fulfill, and derive from these a list of elements that have to be included in records. Very early in the study (in the first paragraph of 2.3), however, the authors state expressly that "... the study is not intended to serve directly as a basis for the design of bibliographic databases ...". However, the entity-relationship model developed in section 3 could well serve well as the basis for this kind of design. Of course, the library world does not seem to be ready to embrace new models of bibliographic data if implementation would also mean new costs, not just for software but also for retraining. Even minor changes seem impossible to implement as can be learned from discussions in such lists as AUTOCAT or USMARC.
However, the study thus is a valuable terminological and conceptual framework in the context of a descriptive approach: it does not attempt to „create a fully developed conceptual data model" (and this has never been the task of the working group). The development of such a model, together with proposals for the „re-assessment of bibliographic standards and data recording conventions" is part of section 1.3 („Areas for further study"), and most parts of this short section read like a generic version of what was intended to do when starting reuse. The study thus not only does not solve one of the fundamental problems encountered in our project: it does not even indicate which working context could generate such a (partly prescriptive!) model.
Without the aforementioned constraints in mind, it is very clear that the entity-relationship model would call for both a reorientation of cataloging rules and a new format design. Rules must become work-oriented rather than manifestation-centered as they are now (both AACR2 and RAK). Interestingly, this becomes even more obvious when dealing with online "documents", where expressions (versions) can proliferate more rapidly than ever before. New types of records must be defined for works and expressions, and true linking techniques must be developed. Currently, links do not exist in USMARC records (not beyond what is called the "textual link", which is not reliable enough). They do exist in UNIMARC and in German MAB records, though UNIMARC and MAB do not have records for works or expressions either but just for manifestations, like USMARC.
In terms of the study, what does a current MARC or MAB record actually stand for? It contains elements of all four entity-levels, the focus being clearly on the manifestation, which is the piece in hand (as the very word "manifestation" expresses). The well-known difficulties in satisfying Cutter's "objects" (or the "Basic level of functionality") result more or less from this fact: Not enough attention is given to a coherent representation of works and expressions.
It is very difficult indeed to envision a new model for data exchange and copy cataloging, were we to define additional records for works and expressions. For example, would it mean we had to exchange three records every time we cataloged a new manifestation?
We are convinced, that the dominating role of manifestation-oriented elements has been one of the major factors for bibliographic incompatibilities in the past - had there been a prominent and well established notion of ‘work’ as a fundamental entity some systematic inconsistencies probably would never have been created.
The problem is most evident in the field of electronic publications (or even more in the case of works published in printed and machine-readable form simultaneously): the dynamically proliferating instances of something vaguely felt to be an identical point of reference - the ‘work’ - urgently call for means to differentiate a ‘version’ from an ‘edition’, a copy record from an entry relating to a (slightly?) modified replication etc. Some basic modeling principles are needed in this field and could possibly ‘stabilized’ around the ‘work’ entity - if only this notion were well established ...
It should be noted in this context, that the current ‘metadata’-discussion is purely restricted to the field of electronic documents (without good reasons) and suffers partly from being over-pragmatic in that it completely eclipses the question of common data models for different instances of a ‘work’, instead, electronic documents are discussed as if they had basically no relation to their counterparts in the world of conventional publication. The elementary problem of replication, replication status and replication control is treated insufficiently in such models as a consequence.
But even if we go on producing records based on manifestations, work in at least two major problem areas might be substantially improved.
Problems with name forms As long as a record describes a manifestation of one expression of one work, the difficulties are minor ones. Problems occur mostly where two or more expressions exist. The uniform title field would give us the name of the original work, the author's name is the established authority form in all cases. For libraries (like the German ones) not using AACR, both uniform title and personal name form can differ from their conventions. Especially, if the form of name appearing on the piece differs from the AACR2 established heading, we may have difficulty matching the record (by author-title search key, for example) because the MARC records will give the title page form in the Statement of Responsibility only, not as a reference form in a 700 field. MAB bibliographic records normally do carry the reference forms of the name as well, unlike USMARC records, where such information is provided once in the authority record.
The MARC record in no case contains variant forms of the name as explicit access points. This means in order to get the full picture, we would have to extract additional information from the LC Name Authorities. This is not being done at present, though doable.
More frequently, and more acutely, we run into trouble with multi-part manifestations of works (older and very inaccurate term: multi-volume works) and with manifestations that have component parts being manifestations of works in their own right. The best (or rather worst) examples can be found in the field of music cataloging, but also with collected works of an author. Very clearly, the manifestation is given far too much weight here. Especially in music recordings and printed music, the title and arrangement given and done by the publisher is of very little interest for the patron looking for a particular piece. Yet the title on the physical embodiment of the compilation receives a prominent position in 245, all other titles relegated to the 505 (searchable by keyword if at all), and author/title combinations given in 700 fields (with $t subfields). As a consequence of current practice, i.e. treating a mere container like a "work", information belonging together is thus scattered into two or more unrelated fields. The individual titles proper will be in the USMARC field 505 (contents note), while the authorized, controlled forms of names and titles are in the 7XXs and 1XXs. Names of performers, conductors, translators, and other related persons and corporate bodies are in additional 7XXs. The entity-relationship model developed by IFLA has made the inadequacy of USMARC records in this area glaringly obvious.
This observation does indeed give very little reason for hope to achieve more than the most minor improvements in communication formats in the near future.
The Bayerische Staatsbibliothek intends to launch a project, which will be complementary in scope and results. It proposes to study the effects that merging records of various origins and produced according to different rules into one database may have on the users of that database. Are there differences, which lead to difficulties in retrieving or identifying records? What causes these problems: rules, cataloguing practice, standardization, transliteration, format? What is the impact of these problems compared to the benefit of using records? The project has not yet started.
USEMARCON (EU, FPIII-project) has goals similar to our project (cf. information under http://www2.echo.lu/libraries/en/projects/usemarc.html). Die Deutsche Bibliothek is participating in the project, but the attempts made by GBV/BRZN to obtain some information about the project via DDB have been unsuccessful so far. - Jouve, a French company specialized in catalog-reconversion and data-conversion, is acting as developing partner for USEMARCON. Ms. Lupovici from Jouve did pay visit to GBV/BRZN (11 October 1996) and discussed USEMARCON and possible relations to reuse with Stefan Gradmann. As a result it is evident, that reuse would not profit very much from intensified contacts with USEMARCON: apart from the development of a user driven conversion tool (that does not solve any problems of bibliographic compatibility as it is basically a technical tool) the project has encountered some of the problems addressed in reuse without, however, producing any results that would go beyond the elements presented in this report.
Some of the problems addressed in reuse have been discussed at the Workshop on UNIMARC and EU projects organized by EC/DGXIII (13 September 1996). The proceedings published by EC in December 1996 contain information on USEMARCON, two relevant CoBRA-initiatives (UNIMARC and AUTHOR) and OCLC UNIMARC development. However, the major problems specifically encountered in reuse have not been dealt with in this workshop: some of these problems were irrelevant in the workshop context (such as specific 'German' issues connected to multi-record structures), and others probably would have transgressed the scope of the workshop (such as the question of data model compliance).
OCLC is working with the National Library of Russia in St. Petersburg to examine ways in which Russian and Anglo-American cataloging practices might be harmonized. Following an initial meeting in April 1996, staff at the National Library has translated portions of AACR2 into Russian to facilitate comparison of the two sets of rules. They have now prepared a list of differences with suggestions for resolving them, either by aligning the Russian rules more closely with the ISBD (G) (and, thus, with AACR2) or by amending AACR2. The results of the REUSE project will be shared with the National Library and with other Russian colleagues.
In October 1997, the Joint Steering Committee for the Revision of AACR2 (JSC) will sponsor an invitational conference at the University of Toronto, Toronto, Canada. The conference will "review the underlying principles of AACR, with a view to determining whether fundamental rule revision is appropriate and feasible and, if so, advising on the direction and nature of those revisions." A number of the issues raised in the REUSE project (including the IFLA Functional Requirements document, questions of bibliographic relationships, variations in main entry and corporate entry practices, etc.) will be part of the agenda for this conference. Several participants in the REUSE project are among those invited to participate.
We find the cooperative work on this project has led to an increased appreciation of the possibilities and complications inherent in the international reuse of bibliographic records. In this field, semantic, syntactic and structural aspects are blended in complex problems that can in turn be situated on the levels of cataloguing rules, transport formats and data models. Participants feel that all efforts for the enhancement of international bibliographic compatibility might profit from the appreciation of the complex questions implied by different scenarios for data reuse: attempts for solving compatibility problems will always be substantially deficient when they focus exclusively on isolated aspects / levels of the cluster of problems that have only been tentatively addressed in the reuse-project.
All participants in the project agree, that there is a strong need for further investigations and continuation of some of the activities started as part of reuse and hope, that there will be a suitable context for such continued collaboration.
As one result of our work we propose, that a certain number of actions should be taken immediately in Germany in order to improve conditions for data reuse:
Active participation of German libraries and library networks in work on International Authority Files should be prepared immediately by DDB and DBI. The first step in this sense would be to match German authority records against LC authority records in order to insert LC record numbers in GKD and PND.
In current cataloguing practice, the differentiating of personal names should be mandatory whenever this is needed.
In the field of corporate bodies, the overall goal should be to make parallel types of corporate bodies (entities). One major change resulting from this principle would mean that German cataloguing rules would have to introduce corporate headings for the conferences of corporate bodies according to AACR. Headings in RAK need not be changed in the context of work on International Authority Files.
The collection (‘Sammlung’) and the form titles as well as the languages should be coded according to an international standard. MAB-Ausschuß should be asked to prepare a draft proposal for international standardization.
Multi-Volume Works
The project participants feel that more work is necessary to resolve differences in the treatment of multi-volume works. This work will be carried out over the next few months in ‘reuse+’.
As a first step multi-level hierarchies (as ‘Abteilungen’) should be abolished.
Romanization
The use of UNICODE is a mutual goal for the future. LC is exploring enhancement of the USMARC format in order to accommodate field-level information about language, script and transliteration scheme. A similar solution should be considered seriously by MAB-Ausschuß.
As a major step toward improving international bibliographic cooperation, the Toronto Conference will be held in October 1997. The Reuse group is sure that the above proposals will not be in contradiction to the conference results but instead will improve international cooperation. Actions should therefore be taken immediately.
Bernhard Eversberg
Stefan Gradmann
Janet Mitchell
Elmar Mittler
Monika Münnich
Glenn Patton
Barbara Tillett