




Table of Contents
Editors' Note
In the last two issues of RLG DigiNews, we included a two-part response to an FAQ on publications covering digital preservation. We interpreted this question broadly, providing information on sources that covered both the use of the technology to create digital versions of paper- and film-based source documents, and efforts to prolong the life of digital objects. We will continue to bring you relevant information on both issues as well as on issues affecting access to digital material, believing, as does RLG and the Council on Library and Information Resources, that preservation and access are intricately entwined in the digital world. Future issues will cover a range of topics from the use of digital imaging in preservation reformatting, to enhancing the use and utility of digital objects, to efforts to preserve those objects for long-term use. We will distinguish between digital preservation and digital archiving, reserving the latter term for initiatives undertaken by those with a mandated responsibility to maintain digital information for legal, fiscal, evidential, or historical purposes.
You will find this issue has a strong technical focus, including an article on emerging schemes for persistently identifying digital objects, and one on a promising new file format. From issue to issue, we will strive to provide a balance between the theoretical and the technical, with a heavy emphasis on practical and relevant projects. Within this context, we invite our readers to suggest topics that they would like to see addressed in future issues.
Feature Articles
Persistent Identifiers on the Digital Terrain
Sandra Payette
Digital Library Research Group, Department of Computer Science,
Cornell University
payette@cs.cornell.edu
The Problem of Ephemeral Identity
"What is the URL for that photograph?" How many times have we asked such a question, either to retrieve an object on the Web, to
verify its identity, or to create references to enable others to
discover an object? We often treat the URL (Uniform Resource Locator)
as if it were a formal identifier for representing an object
permanently and persistently. In actuality, the URL is simply an
address masquerading as an identifier, and relying on it to identify
a unique digital resource is analogous to using a home address in
place of a social security number. One can quickly imagine the
difficulty inherent in locating or managing information about a
person based on a home address. A simple move from the starter home to the estate on the hill could essentially wreak havoc on our bank accounts, retirement benefits, and other critical records.
Furthermore, how would one distinguish between individual family
members at the same address?
Creators of digital resources must move beyond the URL as a means of identifying objects. To avoid the well-known problem of "broken links" and the maintenance associated with updating metadata records with embedded URLs, information creators must look to a persistent identifier that will not be tied to an object's address on the Web or to current technologies and protocols.
Uniform Resource Names (URNs): Requirements and a Framework
The problem of creating unique identifiers is well documented,
and the internet community has been working on it for quite some
time. The Internet Engineering Task Force (IETF), the standard
setting body for internet development, recognized the limitations of
the URL scheme several years ago, and initiated a working group to
establish a parallel scheme known as the Uniform Resource Name (URN).
The IETF URN
Working Group has developed a set of requirements and a
framework
for the development of the URN scheme.
The IETF defines a URN as a "globally unique, persistent identifier" used for recognition of, or access to, a resource or a unit of information. It is important to note that the URN framework distinguishes the identifier from the systems used to translate the identifier, as reflected in the main components of the URN framework:
Currently, URNs are not built into the internet infrastructure; however, the IETF continues to work with the internet community, including Web browser developers, to reach agreement on a standard. In the meantime, there have been a number of implementations of unique identifiers based, partially or substantially, on the URN. Among the most notable implementations are the Persistent URL (PURL), the Handle System, and the Digital Object Identifier (DOI) initiative.
Major Implementations of Persistent Identifiers
Persistent URLs (PURLs)
OCLC has implemented a system that fulfills some of the
requirements of the URN. As its name implies, the PURL is not really a URN, but a URL
that stays around for a long time. OCLC markets PURLs as "Today's
Solution," reflecting their immediate applicability. OCLC's intent
is that PURLS will easily migrate to a standard URN format when it
emerges.
The PURL attains persistence through the longevity of the PURL Resolver Service. The PURL is a URL whose server address is the name of the resolver service (e.g., the server address "purl.oclc.org" in the PURL "http://purl.oclc.org/my_images/001"). A PURL minimizes the location dependence problem of URLs by pointing to an intermediary service that performs a database lookup to ascertain the latest location of the identified object. The benefit to libraries and information providers is that once a PURL is registered in the database, it can be used in lieu of an object's actual URL. PURLs can be embedded in catalog records, finding aids, and other types of metadata used for linking to objects. If the URL for an object changes, the only maintenance required would be an update to the PURL location in the resolver database. OCLC's InterCat project demonstrates how PURLs can be used in an online catalog by embedding them in the MARC 856 field.
Participation in the PURL solution is quite simple; users can register with an existing PURL resolver. The National Library of Australia is an example of a site that has obtained the PURL software and set up its own resolver. Other projects using PURLs are listed on the PURL Sightings page.
The Handle System
Developed by the Corporation for National Research
Initiatives (CNRI), the Handle
System is a fairly comprehensive system for creating,
administering, and resolving unique identifiers. It generally
conforms to the URN framework in that it provides: a naming
scheme for unique identifiers called handles; a resolution
system to translate handles into location-specific data; a
registry in the form of a centrally administered service for
establishing and resolving naming authorities.
A handle consists of two parts: a naming authority and a unique string that identifies an item. An example of a valid handle is: "cnri.dlib/april97-payette," where "cnri.dlib" is the naming authority for D-Lib Magazine, and "april97-payette" is the string that identifies a particular article.
The Handle System is designed for widespread deployment and to withstand changes in the internet architecture through an open set of protocols, a namespace, and an implementation of the protocols that can be used in a distributed computing environment. Currently, handles can be resolved through the global handle service (four servers in the U.S. and a forthcoming European server). In addition, individual organizations can set up a local handle service that integrates with the global system.
Application developers can obtain a software library to make their systems communicate directly with the Handle System to create and resolve handles. Users can also take advantage of a proxy server that supports handle resolution in the current Web environment. The Handle proxy server is analogous to the PURL resolver in that it serves as an intermediary to translate handles into URLs. CNRI and OCLC have collaborated to create interoperability between Handles and PURLs.
Handles have been used effectively for large-scale digital imaging projects. The Library of Congress is a notable site where handles are used to identify objects in the National Digital Library Program (NDLP). Also, the Networked Computer Science Technical Reports Library (NCSTRL) uses handles to identify objects in a large distributed collection where approximately 100 naming authorities are federated. The CNRI Web site provides more information on projects using handles.
The Digital Object Identifier (DOI) Initiative
The Digital Object Identifier
is more than just an identifier. It is actually an initiative of
the Association of American Publishers (AAP) to meet the challenges
of electronic commerce and copyright management for published
objects on the internet. The DOI can be considered a
community-specific implementation of persistent identifiers. CNRI's
Handle System is the underlying technology for the administration
and resolution of DOIs; however, the "DOI System"
seems to stretch beyond the scope of the URN framework and
the Handle System. In addition to providing mechanisms for creating
and resolving unique identifiers, the DOI system extends to include
"the database" that contains the content, or related data, that
results from a DOI query. This somewhat obscures the boundaries
between the identifier, the resolution system, and functionality
enabled by a DOI.
Publishers intend the DOI system to fulfill needs that are unique to digital publications. The DOI will exist alongside existing print-oriented identifiers (e.g., ISBN, ISSN, SICI) and may optionally reference these identifiers in the item string of a DOI. The system is being designed to address issues such as: arbitrary levels of granularity in objects, varying content types, different manifestations of the same object, and changes in object ownership. Publishers are testing the DOI's ability to deal with these challenges through the development of prototype applications that are on display in the DOI Gallery.
The publishing community continues to discover and work out the complexities of implementing DOIs. For instance, the AAP adopted the general rule that one DOI should resolve to one URL, and that the "rights owner" of an object is the only one authorized to issue a DOI. This presents an interesting challenge for objects that have multiple rights holders. Also, there has been debate on whether a DOI should link to an actual piece of content, or whether it can link to a login form or other content surrogate. Elsevier has developed a pilot where some DOIs take the user to a login form for an article, and other DOIs go directly to the full-text. Other interesting pilots include the UK Authors' Licensing and Collecting Society's use of DOIs to support watermarking of electronic texts, and the Copyright Clearance Center's use of DOIs to support the purchase of rights to a large archive of digitized photos.
The International DOI Foundation will govern the DOI initiative. At this time, it appears that the foundation will control what organizations will be able to create DOIs, and this will probably be limited to publishing organizations and related stakeholders. There is extensive information on the initiative, including the DOI System Specification, at the DOI home page.
Persistent Identifiers for Digital Imaging Projects
With a background on these current developments and some
analysis, managers and developers of digital imaging projects can
effectively integrate persistent identifiers into their
applications. There are several basic tasks that must be performed
to get started:
Decide on an implementation strategy. Review the existing implementations of unique identifier schemes and resolving services. Evaluate the costs and benefits of each. Weigh this against the implications of not using unique identifiers or of designing a local solution that can migrate, later, to an existing or evolving URN implementation.
Become a naming authority. Within the chosen approach, establish an official naming authority to take responsibility for developing rules and policies for naming objects, and for deciding what objects will be named. Consideration should be given to what objects or sub-components are worthy of autonomous identifiers (e.g., individual photographs or a folder of items). This may be driven by access and rights management considerations for the collection, as seen in the decisions made by participants in the DOI initiative.
Create identifiers. Assign identifiers to all objects deemed worthy of identification by the policies established by the naming authority. Naming authorities could require an item to be named with an "intelligent" string to be consistent with existing internal naming policies or to support integration with existing legacy systems or supporting applications. For instance, item names could reflect an internal directory hierarchy that was built to mirror the structure of a serial title. Although the string would have no meaning to a resolution system, it could be parsed by applications to support local functionality. (For an example of intelligent item strings, see the Library of Congress NDLP document "Identifiers for Digital Resources.")
Register identifiers. Although projects could implement local resolution databases to translate unique identifiers to locations, this should probably be considered a short-term solution. Consider adopting one of the established solutions mentioned above since, in each case, the implementers are part of the existing URN standardization efforts.
Use Unique Identifiers in Image Delivery Systems and Supporting Applications. The ultimate benefit of unique identifiers is seen when library and image delivery applications are built to leverage naming schemes, resolution systems, and registries. Any metadata or finding aids created to access digital image objects should use the unique identifiers to ensure permanence and to prevent a maintenance nightmare as servers move, applications change, and the general internet infrastructure evolves.
Implications
Although many implementations of unique identifiers can be
fairly straightforward, some interesting questions can arise in
digital conversion projects that deal with published or copyrighted
materials. In these projects, there may be ambiguity as to who is
permitted to identify a particular object. For example, a library
may wish to digitize a published work, such as a journal, and
provide Web access to it. In addition to obtaining copyright
clearance, the following should be considered:
- Has this material been digitized already by some other library or organization?
- If so, has it been assigned a globally unique identifier?
- If so, how do I find this identifier, and should I use it instead of creating my own?
- Does the original publisher of this material have any requirements that would suggest I should adopt an existing identifier, such as a DOI?
- Is there institutional support for long-term care of the files?
These are only some of the questions that may arise over time as globally unique identifiers become embedded in the information infrastructure. The DOI initiative is fertile with discussions on such issues, especially the challenges of "rights management." There is also some debate on the proper way to identify different "manifestations" or "versions" of the same work. An excellent discussion of the DOI can be found in Mark Bide's report entitled "In Search of the Unicorn." Of particular interest to those involved in retrospective digitization projects is an envisioned scenario (case seven in the report) in which DOIs support "digital imaging clearinghouses." Bide depicts a future where there are central registries of published works that have been digitized. Each work would have one globally unique identifier (a DOI), which could be obtained by libraries, and used to provide access to previously digitized materials. The RLG Working Group on Preservation and Reformatting Information has proposed to MARBI enhancements to MARC007 values for computer files that will enable the flagging of digitally reformated items. This could position RLIN and OCLC to move one step closer to serving the registry Bide envisioned.
For further information on the topic of identifiers, the reader is encouraged to consult the following sources:
Green, Brian and Mark Bide, "Unique Identifiers: a brief
introduction,"
http://www.bic.org.uk/bic/uniquid.html
Lynch, Clifford, "Identifiers and their Role in Networked
Information Applications,"
http://www.arl.org/newsltr/194/identifier.html
URN Implementors, "Uniform Resource Names: A Progress Report,"
http://www.dlib.org/dlib/february96/02arms.html
Technical Feature
The Promise of the FlashPix Image File Format
Kevin
Donovan, New Media Applications, Intermuse, a Division of Willoughby
Associates, Limited
kdonovan@willo.com
In June 1996, Eastman Kodak, Hewlett-Packard, Live Picture, Inc., and Microsoft officially introduced the FlashPix image file format. FlashPix is an advanced image file format that addresses many of the most vexing problems involved in managing image collections and delivering image data. Its widespread adoption and use could revolutionize Web access to cultural heritage resources.
Anyone who has been responsible for creating, managing and delivering large image collections has struggled with some familiar challenges:
The FlashPix format holds out the promise of eliminating these challenges, and offering a new level of intelligent interaction between images and FlashPix-enabled applications.
A Bit of Background
FlashPix
technology is an open industry standard supported by many of the
leading technology companies. Each of the four founding
corporations contributed substantially to the FlashPix format
specification: Live Picture provided its "tiled" IVUE image format;
Kodak contributed advanced filtering algorithms and color space
transformations; Microsoft developed the OLE Structured Storage for
storing image data and procedures; and Hewlett-Packard provided
optimized JPEG compression encoding options. Other major software
and peripheral companies, including Apple, Adobe, Canon, Corel, IBM,
Intel, and Macromedia have committed their support for the format.
The FlashPix format has been provided to the Digital Imaging Group
consortium - comprised of the leaders in digital photography - to
promote and guide the development of this new image file format
standard. Although targeted by these companies primarily for use in
consumer markets (much like the initial marketing strategy for Kodak
PhotoCD), FlashPix has the potential to satisfy many cultural
heritage and professional needs.
What is a FlashPix Image File?
A FlashPix (.fpx) file contains a complete version of the
original input image plus several lower resolution copies of that
image - all in the one file. The FlashPix format describes an image
as a pyramid, or a hierarchical set of image resolutions. The highest
resolution version forms the base of the pyramid and the lowest
resolution version sits at the top (see Figure 1). A series of
sub-resolutions fall in between. Each sub-resolution is one-quarter
the size of the previous resolution. Each level of the pyramid
contains the entire image at a successively smaller resolution.
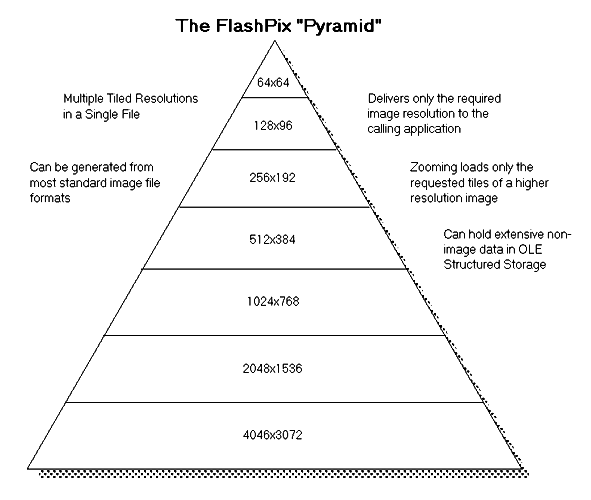
FlashPix format technology supports images of any size, captured at any pixel dimension and bit-depth. FlashPix images can be derived from existing JFIF(JPEG), GIF, TIFF or PICT files or acquired directly from a scanner or digital camera. For example, a FlashPix-based image acquired through a flatbed scanner might have a maximum resolution of 3,000x2,000 pixels. This initial file would form the pyramid base. The next sub-resolution in the hierarchy would be 1,500x1,000 pixels (one-fourth the size of the 3,000x2,000 pixel image at the base of the pyramid), the next would be 750x500 pixels, and so on. The image at the top of the pyramid would have a fixed size of 64x64 pixels (the longer dimension is set to 64 pixels and the shorter dimension is padded to 64 pixels.)
Next, each resolution is then "tiled," that is, broken into square 64x64 pixel segments. Applications that work with FlashPix images can read individual tiles or groups of tiles at any level of the pyramid. Traditional raster image file formats, such as TIFF, JPEG, and GIF, store images only at full resolution, which in most cases results in a portion of the image being displayed on screen. To paint the complete image on the screen, the traditional raster image must first be scaled down to the screen resolution.
In contrast, to view or print a portion of a FlashPix image, the application reads only the necessary tiles at the necessary resolution. This approach speeds up the access and processing of images. In addition, it minimizes the client computer's memory requirement since it is not necessary to load the entire high-resolution image. FlashPix-enabled applications do not need to process the entire image to view a small section, or process a high-resolution image to produce a low-resolution display.
Views Instead of Derivatives
The FlashPix format can also use a single file to display several
versions of an image without processing or storing a separate file
for each version. All filtering, scaling, cropping, color correction,
or other adjustments are stored in a small script file called a
"viewing object," and kept separate from the actual image data. When
the time comes to output the modified image, the stored changes are
applied to the correct resolution in the hierarchy in real-time via a
FlashPix link.
The combination of multiple resolutions residing in a single FlashPix file and different versions of the image stored as scripts rather than as additional files drastically reduces storage and file management requirements. What might require several (even dozens) of JPEGs and GIFs can be accomplished more easily and quickly with a single FlashPix file. A FlashPix file requires about 33% more disk storage space - if uncompressed - than a comparable TIFF file because of the extra resolutions contained in it; but this still results in enormous storage savings compared to saving multiple JPEGs and GIFs. And FlashPix files require as little as 20% of the RAM required to display a TIFF file.
A Home for Metadata
FlashPix' OLE structured storage makes it possible to save
non-image-related data with the file. Structured storage can be
likened to a "file system in a file." Structured storage files
contain both storages (directories) and streams (files). Any
application that understands the structured storage format can add
additional storages and streams to any structured storage file.
Standard image information data held in each FlashPix file includes
intellectual property, content description, capture device
information, camera settings, device characterizations, film
descriptions, original document scan descriptions, and scan device
data. Structured storage would be a perfect place to store
Dublin Core
or XML tagged metadata.
Compression and Color Management
A traditional raster image file can be converted to a FlashPix
image that is either uncompressed or JPEG compressed. The FlashPix
file format provides an extensible color format that includes two
unambiguous color space definitions, Kodak's PhotoYCC and NIF RGB,
and optional support for the International Color Consortium (ICC)
color management scheme. This support includes defined ICC profiles
for the FlashPix color spaces, and the ability to embed profiles
inside the FlashPix file. The FlashPix format also provides a
well-defined monochrome encoding space for the storage of grayscale
imagery.
The Internet Imaging Protocol
The Internet Imaging
Protocol, co-authored by Eastman Kodak, Hewlett Packard, and Live
Picture, is a new active-streaming protocol that enables a plugin,
Java applet, or other client application to interactively request
FlashPix image and property data from a Web server. Commands
defined by the Internet Imaging Protocol (IIP) allow the client to
request specific image tiles, a range of tiles, or to download the
entire FlashPix file. Only the tiles necessary to fill a
pre-defined image window are transferred across the network. The
image can be viewed at any level of magnification using zooming and
panning tools that become available to users when they click on the
image.
The IIP also enables the client to request non-image data that is stored as OLE structured-storage property sets. The client applications could read a textual summary description, keywords, and author information from a Dublin Core property set, and then format this information along with the image for display.
Image security and electronic commerce functions are enacted in the IIP at the level of individual tiles. Access to individual tiles can be restricted or unrestricted. For example, it is possible to design an application that will enable a user to access image data for free at low resolution and on a paid basis at higher resolutions.
A Cause for Enthusiasm...and Prudence
The FlashPix format holds enormous promise. Multiple image
resolutions in a single file may eliminate the need for multiple,
application-specific derivatives. Tiling tackles the major difficulty
of distributing image files via networks, and reduces client-side
memory requirements. FlashPix Views and Links allow a single image
to display itself in several cropped, color corrected, or compressed
versions. And OLE structured storage offers the ability to embed
any type of standardized metadata in the image. With FlashPix,
images become more than passive computer files, they become objects,
opening up new possibilities for interaction between image data and
applications.
With all this potential, why are we still loading our databases and Web sites with traditional raster image files? First of all, support for the new image format has been restricted largely to consumer image editing programs such as Microsoft Picture It and Adobe PhotoDeluxe. Secondly, the W3C, the international industry consortium that promotes standards for the World Wide Web, has not accepted FlashPix as an image file standard (currently supporting only GIF and JPEG), and Microsoft and Netscape have not yet incorporated native support for FlashPix in their browsers. (FlashPix images can be viewed on the Web by using a freely distributed plugin.) Image database packages are still not supporting the format, due in par t to the lack of native support by Web browsers and the fact that mature software development kits have been available to developers only within the past 10-12 months. Most importantly, cultural institutions have not flocked to the format because it is largely untested for use by museums, libraries, and archives.
Cultural institutions are justified in eyeing new imaging technologies skeptically until they prove appropriate to the task and viable in the long term. If FlashPix can prove its worth, however, we will enter into an exciting new phase of image creation and distribution.
|
Highlighted Web Site Graphics
Formats |
Calendar of Events
Genre in Digital Documents at the Hawaii International Conference on Systems Sciences
Abstracts for Papers Due April 15, 1998
Papers are invited for a minitrack on "Genre in Digital
Documents" as part of the Digital Documents track at the Hawaii
International Conference on System Sciences (HICSS). The successful
use of digital media may depend on the emergence of new or
transformed genres of digital communication. The term "genres" is
defined broadly by conference planners to include not just particular
technologies or modes of communication or presentation (e.g.,
hypertext, email, the Web, and so on), but complex communicative
forms anchored in specific institutions and practices - the digital
analogues, that is, of print forms such as a newspaper, the annual
report, the how-to manual, the scholarly journal. The conference will
be held January 5-8, 1999 on the island of Maui.
Managing
Metadata for the Digital Library: Crosswalks or Chaos?
May 4-5, 1998
Part of the challenge of building digital libraries is developing
the metadata infrastructure needed to manage, maintain, and deliver
digital materials. Metadata for the digital library encompasses not
only traditional cataloging information, but also all of the
information necessary to construct, preserve, and control the access
to and presentation of digital content. This institute brings
together experts in the metadata and digital library fields to
present the latest developments, standards, and tools, and to explore
the impact of digital library development on existing catalogs and
processes. The institute is co-sponsored by the Association for
Library Collections & Technical Services (ALCTS) and the Library
and Information Technology Association (LITA) and will take place at the Georgetown University Conference Center, Washington, DC.
AIIM '98 Show and Conference
May 11-14, 1998
One of the largest annual tradeshows in the United States will
take place in Anaheim, California at the Anaheim Convention Center
from May 11-14, 1998. AIIM '98 assembles the major vendors in the
information industry to display and demonstrate their products, and
also provides a forum for anyone involved in the field of information
management. Admission to the show and keynote talks is free.
RLG's
Managing Digital Imaging Projects Workshop
May 13-15, 1998 & May 18-20, 1998
RLG is pleased to offer two sessions of its 2.5 day
workshop designed to assist librarians, archivists, curators, and
preservation administrators in managing digital imaging projects,
to be held May 1998 at the University of Leeds, UK. Registration
is now open for these two sessions. For further information
contact: Robin Dale,
bl.rld@rlg.org.
OCLC Understanding and Using Metadata Workshop
June 26, 1998
OCLC will be sponsoring a workshop on metadata in conjunction
with the American Library Association Annual Conference in
Washington, D.C. The event will focus on topics such as the state of
metadata today; future directions; whether you should use metadata;
and how you could start using metadata in your own applications. For
further information, contact Erik Jul at (614) 764-4364 or email:
jul@oclc.org.
The Transformation of Recorded Sound Preservation in the Digital Age
June 26, 1998
The Association of Library Collections & Technical Services
(ALCTS) is sponsoring a preconference to the American Library
Association Annual Conference in Washington, D.C entitled, "The
Transformation of Recorded Sound Preservation in the Digital Age."
The preconference, presented by the ALCTS Preservation and
Reformatting Section's Photographic and Recording Media Committee, is
cosponsored by the Society of American Archivists and the National
Archives and Records Administration, with additional support from the Research Libraries Group. The preconference is designed for
librarians or archivists involved with audio collections who are
concerned about the shifting trend toward digital technologies.
Speakers will review current practices for acquiring, preserving, and
enhancing access to sound collections, and assessing advantages and
disadvantages offered by analog and digital technologies. Strategies
will be discussed for coping with increasing replacement of analog by
digital products and practices.
Digitisation Summer School '98, Humanities Advanced Technology and Information Institute
July 5-18, 1998
The availability of high-quality digital content is central to
improved public access, teaching, and research about heritage
information. Archivists, librarians, and museum professionals are
among the many groups heavily involved in creating digital resources
from analog collections. Skills in understanding the principles and
best practices in the digitization of primary textual and image
resources have broad value. Participants in this two-week summer
school to be held in Glasgow, UK will examine the key issues and
acquire the skills to develop digital collections of heritage
materials through seminars and hands-on exercises.
Announcements
Digital Libraries Initiative--Phase 2 Competition
The second phase of the Digital Libraries Initiative (DLI) to support
innovative digital library research, testbeds, and applications has
recently been announced. The National Endowment for the Humanities
(NEH), the National Library of Medicine (NLM), and the Library of
Congress (LC), join the National Science Foundation (NSF), the
Defense Advanced Research Projects Agency (DARPA), and the National Aeronautics and Space Administration (NASA) in this phase of DLI. The National Archives and Records Administration and the Smithsonian Institution are also partners in
this effort.
DLI Phase 2 invites proposals that will:
· Selectively build on and extend research and testbed
activities in promising digital libraries areas;
· Accelerate development, management, and accessibility of
digital content and collections;
· Create new capabilities and opportunities for digital
libraries to serve existing and new user communities, including all
levels of education;
· Encourage the study of interactions between humans and digital libraries in various social and organizational contexts.
The participation of cultural sponsors in DLI Phase 2 should ensure that humanities and social science interests are well represented. In its announcement of the DLI, for example, NEH is encouraging "projects that focus on issues important to the effective creation, use, and preservation of digitized humanities collections."
The deadline for letters of intent has been extended to April 30, 1998, and the full proposals are due July 15, 1998. For information on projects funded in the first phase of DLI, see http://www.cise.nsf.gov/iris/DLHome.html.
European
Commission's DLM Forum Best Practices Guidelines Now
Available
The English version of Guidelines on Best Practices for Using
Electronic Information: How to Deal with Machine-Readable Data and
Electronic Documents has recently been made available in PDF
format. This report is the principal outcome of the DLM-Forum on
electronic records held in December 1996, which was organized
jointly by the Member States of the European Union and the European
Commission. The report provides short and medium-term strategies
needed to address the management and preservation of electronic
information. It includes sections on the life cycle of electronic
records; designing, creating, and maintaining electronic
information, including digital images; and short and long -term
preservation and access strategies for electronic records.
The World Wide Web Consortium (W3C) Working Draft Resource Description Framework (RDF) Model and Syntax
This draft specification is a work in progress representing the
current consensus of the W3C RDF Model and Syntax Working Group, and
is available for review by W3C members and other interested parties.
The RDF - the Resource Description Framework - is a foundation for
processing metadata. It provides interoperability between
applications that exchange machine-understandable information on the
Web. RDF emphasizes facilities to enable automated processing of
Web resources. RDF metadata can be used in a variety of application
areas, for example: in resource discovery to provide better search
engine capabilities; in cataloging for describing the content and
content relationships available at a particular Web site, page, or
digital library; in facilitating knowledge sharing and exchange by
intelligent software agents; in content rating; in describing
collections of pages that represent a single logical "document"; and
in describing intellectual property rights of Web pages. Comments
on this draft specification may be sent to: www-rdf-comments@w3.org.
Call
for Papers: Special Topic Issue of Computers and the Humanities:
"Digital Images"
This special issue of Computers and the Humanities will
address challenges and opportunities in designing, building, and
using digital image collections in the humanities. The deadline for
submitting papers for consideration for publication is October 1,
1998.
Robert Runyon Photograph Collection
The General Libraries of the University of Texas at Austin, in
cooperation with the Center for American History, also of UT Austin,
is providing Web access to digitized versions of 8,241 photographic
images from the Robert Runyon Photograph Collection of the South
Texas Border Area. This project is utilizing an implementation of
Uniform Resource Names (URNs) as persistent, location-independent
identifiers. The Runyon URN is based on the URN Syntax, as defined
in Request
for Comments (RFC) 2141. An example of a Runyon URN is:
"urn:utlol:runyon.00001." The URN resolver performs two functions:
it resolves the URN to a metadata record, and it resolves the URN to
the resource itself.
The Library of Congress
National Digital Library Program
The Library of Congress National Digital Library Program (NDLP)
is digitizing valuable holdings on American history, and making them
freely available to teachers, students, and the general public over
the Internet . The Web site is regularly updated, with significant
collections being added on a frequent basis. NDLP recently
announced the availability of digitized versions of U.S.
Congressional Documents and Debates, 1774-1873; selections from two
collections at the Library of Congress that illuminate the life of
Abraham Lincoln; and the complete George Washington Papers from the
Manuscript Division at the Library of Congress.
FAQs
Question:
How do I view TIFF images over the Web?
Emil Levine
Head, INIS Clearinghouse
Vienna, Austria
Answer:
Tag(ged) Image File Format (TIFF) is one of the most popular
image file formats. It is platform-independent, and supports 1-bit
to 24-bit imaging using a variety of compression methods. Although
TIFF has become the de facto standard for storing master/archival
images, it is rarely used for Web access. Currently, none of the
popular Web browsers supports TIFF images, although most of them
have the built-in capability to interpret and display other common
file formats, such as GIF and JPEG. There are no near-term plans to
add TIFF-viewing functionality to Netscape or Microsoft Internet
Explorer.
To be able to view a TIFF image on the Web, one needs to configure the helper applications of the Web browser to a TIFF-compatible image viewer (such as Adobe Photoshop, Paint Shop Pro) or utilize a plug-in capable of reading the file. Plug-ins enhance Web browsers by adding capabilities not supported by the basic system. The advantage of plug-ins is that they are loaded and executed only when they are needed, and therefore have less overhead on computer memory.
Although there are quite a few TIFF-compatible software programs, the appropriate choice will depend on the following variables:
The Unofficial TIFF Page includes information on how to find programs that can read TIFF software, including a section for multi-page TIFFs. Some of the software programs listed are free of charge, and some require a licensing fee. They have different functionalities, from basic viewing to more advanced features such as zoom, scale, rotate, pan, file conversion, and image enhancement. The Netscape Inline Plug-in home page includes information on several plug-ins that can be used to open TIFF images.
In addition to the software and plug-ins recommended in the Unofficial TIFF Page and Netscape Inline Plug-in sites, we compiled the following list that describes some of the other popular TIFF viewers:
|
|
|
|
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
|
Footnotes
(1) Cartesian Perceptual Compression (CPC) is emerging as an alternative to CCITT Group 4 compression as it provides higher compression ratios for storing 1-bit TIFF images for faster downloads and smaller storage requirements. (Return to Text)
RLG News
Conference on Hybrid Conversion
Moving forward with plans announced at the January 1998 ALA
Preservation Administration Discussion Group meeting, RLG has sought
funding to hold the Conference on Hybrid Conversion:
Preservation Microfilm and Digital Image Files. This
invitational two-day conference is tentatively scheduled to take
place during summer 1998. The conference will seek to address three
broad questions, reach consensus, and disseminate outcomes:
Results of the conference will be conveyed via the RLG web site, RLG DigiNews, international press releases, and in the event that modifications to RLG's microfilming guidelines are recommended, RLG will communicate with purchasers of its two microfilming manuals about the procedural and technical changes. Further information will be available on the RLG PRESERV site in the coming months.
Digital
Archive Directions Workshop
RLG will be a co-sponsor of the Digital Archive Directions Workshop to be
held at the National Archives and Records Administration in College
Park, Maryland, from June 22 through 26, 1998. A part of the ISO
Archiving Workshop Series, this is the twelfth US event of its kind.
Other sponsors include: International Standards Organization (ISO),
Committee on Earth Observation Satellites (CEOS), Consultative
Committee for Space Data Systems (CCSDS), the Johns Hopkins
University - Applied Physics Laboratory (APL), the National
Aeronautics and Space Administration (NASA), and NARA.
Digital Conversion of Archival Finding Aids
In the last issue of RLG DigiNews, information regarding
RLG's new alliance with Apex Data Service for conversion of archival
finding aids was announced. Since then, RLG was awarded a $40,000
grant from the Gladys Krieble Delmas Foundation that will directly
benefit RLG members wishing to convert archival finding aids. The
grant is being passed through a 2:1 match to members who responded to
a request for applications announced in February. Twenty-eight RLG
members will convert over 350 finding aids (totalling 15,000 pages)
with the help of this grant. Further information will be available in
the near future on the RLG Primary
Sources web site.
Hotlinks Included in This Issue
Feature Article
Applications Using the
Handle System: http://www.handle.net/apps.html
Copyright Clearance Center:
http://doi.copyright.com
D-Lib Magazine:
http://www.dlib.org
The Digital Object Identifier
(DOI): http://www.doi.org
The DOI Gallery:
http://www.doi.org/gallery/tour.html
DOI System
Specification: http://www.doi.org/system_spec.html
Elsevier: http://www.elsevier.nl/inca/homepage/about/doi/
A
Framework for the Assignment and Resolution of Uniform Resource
Names:
http://www.bunyip.com/research/ietf/urn-bof/urnframework.txt
Functional
Requirements for Uniform Resource Names:
http://ds.internic.net/rfc/rfc1737.txt
The Handle System:
http://www.handle.net
Handles and OCLC's
PURL System: http://www.handle.net/docs/PHS-demo.html
IETF URN
Working Group:
http://www.ietf.org/html.charters/urn-charter.html
In Search of the
Unicorn: The DOI from a User Perspective:
http://www.bic.org.uk/bic/bicinfo.html
International DOI
Foundation: http://www.doi.org/DOI-Found-Recruit.html
Library of Congress:
http://lcweb.loc.gov
Library of Congress NDLP- Identifiers for Digital Resources:
http://lcweb2.loc.gov/ammem/award/docs/identifiers.html
Library
of Congress NDLP Documentation:
http://lcweb2.loc.gov/ammem/award/docs/select.html
National Library of Australia:
http://www.nla.gov.au
National Library of Australia PURL Resolver: http://purl.nla.gov.au
Networked Computer Science Technical Report Library: http://www.ncstrl.org
OCLC's Persistent URL (PURL): http://purl.oclc.org
PURL InterCat
FAQ: http://purl.oclc.org/OCLC/PURL/ICAT_FAQ
PURL
Sightings: http://purl.oclc.org/OCLC/PURL/SIGHTINGS
RLG Working Group on Preservation and Reformatting Information:
http://www.rlg.org/preserv/pri-intro.html
UK Authors'
Licensing and Collecting Society (ALCS):
http://www.alcs.co.uk/doidocs/index.htm
Technical Feature
Dublin
Core: http://purl.oclc.org/metadata/dublin_core/
FlashPix:
http://www.kodak.com/go/FlashPix
The Internet Imaging
Protocol: http://image.hp.com/index.html
W3C: http://www.w3.org/
Highlighted Web Sites
Graphics Formats: http://www.octobernet.com/~brian/graphics/
Calendar of Events
AIIM '98 Show and
Conference: http://www.aiim.org/aiim98
Digitisation Summer School '98, Humanities Advanced Technology and Information Institute:
http://www.arts.gla.ac.uk/HATII/Courses/SummerDigi98/index.html
Genre in Digital Documents
at the Hawaii International Conference on Systems Sciences:
http://www.cba.hawaii.edu/hicss
Managing
Metadata for the Digital Library: Crosswalks or Chaos?:
http://www.ala.org/alcts/events/institutes/metadata.html
OCLC Understanding and Using Metadata Workshop:
http://www.oclc.org/institute/ala_workshop_metadata.htm
The
Transformation of Recorded Sound Preservation in the Digital Age:
http://www.ala.org/alcts/events/preconference98/preservation.html
Announcements
Call
for Papers: Special Topic Issue of Computers and the Humanities:
"Digital Images" :
http://httpsrv.ocs.drexel.edu/faculty/goodruaa/special/
Digital Libraries Initiative--Phase 2 Competition:
http://www.nsf.gov/pubs/1998/nsf9863/nsf9863.htm
European
Commission's DLM Forum Best Practices Guidelines Now Available:
http://www2.echo.lu/dlm/en/gdlines.html
The Library of Congress National Digital Library Program: http://lcweb2.loc.gov
Request for Comments (RFC) 2141:
http://www.ietf.org/html.charters/urn-charter.html
Robert Runyon
Photograph Collection: http://runyon.lib.utexas.edu/runyon/
W3C
Working Draft Resource Description Framework (RDF) Model and
Syntax: http://www.w3.org/TR/1998/WD-rdf-syntax-19980216
FAQs
Accel
View: http://www.acordex.com/browseProd/welcome.html
CPC View:
http://www.cartesianinc.com/
DocView:
http://www.informatik.com/docview.html
Graphic Converter: http://www.goldinc.com/Lemke/gc.html
Java ViewTIFF: http://www.acordex.com/browseProd/welcome.html
JPEGView:
http://english.onysd.wednet.edu/english/web/macware/jpegview.htm
Minolta TIFF Viewer:
http://www.minoltausa.com/low/static/tiff_plugin/tiff_view.html
Netscape
Inline Plug-in:
http://home.netscape.com/comprod/products/navigator/version_2.0/plugins/image_viewers.html
Tiff Surfer:
http://www.visionshape.com/freetiff.html
Unofficial TIFF
Page: http://home.earthlink.net/~ritter/tiff/
VTLS TIFF View: http://image.vtls.com/ss_services/vtlstif.html
RLG News
Digital
Archive Directions Workshop:
http://ssdoo.gsfc.nasa.gov/nost/isoas/us12/call.html
Research Libraries Group
(RLG): http://www.rlg.org/toc.html
RLG Primary
Sources: http://www.rlg.org/primary/index.html
RLG PRESERV:
http://www.rlg.org/preserv/index.html
![]()
Publishing Information
RLG DigiNews (ISSN 1093-5371) is a newsletter conceived by the members of the Research Libraries Group's PRESERV community. Funded in part by the Council on Library and Information Resources (CLIR), it is available internationally via the RLG PRESERV website (http://www.rlg.org/preserv/). It will be published six times in 1998. Materials contained in RLG DigiNews are subject to copyright and other proprietary rights. Permission is hereby given for the material in RLG DigiNews to be used for research purposes or private study. RLG asks that you observe the following conditions: Please cite the individual author and RLG DigiNews (please cite URL of the article) when using the material; please contact Jennifer Hartzell at bl.jlh@rlg.org, RLG Corporate Communications, when citing RLG DigiNews.
Any use other than for research or private study of these materials requires prior written authorization from RLG, Inc. and/or the author of the article.
RLG DigiNews is produced for the Research Libraries Group, Inc. (RLG) by the staff of the Department of Preservation and Conservation, Cornell University Library. Co-Editors, Anne R. Kenney and Oya Y. Rieger; Production Editor, Barbara Berger; Associate Editor, Robin Dale (RLG); Technical Support, Allen Quirk.
All links in this issue were confirmed accurate as of April 10, 1998.
Please send your comments and questions to preservation@cornell.edu .
![]()