



- Feature Articles
Collecting and Preserving the Web: The Minerva Prototype, by William Y. Arms, Roger Adkins, Cassy Ammen, and Allene Hayes
- Conference Report
- Highlighted Web Site—Cultivate Interactive
- Calendar of Events
- Announcements
- RLG News
- Hotlinks Included in This Issue
Editor's Note
The search for digital preservation solutions has become a worldwide endeavor, and tracking important initiatives is approaching obsessive levels for the staff of RLG DigiNews. In this issue, we are pleased to offer complementary feature articles on archiving the Web. The first article covers a recent project at the Library of Congress, and the second reports on the development of a Web harvester for preserving national Web spaces in Europe. We also include a conference report on creating and preserving digital sound. In addition, the calendar of events and announcements include reports on conferences held and planned that feature digital preservation. Finally, it is with regret and best wishes for the future that we bid farewell to co-editor Oya Y. Rieger, who is assuming a challenging new role as Coordinator of Distributed Learning for the Cornell University Library. Oya played a major role in developing RLG DigiNews from the beginning, serving as the first production editor and later co-editor. Her keen insight and thoughtful editing will be sorely missed. We expect to hear more from her in the future, however, as a contributing author, so stay tuned.
![]() Collecting and Preserving
the Web: The Minerva Prototype
Collecting and Preserving
the Web: The Minerva Prototype
William Y. Arms, Cornell University
wya@cs.cornell.edu
Roger Adkins, Library of Congress
radk@loc.gov
Cassy Ammen, Library of Congress
camm@loc.gov
Allene Hayes, Library of Congress
ahay@loc.gov
1. Open Access Materials on the Web
Objective
An ever-increasing amount of primary source materials is being created in digital formats and distributed on the Web; many materials do not exist in any other form. Future scholars will need them to understand the cultural, economic, political and scientific activities of today and, in particular, the changes that have been stimulated by computing and the Internet. These are fragile materials, a transient and quickly disappearing record of our time.
The Library of Congress collects and preserves the cultural and intellectual artifacts of today for the benefit of future generations. Last year, the National Research Council report, A Digital Strategy for the Library of Congress, emphasized the importance of extending these activities to digital materials. The report urged the Library to move ahead rapidly. Recently, Congress has voted substantial amounts of money to support such work.
For the past year, we have been working together on a prototype system for the Library of Congress to collect and preserve materials from the Web. This project is known as "Minerva" (the name is a light hearted acronym for "Mapping the INternet: the Electronic Resources Virtual Archive"). This article describes the prototype, but more importantly it discusses what we have learned and offers suggestions for what should be included in a full-scale system.
Open Access Web Materials
The materials on the Web can be divided into two categories, those that are provided with open access and those for which there are access restraints. Minerva is concerned with the first category, open access materials that the creators have made publicly available, without restriction. The category includes most conventional Web sites, interlinked sets of pages that have been placed on the Web for unrestricted public access. A library can collect them by simply downloading the Web pages over the Internet.
Some materials are available over the Internet but have constraints on access. The most common restriction is robot exclusion, where the Web site has a file requesting robots not to access the materials. News services, such as CNN, are examples of sites that are important to preserve but use robot exclusion. These materials should not be downloaded without permission.
Even so, the number of potentially valuable items is enormous and growing. OCLC's annual Web Characterization Project estimates the number of public Web sites (using a definition of Web site that is somewhat different from the definition that an archive might use). The June 2000 estimate was 7.1 million public Web sites, increasing by more that 2 million per year. In July 2000, the Google search engine first reported that it indexed more than one billion Web pages. A significant, but unknown, proportion of these pages change every month.
Strategies Used by Other Libraries and Archives
There are several important Web preservation projects in other libraries and archives, including the NEDLIB harvester project described in the companion article. Three earlier initiatives were launched in 1996:
The National Library of Australia has been one of the pioneers with its excellent Pandora program. Since its inception in June 1996, Pandora has established an archive of selected Australian online publications, including Web sites, and developed a national strategy for their long-term preservation, which was described in a recent editors' interview with Colin Webb.
The Internet Archive is a not-for-profit organization in San Francisco that has been collecting all open access HTML pages since 1996, approximately monthly. As of March 2001, its holdings were 60 terabytes on disk, growing at 10 terabytes per month. A commercial company, Alexa Internet, carries out the data gathering. Alexa donates its data to the archive when it is six months old.
The National Library of Sweden is another pioneer. The library's program, known as Kulturarw3, also began in 1996. Its aim is to test methods of collecting, preserving and providing access to Swedish electronic documents that are published online. By August 2000, it had completed seven downloads of the Swedish Web, some 65 million items, about half of which are text documents.
The Minerva Prototype
The purpose of the Minerva prototype was to gain insights into the practical issues involved in collecting and organizing selected Web sites, and to understand how the Library of Congress might operate a full-scale preservation program. The main activities in the prototype were as follows:
 |
Figure 1. The Minerva home page
In parallel to the work described in this article, the Library of Congress requested the Internet Archive to capture a set of Web sites related to the presidential elections in fall 2000. This pilot captured some 150 to 200 Web sites on a daily basis over the period leading up to the Inauguration 2001. In addition to capturing the materials, the pilot is creating a simple index and a time-dependent viewer. It has proved to be a very valuable study of the technical and logistical concerns in capturing complete Web sites and organizing them for long-term preservation.
2. Collection
Downloading Snapshots of Web Sites
The unit of collection and preservation is a Web site, which from a computing viewpoint is simply a set of files. The technique for collecting a Web site is to download a snapshot of the site using a program that copies files from the Web server to a computer at an archive. The snapshot may contain all the files at the site or a subset. (For example, the snapshot might include only text files.) Snapshots are taken periodically, so that the archive has a sequence of snapshots for each site. Each snapshot is stored with provenance metadata, such as the date on which the snapshot was taken. In all Web collections, the actual downloading and storing of the files are carried out automatically.
Intuitively, a snapshot should include all files that are part of a site, but sometimes it pays to be selective. Much of the complexity of Web sites lies in the files that contain executable computer programs, and many of the largest files are in special formats, such as audio and video files. Ignoring these files greatly simplifies the task of collecting Web sites, but at the cost of losing important materials. For example, in building their indexes of the Web, Web search programs ignore all files except text files.
For the Minerva prototype, the program used to download the snapshots was HTTrack, a Web crawler that is used to make mirrors of Web sites. HTTrack is made openly available by its developers. To run HTTrack, the program is given a URL, usually to the home page of a Web site. The program makes a copy of the page and extracts all links to pages in the same Web site. It then downloads those pages and continues until the entire Web site has been copied. This process copies all files, including text, images, videos, executable programs, style sheets, metadata files, etc.
This process sounds straightforward, but there are many practical problems, as highlighted below.
| Formats |
| The files are in a very wide variety of formats, for example text, images, audio or video. Many include segments of computer programs, written in languages such as JavaScript or Java, and related materials such as style sheets or files of metadata. Some pages are generated dynamically or depend upon information stored in databases. Each file on the Web has its format identified by a MIME type, such as text/html or image/jpeg, but every year new formats and newer versions of formats are introduced. |
| Boundaries |
| The boundaries of individual sites may be hard to define. The usual definition is to collect everything that has a domain name equal to or below the starting URL of the Web site. |
| Errors |
| Many of the files contain errors and inconsistencies; they do not conform to the formats or contain hyperlinks (URLs) to files that do not exist. Many errors are identified by the mirroring program and recorded in a log file. As listed in Appendix A of the full report, almost every site that was downloaded had at least one error. |
| Timing |
| The time needed to download a site may be several hours. If changes are made to the site while it is being collected, the snapshot may be incomplete or inconsistent. This is a particular problem with sites that report current events as they happen. |
| Availability |
| Failure to download a Web site, or a specific file, may result from a computer being unavailable or a network connection being down. It is almost impossible to distinguish files that are temporarily unavailable from files that have been removed or never existed. |
| System Performance |
| HTTrack is a reasonably efficient mirroring program, yet downloading many of the snapshots from a moderately powerful desktop computer with a good Internet connection took a long time, with a maximum approaching four hours. Many of the delays are caused by broken links. Any Web crawler that downloads files for preservation has to balance performance against respect for the sites that are being collected, for example, by not overloading the site. |
|
Databases |
|
Downloading snapshots of Web sites collects materials that are stored on Web servers. Many sites have a set of pages on a Web server that provide a user interface to materials in a separate database. The Library of Congress's American Memory collections are an example. Although the materials are available with open access, it is hard to download them for preservation except with assistance from the publisher of the site. |
Table 1. Problems Encountered in Collecting Web Snapshot
3. Selection
Collecting Strategies: Bulk vs. Selective
Archives that collect Web sites can follow collection strategies that are bulk or selective. With bulk collecting, all sites that satisfy standard criteria are collected. With selective collecting, individual sites are chosen by selection librarians or other experts.
The Internet Archive and the Swedish Kulturarw3 project have bulk collection policies. The Internet Archive's policy is to save HTML pages, with associated images on a monthly cycle. Kulturarw3 collects all Web sites of interest to Sweden, including the entire .se domain.
The Australian Pandora project has a policy of selective collection. Librarians select Web sites that have particular interest in Australia and decide the frequency of collection for each site. The Minerva prototype also followed a selective strategy. At the beginning of the project, a group of recommending officers at the library met to suggest possible Web sites to select for the prototype. They discussed the Pandora guidelines, but it was decided to rely on the expertise of the librarians to nominate possible sites. They suggested a total of 35 sites. Snapshots were made of 29 of them, as listed in the full report. The project team studied three sites in detail:
http://www.whitehouse.gov/
http://www.algore2000.com/
http://www.georgewbush.com/[Editor's note: The Al Gore 2000 Web site is no longer available.]
For bulk collections, the usual practice is to take snapshots of every site with a regular frequency, e.g., monthly. When an archive follows a selective collection policy, it is possible to vary the frequency at which snapshots are collected. For example, a site for a special event might be collected daily during the event, but at less frequent intervals before and afterwards. The daily snapshots captured by the Internet Archive provide a fascinating record of the candidates' tactics in the days leading up to the election and during the Florida recount.
Selection Policies for the Library of Congress
The volume and complexity of digital materials to be preserved is so great that the Library of Congress will need partners to share the burden. Possible partners include the National Archives and Records Administration, other national libraries—around the world and in the United States—and other archives and research libraries.
For the Library of Congress itself, bulk collection and selective collection are both needed. The cost difference is substantial. Comparing our staffing estimates with the experience of the Internet Archive suggests that selective collection, as carried out by the Minerva prototype, is at least 100 times as expensive as bulk collection.
Selective collection of a comparatively small number of sites allows careful attention to managing and preserving them. The Minerva prototype, for example, collected all files from a Web site, organized them for online access and provided a catalog record—all advantages for scholars. For such reasons, despite its costs, selective collection is likely to be an important part of the Library of Congress's strategy.
Bulk collection provides different advantages for scholars. One is that future generations may value sites that would not have been selected. Consider, for example, the personal site of a student who later becomes prominent. New Web sites are another; with even the most effective selection procedures, there will be a delay from when a site is first released until it is recognized as important.
4. Use of the Collections for Scholarship and Research
When snapshot files have been downloaded to an archive, they must be stored in a manner that facilitates long-term preservation and is convenient for users. Although there is very little experience to guide planning, it seems that some researchers will want to analyze Web sites by computer and others will wish to view an online version of the archived Web sites. These two approaches are for different types of research, and the Library of Congress will need to serve both.
Analysis of Snapshot Files by Computer
For huge volumes of information, computer programs carry out the first stage of research, by reading through the archives, searching for specific information or identifying patterns. Such analyses are best carried out on the original, unmodified source files, rather than the rendered form as seen by a user of the Web materials. The files must be organized in a manner that allows rapid processing.
The Internet Archive has organized its materials for this kind of computer analysis. It provides a number of computers at their site for researchers to install and run their own programs.
Access Versions for Viewing by Scholars
Other scholars will wish to view preserved Web sites as they appeared on the date when they were collected. For this, they want to view and interact with the rendered form of the Web site, not the underlying source files. The Pandora project organizes its collections in this way. For Minerva, a Web site was built to provide online access to each snapshot of the sites in the collections. This Web site was designed for scholars who wish to experience individual sites as they originally appeared.
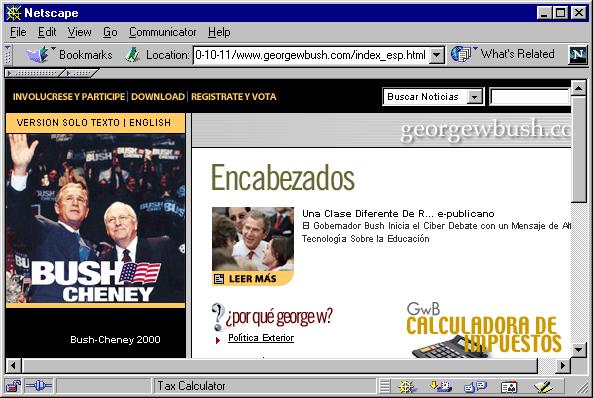 |
Figure 2. A snapshot of www.georgewbush.com rendered in Spanish
Unless the original Web site was designed for mirroring, the snapshot files as downloaded often will not render correctly; strange things may happen when a user attempts to view the Web site at a later date. For example, as shown in Figure 2, the mirror of the George W. Bush Web site defaulted to the Spanish version. To overcome such problems, some of the files have to be edited. We use the term access version for a version of a snapshot that has been edited for viewing online. Here are some of the editing changes that are needed.
Absolute URLs
Any URL within a Web site that specifies an absolute address will link to the current location with that address, not to the version in the archive. Internal hyperlinks need to be edited to relative addresses.Executable Code
Many files incorporate program code that displays the current date or depends on other current information. Such code needs to be modified to reflect the circumstances under which the snapshot was taken.
For reasons of cost, it is highly desirable that this editing is carried out entirely automatically. However, because of the variety and complexity of Web sites, inconsistencies will slip through. Manual checking would be needed to confirm that a version of the Web site replicates the original experience, but manual checking is very expensive indeed. To be conscientious, every page needs to be viewed, with every combination of options, from a variety of Web browsers, on a variety of hardware, with several different operating systems. In practice, inconsistencies are a fact of life.
Whatever level of editing is carried out, because of technology obsolescence there is every likelihood that eventually it will be impossible to retain the original look and feel and experience of using the Web sites.
5. Legal Issues
The Legal Situation
The Minerva team is working with the U.S. Copyright Office to clarify the legal situation for downloading open access materials. For the Library of Congress to carry out its responsibility to preserve digital information—most of which is subject to copyright—the legal framework must be clear and unambiguous. While it is reasonable to assume that most organizations that make information openly available on the Web would be willing for the Library of Congress to download copies and keep them for future research, the library does not currently have the explicit legal right to do so.
The National Research Council's study, The Digital Dilemma, in its excellent chapter on "Public Access to the Intellectual, Cultural, and Social Record," noted that the current system of copyright deposit needs modification to enable preservation. The collection of born-digital materials for the benefit of future scholarship is clearly consistent with the Library of Congress's historic duties. These are recognized and supported by the Copyright Act and the legislative history surrounding Section 407 on demand deposit.
Downloading Open Access Materials from the Web
Through the system of copyright registration and deposit defined in Chapter 4 of the Copyright Act, the Library of Congress receives a copy of essentially all materials registered for copyright and has the right to demand copies of all materials published in the USA to add to its collections.
With open access materials, the library is able to acquire materials by downloading, rather than by delivery from the publishers. This is convenient for everybody, but was not anticipated by the Copyright Act. To develop a full program of collecting and preserving open access Web sites, in this manner, the library needs authority for three activities:
The technical questions of how to organize the collections for use by scholars is related to the policies and procedures governing who has access to them. This is a complex topic that has not been studied by Minerva.
6. Long-term Preservation
Preservation Objectives
Strategies for preservation are interwoven with assumptions about why the collections are being preserved. Preservations strategies can be judged against three objectives:
Files downloaded from Web sites have several characteristics that make them difficult to preserve: a very large volume of data, no feedback from the archive to the producer, high error rates, and an essentially unbounded variety of formats. The very large volumes of data mean that almost everything must be automated. The independence of the producers and the high error rates give the Library of Congress very little control over the materials.
Despite the considerable research that has gone into preservation over the past few years, there are only two strategies that are practical for preserving materials with these characteristics. They are refreshing and migration. Each is needed for preservation of Web materials.
Refreshing the Snapshot Files
There are strong reasons for keeping copies of the original, unmodified snapshot files, that is, the exact bit sequences that were downloaded. These sequences of bits are the primary source materials for future research, even if it becomes increasingly difficult to interpret them. Preserving these files achieves the first objective, preservation of bits.
Migration
Computing formats change continually. File formats of ten years ago may be hard to read. There is no computer in the world that can run programs for computers that were widespread a short time ago. Therefore, in addition to refreshing the raw data, digital preservation must be able to interpret the data, to understand its type, its structure, and its formats. Migration has been standard practice in data processing for decades. When computer systems change, the data is migrated from computer to computer, and from database to database. The Library of Congress's MARC catalog records are a typical example. The principle of migration is that the formats and structure of the data may be changed, but the semantics of the underlying content is preserved.
For Web materials, automatic migration can be carried out on individual files, based on the file type. On a regular basis, an archive reviews the formats, protocols, program components, etc, used. If the file type is becoming obsolete, the archive converts the file to the nearest modern equivalent. For example, a file in HTML 3.2 might be converted to HTML 4.0 and then at a later date migrated to XHTML; programs in Java 1.0 might be converted to 2.0. In theory, automatic migration preserves content and may sometimes preserve the experience. In practice, no conversion is perfect, particularly for executable code or when the data may contain errors. Therefore it is essential to keep the original source and a record of the conversions made over the years.
Limitations of Preservation Strategies
Even with conscientious migration, there is no guaranteed way to preserve the experience of using digital materials. For the foreseeable future, preservation of experience will be labor-intensive and inexact, requiring analysis of individual Web sites.
In the future, digital archeology by skilled researchers will be needed to extract information from ancient Web sites. The Library of Congress will need to develop a library of technical specifications, standards, and software utilities that describe the technology used by Web sites. This will be a resource for future scholars in puzzling out file types and formats that have become obsolete.
7. Web Preservation at the Library of Congress
One of the aims of the Minerva prototype was to study how to integrate Web preservation with the other activities of the Library of Congress. There is not room in this paper to describe this work in any detail, but here is a short summary of two aspects, information discovery and the development of a production system. For more information, see the interim report of the project.
Information Discovery
Since very large numbers of Web sites will be collected and preserved, some form of catalog, index, or finding aid is required. Possible methods include catalog records, searchable lists of URLs, fields extracted from HTML pages, or free text indexes of home pages.
For the Minerva prototype, item level records were created following MARC 21 and AACR2 guidelines. OCLC's CORC system was used for the initial process of cataloging. If a record of the selected resource was found in CORC, then the Library of Congress's copy cataloging guidelines were followed to export as a MARC record and import into the library's Integrated Library System (ILS). If no catalog record was found in CORC, then the CORC system was used to automatically generate a preliminary record through CORC's metadata harvesting feature. Additional editing of the MARC records once imported into the ILS was a common occurrence.
The preliminary study showed that the CORC software provides a good tool for creating catalog records and that there are no fundamental obstacles to integrating such records into the ILS and the library's other procedures. However, it illustrated some peculiarities of Web sites that would need to be addressed in a production system. Close study of the original records and the constantly changing sites illustrated the need to reevaluate some of the cataloging policy.
For large numbers of Web sites, the simple and low-cost method of providing an index would be automatic indexing of home pages, as used by the Web search services. The Library of Congress expects to experiment with this approach in the near future.
The Development of a Production System
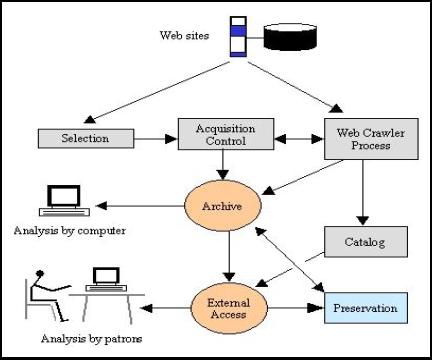 |
Figure 3. A Production System for Web Preservation
Figure 3 shows some of the many components that are needed in a production system for collecting and preserving Web materials. The Minerva prototype examined how these functions might be integrated with other activities at the Library of Congress and made some very rough estimates of volume and possible staffing requirements. It also began to examine the trade-off between those parts that might be carried out by external partners and those that most naturally should be managed in-house.
Acknowledgements
The work described in this article was carried out during summer and fall of 2000 by Roger Adkins, Cassy Ammen and Allene Hayes from the Library of Congress, with William Arms of Cornell University as consultant. Melissa Levine provided expertise on copyright and other legal issues. The team met regularly with an advisory group of Barbara Tillett, Jane Mandelbaum, and Diane Kresh from the Library of Congress.
![]() Collecting and
Preserving the Web: Developing and Testing the NEDLIB Harvester,
Collecting and
Preserving the Web: Developing and Testing the NEDLIB Harvester,
Juha Hakala, Helsinki University Library, The National Library of Finland
juha.hakala@helsinki.fi
Introduction
Historically, national libraries have assumed responsibility for preserving the published record of their countries for future generations. This mandate has been based largely on deposit laws that require publishers to submit to the national library copies of all their publications. Initially, this responsibility was limited to printed documents. More recently, legal deposit requirements have been extended to electronic publications. Unfortunately a mere change in jurisdiction is no guarantee that these resources will survive, as the methods libraries have developed for preserving printed materials are not fully applicable to electronic sources. Further, with the emergence of the World Wide Web as a principal publishing venue, national libraries have become concerned about the proliferation of cultural heritage materials available only on the Web. Some are asserting their depository responsibility to archive substantial parts of the national Web space. Due to the shear size and complexity of such efforts, however, manual means for collecting Web resources are impractical, and automated tools must be developed.
From 1997-2000, eight European countries participated in the Networked European Deposit Library (NEDLIB) Project, a collaborative effort of national libraries to construct the basic infrastructure for a networked European deposit library system for digital publications. Key research undertaken as part of this project was the development and testing of a harvester to archive Web resources. This paper presents the results of this effort and discusses the major issues in the utilisation of harvesting technology for preservation purposes.
The NEDLIB Harvester
Beginning in the mid-1990s, harvesters were developed to glean the growing content of the Web for indexing purposes. The basic technology behind the NEDLIB approach, therefore, is not new. What is distinctive about the NEDLIB harvester is that it was consciously designed with archiving in mind.
The operation of any Web harvester can be described in a few lines. A harvester is first fed a given set of links (URLs) belonging to valid starting pages for a pre-defined Web space, such as *.helsinki.fi, *.cornell.edu, or *.*.nl. These pages are fetched and analysed in order to find hyperlinks (further URLs) embedded in them. These URLs are then used to retrieve a second batch of documents, which is processed in a similar manner. This process goes on, until all documents belonging to the pre-defined area have been retrieved. With this simple method, large portions of the Web can be covered. Some argue that harvesters are being used too actively, generating a significant portion of all Internet traffic. Therefore, some sites have chosen to utilise robot exclusion rules to limit this traffic or to protect their legal interests, which some harvester developers have decided to ignore.
Harvesters usually are not designed to permanently retain the retrieved documents due to storage considerations or legal restrictions. Once an index has been created, the documents are either discarded immediately or held in a temporary cache.
The idea of using harvester technology to preserve Web content first emerged in Sweden in 1996, where the Royal Library's Kulturarw3 project began to build tools for Web archiving. Kulturarw3 is viewed as a part of the Royal Library's deposit activities. The NEDLIB project carried this deposit-based approach forward (1).
A formal assessment of existing public domain harvesters by the NEDLIB partners made it clear that the necessary technical adaptation to accommodate archiving features would be difficult to accomplish, and it might compromise the available harvesters' basic operating functions. For instance, one harvester was built to throw away URLs queued for retrieval if some pre-defined internal problems occurred. This behaviour may be acceptable when harvesting is done for indexing purposes, but for archiving this kind of technical solution—of course not mentioned in the documentation, but discovered by us in the source code—is highly problematic. Changing this feature would have required a sequence of changes in the PERL source code.
Therefore, instead of using an existing harvester, the Finnish Center for Scientific Computing (CSC) developed the NEDLIB harvester from scratch, based on the specifications written jointly by the NEDLIB partners. Had we known how difficult it would be to build a really good harvester, we might have been more forgiving of limitations in the existing tools!
The first version of the harvester was released in January 2000. All NEDLIB partners and the national libraries of Estonia and Iceland completed beta tests of the system in spring and summer of 2000. The National Library of the Netherlands developed a statistical package, which simplified the reporting of harvested materials.
During beta testing, all sites reported that the installation of the software proved quick and smooth for both the MySQL relational database server application and the harvester software. Although some partners relied on much smaller test servers than recommended, even comparatively ancient 80486-based PCs running Linux were up to the task and experienced no capacity-related problems.
A second version of the harvester was published in September 2000. Since then, more libraries, including the national libraries of Norway, Estonia, and Iceland have continued testing, and found further bugs and functional limitations. By January 2001 all known problems were fixed, and the National and University Library of Iceland went on to harvest the Icelandic Web.
It took the Library about one week to gather everything in *.*.is. In all 5,750 domains—every registered Icelandic domain in January 2001—were covered. The sweep included 565,169 documents from 1,426,371 URLs, representing approximately five URLs for each Icelander. The difference between the number of documents and URLs was mainly caused by the large number of duplicates found by MD5 checksum calculation. This may be due to the fact that servers may have many names and consequently there may be more than one URL pointing to a single resource.
The Icelandic archive represents approximately 4.4 GB when compressed with GNU zip. The compression ratio for the files was somewhere between 40% and 50%. Since Web archiving is based on the idea of storing snapshots of the Web a few times a year, the work done in Iceland showed that a modest workstation is sufficient for countries like Iceland or Finland, or organisations collecting similar amounts of files. And, given the current rate of technical development, it is quite likely that harvesting costs will remain stable despite the exponential growth of the Web.
In Finland, a small Linux workstation was capable of collecting 500,000 documents during harvester tests in Autumn 2000. Based on the NEDLIB results and Icelandic experiences, Helsinki University Library purchased in March 2001 a Sun E450 server with one 480 MHz CPU, one gigabyte of memory, and 8 x 36.4 GB disks. According to our estimates, this computer will be sufficient for harvesting the Finnish Web, provided that the files are archived on tape. As of this writing (March 2001) we plan to harvest the Finnish Web in April - May 2001.
NEDLIB harvester tests did reveal quite a few interesting problems. These were almost always related either to bad data or poorly developed HTTP server applications. Our Swedish colleagues involved with the Kulturarw3 project verified this result; having done the job many times, they knew pretty well what makes harvesting the Web a difficult enterprise.
To give you an idea of what can happen, the NEDLIB harvester once retrieved an HTML file with a large blob of binary data in it. This surprise encounter brought the early version of the harvester HTML parser module down to its knees. Needless to say, this module does not abort any more if it encounters such a file, or similar malignant cases. Another interesting problem involved a homemade HTTP server by a respectable Finnish IT company, which provided no HTTP header information, but just the bare files. Curiously enough, browsers did not have any problems with this server. Alas, any decent harvester must know if the delivery has been a success or not. Therefore, a document sent without HTTP wrapping must be discarded.
There were also problems in dealing with CGI scripts, which at times create loops—vicious circles in which the harvester demanded a single server to deliver a single document thousands of times in rapid succession. This problem was at least partially solved by enabling exclusion of CGI scripts from the set of documents to be harvested.
To sum up, it is not hard to develop a simple harvester that can retrieve a small number of documents. Developing a robust and efficient harvester that can retrieve basically any document in an open environment efficiently and effectively poses a more interesting engineering challenge. Even if you try to remember everything, something will be omitted by accident. For instance we had not taken into account the tilde character (~) in URLs, until our Icelandic colleagues complained about this limitation.
The latest version of the NEDLIB harvester will be available to the public at the CSC along with basic documentation and the MySQL database application the harvester requires. In the future, CSC and Helsinki University Library will maintain the NEDLIB harvester jointly on the basis of a mutual contract and will continue to make it available for free. Libraries and other organizations are welcome to use the harvester; the only requirement is that we would like to hear from other users' experiences and benefit from extensions other implementers make for the application.
Technical Considerations
Storage
A major consideration for any Web archiving system is storage. The NEDLIB harvester and similar archiving tools will need disk space for:
Because the Web continues to grow exponentially, there is no way to know in advance the exact size of any country's archive during a Web sweep. Experiences from Iceland, Finland, and Sweden indicate, however, that despite such growth, the national Web space remains surprisingly small. Although the number of documents may be quite large, most of them are limited in size, averaging 5 KB each. For instance, the Finnish Web in late 1998 required about 200 GB without duplicate control and compression. With the NEDLIB harvester, if the Icelandic and Finnish Web were comparable, the archive size would be about 100 GB. Our most liberal estimate is that the Finnish archive will be no larger than 300-500 GB.
In Sweden, the results of the autumn 2000 harvesting with the modified Combine harvester they use took less than two terabytes of space, although the archive contains about 20 million documents (2). Previous sweeps of the Swedish Web space were of course smaller than this. In Sweden, no duplicate control or compression was done, and each sweep contained every document present in the Web at that time. The NEDLIB harvester uses both compression and duplicate control, and relies on incremental harvesting—new sweeps only bring in new and modified documents.
The price of storing a terabyte of data on magnetic disk is still quite high. Fortunately storage technology is one of the most rapidly advancing areas of technical development, leading some to speculate that the growth of the Web will be balanced by advances in storage technology, resulting in a stable storage cost for Web archiving (3). If the price of storage does become prohibitive, national libraries can either become more selective about what they collect or turn to less expensive storage methods. Since a Web archive built by the national library is a last resort service—it is needed only when documents are no longer available anywhere else—it does not need to function very fast.
Instead of using magnetic disk, it is possible to use cheaper and slower techniques, such as optical disk or tape. An ideal solution might be a hierarchical file system, where popular or at-risk documents reside on disk, and less popular and more secure materials remain on tape. In the future even tape access, using new techniques, such as the Linear Tape Open technology (LTO, introduced by IBM) and its successors, will provide reasonable access times along with huge storage capacity.
Defining the National Web Space
In order to be able to harvest all freely available Internet resources published in a country, just retrieving everything from the country domain (e.g. .fi) is not enough. The national library or other organisation responsible for this job must also obtain valid server names from other top-level domains, such as .com or .org. There are different methods for doing this.
First, companies selling domain names, such as Domaininfo, which coordinates .com, .net, and .org for Scandinavian countries, could provide a list of valid domains. However, these companies tend to think this information is proprietary and are not likely to provide the domain list to national libraries or any other organisation asking for it, even if they had a valid need for this data.
Second, network providers can provide lists of domains their domestic customers are using. We managed to get such a list from two out of ten Finnish companies, which is not really a satisfactory result. To make things worse, at least in Scandinavia, there are no rules and regulations that would entitle the national libraries to get the domain information, so even if the data is received once, there is no guarantee that there will be any updates as the library is dependent on the good will of the company delivering the information.
Since there is no reliable way to get the domain data from networking companies, the data must be distilled from the harvested mass of documents. In Sweden, the national library uses Whois protocol for checking if a domain is Swedish or not. This simple method has proved to be efficient and reliable. By Spring 2001 more than 30,000 Swedish domains from non-country name top-level domains such as .com, .org, .net, and so on, have been proven with sufficient probability to be Swedish.
Based on the results of the Autumn 2000 sweep with the Combine harvester, approximately 40 % of Swedish public Web documents are located in domains other than .se. There is no reason to believe this ratio will be different in other countries. In the long run, due to new top-level domains approved by The Internet Corporation for Assigned Names and Numbers (ICANN) in 2001, an ever diminishing number of servers will be located in country domains. Therefore it is very important to use Whois-based tools for retrieving domestic data from all top-level domains. Providing the harvester a good list of valid pages from these domains is unfortunately not easy.
In Sweden telephone numbers, and especially the country code, are used for determining whether an owner of a domain is Swedish. In theory, the same method can be applied for doing state level harvesting in the United States. However, it remains to be seen whether a Whois-based solution would actually scale up easily in a country like the United States.
Scheduling Issues
Since the archive harvester grabs literally everything from the servers it visits, it must be well behaved. In testing, we have found that simple scheduling policies lead to a situation where towards the end of the harvesting there is only a handful of very large sites left to collect. The majority of Web servers in Finland in 1998, for example, contained only a small number of documents, but some of them already had more than 100,000 documents. If there is a fixed time between visits into each Web server, the total time needed to complete a harvesting round can be calculated with some accuracy in advance from the number of documents held in the largest Web server.
Beginning with the November 2000 version of the NEDLIB harvester, a scheduler module has been included as a small database. The system remembers the response times of all servers it has been in contact with, and based on this information, it dynamically adapts the time period between the retrieval requests sent to the same server. This method enabled us to minimize the time spent on harvesting by visiting the large and faster growing sites much more often than average sites. Of course, when the harvester is made more efficient like this, it is even more important that it behave well. This can only be guaranteed by testing the harvester in a real life environment.
Metadata
Utilizing Web harvesting technology for preservation purposes requires the development of an archive module. Its task is to generate archival metadata and to process the harvested documents so that they can be stored and indexed. Just storing the harvested files on disk is insufficient. Without harvesting related metadata, it would be impossible to determine where and when the archived documents were retrieved. Nor would it be possible to prove that the document had not been changed during the archival period, which would badly compromise its authenticity.
Although the NEDLIB harvester stores the original URLs for files as accompanying metadata, it does not rely on them to serve as unique identifiers, since over time the data content in a given location will often change or the resource may be moved to new or multiple locations. Traditional identifiers, such as ISBN or ISSN embedded in the document, cannot be used as archive identifiers either, as there may be many versions of an electronic book, each with the same ISBN. In the archive all these versions, even if the differences between them are small, have to be stored and identified separately. Therefore the harvester calculates an MD5 checksum of each file, and uses that figure as the archive identifier. In addition, this unique access key enables duplicate control and authentication.
Although duplicate documents are retrieved during harvesting, they can and actually should be removed before archiving to reduce storage needs. From the Icelandic experience we know that up to two thirds of the archives contents may be duplicates unless duplicate control is enforced. The question is, can we rely on MD5 checksum when the collection consists of hundreds of millions of documents?
Message Digest number 5 (MD5) is an Internet standard specified in RFC 1321. The MD5 value for a file is a 128-bit value similar to a checksum. Its length (conventional checksums are usually either 16 or 32 bits) means that the possibility of a different or corrupted file having the same MD5 value as the file of interest is extremely small. Thus we felt that the MD5 technique would be sufficient for duplicate control in a Web archive.
Even though duplicates are removed, a harvester should create and store a list of URLs from which the documents were originally collected. This information may be useful in many ways, not least in uncovering copyright infringements. Based on the MD5 checksums of copyrighted documents, a publisher can use the Web archive index to check if any unauthorised copies of a document have been found. More advanced linguistic methods can be applied in order to find remarkable similarities between texts.
The NEDLIB harvester also generates a time stamp, which shows the exact time the document was harvested. If the document is retrieved again from the same location and is found—on the basis of MD5—to be the same, the second time stamp is stored. The archive can then be used to verify that the document has remained unchanged and available in the Web during the period defined by the first and last time stamp. If the third harvesting round finds the document unchanged, the second time stamp is updated.
Database Considerations
Metadata produced by the NEDLIB harvester is stored in a MySQL relational database. The database and workspace reside on disk, and the harvested files are stored in a UNIX file system, either on disk or tape, depending on access time requirements. Given the rapidly escalating size of the global Web, the ability of the UNIX file system to accommodate that growth is uncertain. Within a few years, custom extensions may be necessary to handle the tens of millions of files that the domestic archive of even a small European country will contain.
The NEDLIB harvester uses TAR software to merge a configurable number of harvested documents into a single file. The archive file is compressed with ZIP software in order to save storage space. Reversing this process is relatively fast, so the response time that can be achieved with this technique is acceptable if performance is not an overriding concern. Storage technology, e.g., tape speed versus disk speed, is based on system performance rather than compression.
The archived files are not stored in a database since this would prevent the use of tape and other slow and affordable storage media. Database usage might also complicate the long-term preservation of documents, if the documents cannot be extracted from the database in original form. Using a database for storage might also become a problem if there is an inherent limit on database size or on the number of items it can hold, or limitations on file formats that can be handled. The main downside of using a file system for storing the archived documents is that a second database must be built for indexing the documents.
Indexing a Web Archive
A Web archive built with the NEDLIB harvester is not accessible as such for end users. The documents in the archive must be indexed with a text-indexing engine. This module of the Web archive was outside the scope of NEDLIB, but work for building an access module is under way.
The Nordic Web Archive is a collaborative project of the Nordic national libraries, which began in September 2000 and will run through the end of 2001. It is the biggest Nordic digital library project to date, with a total budget of 2 million Danish crowns (250,000 Euros, and approximately the same sum in US dollars. The main part of the NWA funding comes from the Nordunet2 research program.
There is nothing new about the indexing of Web documents; indeed this activity is the key function in every Web index. There are many companies developing software especially for indexing the Web (see searchenginewatch.com for a list of the most well known systems). Unfortunately, standard products are not sufficient for indexing a Web archive. The indexing application must be able to process additional metadata generated by a harvester, that is, archive identifiers, location information, and time stamps. The indexing application should also be able to cope with metadata embedded in documents, which is also saved by the NEDLIB harvester. Since the NEDLIB harvester stores all metadata into relational database tables, from which the data can be extracted as text, indexing the metadata should not be too difficult.
The NWA project did not have resources for developing a text-indexing engine of its own; our preferred choice would have been an efficient public domain application. Unfortunately, an evaluation of existing products led us to conclude that in January 2001, that the tools available were not suitable for indexing extremely large and varied document collections such as Web archives. The NWA project group decided that the best strategy would be to cooperate with an existing text-indexing engine vendor. In February 2001 the project group decided to propose to the Nordic national librarians that they cooperate with the Norwegian company FAST.
FAST has created and made available on the Web a global Web index with 575 million documents in it (see alltheweb.com). As of this writing, work is under way to extend the FAST Web index to a billion documents. Based on projected growth rates, this capacity is sufficient for indexing the Web archives for all Nordic countries now and for the foreseeable future.
The national libraries participating in the NWA project will be responsible for pre-processing the documents in such a way that the data can be fed into the indexing engine. This pre-processing will include language recognition and subsequent morphological analysis of texts, to be done by products developed by a Finnish company Lingsoft. The national libraries will also develop functionality for browsing the Web archives. Building such special functionality in-house makes it easier to change the text-indexing engine in the future, when such a change becomes necessary.
By project's end in 2002, the Nordic national libraries will have a complete tool set for harvesting, archiving, and indexing the Web. Many modules in this collection of software will be available in the public domain, but some—such as the FAST text-indexing engine and Lingsoft tools—will be commercial. Any national library planning Web harvesting must be prepared to incur some costs, but at least in the light of the NWA and NEDLIB projects these costs are manageable. Project-based cooperation in software development has helped to keep the prices under control.
Remaining Challenges
Despite all the work put into the harvester development, some problems remain. Current harvesters do not reach the deep Web—documents stored in databases. Further, there are no acceptable means for handling dynamic documents or those embedded with or dependent on auxiliary programs, such as JavaScript. As a consequence, some of the retrieved documents will lose their functionality in the archive when removed from their original environment. Although 98% of the Web consists of either HTML pages or JPEG/GIF images and is therefore easy to handle, in the future there will be more of these special kinds of Web documents.
Over time, some archived resources will become very difficult to use. For instance, applications designed for operating systems long gone or—for the users of the future—bizarre file types will pose interesting challenges. These resources can hardly be saved for future generations, except in special cases where the document is really worth the effort of converting it into a more modern format. Whether emulation can solve the problem of preserving software can't be known; on the other hand, we should not say out of hand that this method is not generally viable. Although no large emulation tests have been done yet, results from the small-scale tests in the Camileon Project and NEDLIB are encouraging.
Finally, Web archiving is not only a technical challenge, but also a copyright issue. Unless a library's right for Web harvesting is specified in law, it would theoretically need to acquire permission from authors or publishers to copy their documents into an archive. Due to the large number of rights owners, this task alone would dwarf any of the current technical impediments. National libraries that hope to archive the Web must argue forcefully for their legal right to do so. Unless this is done, highly valuable information will be lost forever even though many of the tools and resources for saving it are already available. Luckily, it seems that the new EU Copyright directive will allow Web harvesting, and the copying and migrating of electronic documents undertaken by national libraries in order to enable long-term preservation of these resources.
(1) Brewster Kahle launched the Internet Archive approximately the same time the Swedish effort began; technically and ideologically these efforts were and have since been quite separate from one another. (Back)
(2) Arvidson, Allan (et. al): The Kulturarw3 Project - The Royal Swedish Web Archiw3e - An example of "complete" collection of Web pages. Presentation in the 66th IFLA Council and General Conference, Jerusalem, Israel, 13-18 August 2000. (Back)
(3) Toigo, Jon William: Avoiding a Data Crunch. Scientific American, May 2000. (Back)
![]() Sound Practice: A Report of the Best Practices for Digital
Sound Meeting, 16 January 2001 at the Library of Congress,
Sound Practice: A Report of the Best Practices for Digital
Sound Meeting, 16 January 2001 at the Library of Congress,
Michael Seadle, Digital Services and Copyright Librarian, Michigan State
University Libraries
seadle@msu.edu
About forty people from around the country met at the Library of Congress (LC) on the last day of the American Library Association's 2001 midwinter meeting to discuss best practices for digital sound. The origins of this meeting date back at least two and a half years to an American Library Association (ALA) pre-conference on Sound in the Digital Age. Speakers at that pre-conference confirmed that there were no universally accepted standards to use in voice-digitization projects. Participants at this meeting began to hold informal dinner meetings at ALA with other library colleagues with similar interests, including those from the Council on Library and Information Resources (CLIR), the Research Libraries Group (RLG), the National Agriculture Library, and a number of universities. In December 2000, the American Folklife Center at LC co-sponsored with CLIR a conference on Folk Heritage Collections in Crisis. That conference emphasized three themes: preservation, access, and intellectual property. It also brought together people from different intellectual and social groups, among them: anthropologists and other folk life specialists, librarians and archivists, private collectors, public and private foundations, lawyers, and sound technicians. Acronym overload forced everyone to try to communicate in plain English. It was itself a truly inter-cultural exercise. Many who attended the Best Practices meeting also took part in this conference. Concurrently, the Photographic and Recording Media Committee of the Preservation and Reformatting Section (PARS) of ALA had been discussing digital reformatting for sound. At the ALA Midwinter meeting, the PARS discussion group explicitly followed up the three themes of the Folk Heritage Collections in Crisis conference.
PARS and the Best Practices meetings had similar speakers, but a somewhat different audience. The Best Practices meeting drew an audience from larger institutions that had active digitization projects, which were mainly, though not exclusively, grant funded. The mix included libraries, public radio archives, granting agencies, and others including some from the recording industry. Although the meeting was not intended as a synthesis of the previous gatherings, it did in fact pull together some broad understandings in four areas:
Through these topics run two leitmotivs. The first is the cross-disciplinary nature of this work. A huge variety of people (e.g., anthropologists, radio producers, amateur collectors) record sound. Librarians and archivists, whose jobs should not be conflated, organize and preserve it. Sound technicians filter, reformat, and otherwise manipulate it. And computer specialists manage its digital existence.
The second leitmotiv is, in a sense, the inverse of the first: isolation has plagued each collection and each institution as they try to deal with the problems of digital sound. These are not problems that can be handled alone. Unfortunately finding partners, establishing cross-institutional practices—even just setting aside the time and resources to come together to share information—is neither quick nor easy nor inexpensive.
Reformatting
Reformatting represents only one small part of the digital preservation process, but gets disproportionate attention because a mistake in reformatting lasts the life of the digital version. If a mistake is bad enough, the reformatting may even have to be repeated. The most conservative archives advise preserving the analog form just in case. Even this is not really a solution, since the impermanence of the analog versions and their steady deterioration, are reasons why people have turned to digital reformatting as a preservation measure.
None of the discussions at any of the meetings came up with a single set of numbers for digital reformatting that everyone could agree on. A sampling rate of 44.1 kHz (i.e. 44,100 samples per second), with 16 bits to represent the amplitude of each sample, is the commercial standard for digital audio. Higher end suggestions included a rate of 96 kHz / 24 bits. Others thought 48 kHz sufficed, or even lower numbers for lower quality originals. The sound technicians present generally shook their heads at questions from librarians about what number was "right." At least at present, too much depends on the analog original, and on the equipment used for the conversion. Sound is unlike image material in having an unmediated conversion from analog to digital. A vinyl record, for example, must play on a turntable before digitization. No existing process can create a sound recording directly from the record itself. The intermediate system can very greatly in quality. A worn needle, for example, will do a poor job of extracting sound, and increasing the kHz or bit depth will not compensate for poor quality sound. Moreover, a worn needle might be replaced, but each run of a needle over a vinyl recording damages the original. The problem is that each time reformatting is repeated in an attempt to capture more information there may be less information present to capture. (For collections that can afford it, new laser-based technology can replace needles.) This is a strong argument for doing it right the first time-if only we knew what that was.
The argument for deliberately higher sampling seems extremely compelling. But higher sampling has a cost, both in storage and in processing time, especially when graphical displays of the sound patterns suggest that no (apparent) extra information is being captured. Those with very small collections or greater access to funds can use higher sampling rates without serious consequences, but large collections and less well endowed institutions may face a choice between the higher sampling rates and reformatting some portion of their holdings. Falling storage and processing costs help, but dollars spent on storing data with no extra information are still wasted. For images of text, the standard has long been "full information capture." No one knows exactly what that means for sound.
Beyond the notion of full information capture is the possibility of deriving psycho-acoustical information. What can future researchers learn from subtle acoustical information hidden in ranges that humans do not consciously either hear or think about? What can they learn about the physical space in which a recording takes place? It would be interesting if such information could be used to reconstruct a room: the windows and walls, the carpets and ceilings, the tables and objects on them, the people, their clothes, their faces. Each of these things affects sound in some respect, and therefore leaves an imprint that might be used. The Vincent Voice Library at MSU has a recording of Big Ben ringing in London in 1893. The idea of using that sound to build a vivid portrait of the crowd, buildings, streets, perhaps even the air pollution of the time, seems attractive. But it may not be realistic. The original Edison recording is definitely low bandwidth and low quality. The information may just not be there to save.
Metadata
Finding a single right metadata format currently seems as chimerical as a single right sampling rate. What is right depends on the collections, the uses, and the costs involved. Ultimately the ability to map from one format to another is what matters, as the experience of the American Memory Project has shown. That sort of mapping is not always easy, but with certain standardized formats, such as Encoded Archival Description (EAD) and Dublin Core (DC), many of the mapping issues have been worked out.
Those at the meeting who used DC expressed a strong need for item level access, and somewhat less concern for grouping items into definable collections or sub-collections. There seemed also to be more uniformity of size and type among their materials. DC is cheaper to work in than MARC (MAchine Readable Cataloging) because of its limited element set. The elements also have pre-defined relationships to the fields of a basic MARC record. Minnesota Public Radio has chosen DC as its metadata standard.
Those who used EAD wanted to organize items into collections and sub-collections, and saw the items less as the equivalent of monographs than as chapters in a book or articles in a journal. A lack of uniformity of size and type within a collection also made EAD attractive: a thirty second sound bite might not deserve the same level of description as a two-hour interview. EAD is also cheaper to work in than MARC, because large numbers of items can be grouped. All the radio addresses of Franklin Roosevelt, for example, can be listed by date without repeating the bibliographic information that is inherited from the collection-level portion of the EAD record. Unfortunately, the EAD to MARC mapping is less well established than for DC. Michigan State University (MSU) has chosen EAD as its metadata standard, and has been working with its automation vendor, Innovative Interfaces Inc., to develop a mapping tool using the attribute to specify how tags match particular fields and subfields.
Not every institution has made a single choice. Indiana University, which owns particularly rich collections of music, has chosen EAD for some projects, and DC for others. MPEG-7, which is poised to be a standardized description standard for various types of multimedia information, was not discussed at the conference.
Data Management Practices
The preservation issues change radically once the sound is in digital form. The focus shifts from how to make a quality copy to how to manage the digital stream of ones and zeros in order to make sure that the information they represent can be accessed and interpreted at an undefined point in the future. This is certainly not the only preservation issue for digital materials. Authenticity and integrity matter too, but they are relevant only if the bit-stream produces something worth authenticating.
Simple housekeeping functions become complex with large numbers of files. Files all too easily become lost, especially if naming conventions are inconsistent or changing. Separating masters from service copies can help. Databases can help. Systematic procedures make a difference. None of this seems like preservation, but it matters as much as knowing which shelf a rare book sits on in a library with multiple millions of volumes. A reasonably stable URL would help too, but none of the projects to develop such a creature have met with sufficient acceptance to date.
Neither CDs nor magnetic tapes meet reasonable requirements for long-term storage. One sound consultant estimated a ten-year rolling window for off-line storage, not just because of flaws in the physical media, but also because of changes to software drivers and hardware readers. The real archival long-term storage is the online copy, which is refreshed regularly (along with other things) to new media, and which might be used often enough that software access problems would be noticed too (solving them could be quite another matter). The offline copies are only backups, a kind of emergency storage not to be trusted indefinitely. Just as with the preservation of print works, multiple copies matter. The more servers that have copies of a digital work, the less likely it is that every copy will die simultaneously. In the digital world, sharing is a form of preservation.
Intellectual Property
The copyright issues for sound are more complex than for printed works. In part this is because recorded sound technology is so relatively new that no large body of pre-1923 public domain materials exists. Musical recordings generally have multiple copyrights, and the music industry has a level of organization that facilitates policing putative violations. Special sections of the law deal with rights to the underlying musical composition, lyrics, the performance, and even the production. Copyright in the recording itself (as opposed to the words or music) dates in federal law only from 1972. This fact led to a discussion at the Best Practices meeting about whether pre-1972 recordings could be considered unpublished works (even if broadcast or sold), and therefore qualify for the same 95 year or life-plus-seventy protection as pre-1978 unpublished papers. Much depends on an institution's interpretation of the legal definition of "published." And the legal definition does not necessarily match what seems intuitively obvious.
Institutional policy varies enormously on copyright. The Library of Congress has taken a conservative approach in following the letter of the law and not taking risks. Some universities have taken a more assertive stand, and are willing to argue legal access issues for the public good. Small collections can be as vulnerable as large ones. Seeking or renegotiating permissions is one way to handle the copyright issue, but the process is neither quick nor cheap. Rights owners can be hard to find, especially for older materials, and the owners can simply say no, or charge impossible amounts for permissions. Although the Digital Millennium Copyright Act does allow certain kinds of libraries to make digital preservation copies under certain circumstances, it does not authorize broadcasting of those copies on the Web.
Next Steps
Education represents the closest approximation to a solution that this or any of the previous meetings discovered. Having those involved with digital sound and sound preservation share information at periodic meetings has a definite educational value. The variety of answers and approaches to the problems offers a range of options for new projects. They may not be "best practices" in the strictest sense, but they have the virtue of working, and are arguably the best that anyone has to offer at this point. It may be that a kind of market clearing will take place where some current practices will be discarded and others agreed upon. Of course there is no guarantee that the market will settle on the highest quality solutions. Best practices represent a balance of economic, technological, and legal factors.
Publications are part of the educational process, too. The Research Libraries Group (RLG) is preparing a manual on magnetic and optical media preservation that will contribute substantially to understanding the technical issues on that important aspect of the subject. This manual is expected to be published later this year. The white paper from the Folk Heritage Collections in Crisis conference will also soon be available from CLIR. As a result of the meeting at ALA, the PARS committee has mounted a variety of audio preservation resources on the Conservation Online (COOL) Website.
Other suggestions for education include a road show on the model of the School for Scanning for image-based materials. This proposal would take substantial further development, but offers a chance to get reliable information out to those archives, libraries, and even private collectors who have an interest in digital sound, but lack the resources or interest to attend national meetings.
Conclusion
The meeting did not really end with conclusions. The impression that I have had from all three gatherings over the last several months is more one of beginnings than endings. I am among those who have long felt that digital reformatting represents the only viable long-term solution for sound preservation. Analog copying merely degrades the quality of the recordings and probably only pushes the problem a few decades into the future. At best it buys time for standards development and cheaper capture. Friends and colleagues have persuaded me that major digitization issues remain to be solved, not all of which were discussed at these meetings or in this article. But these discussions have encouraged me that solutions can exist, if only in embryo form, in the practices and experiences, the mistakes and happy discoveries, of projects going on today. The process may be a long way from recommending an unambiguous set of standards to NISO, but it has come far from that primitive state of nature in which each collection needs its own Prometheus.
|
Highlighted Web Site Cultivate Interactive
|
FAQ
Q. "I've heard that The Andrew W. Mellon Foundation has funded a number of archiving projects for scholarly journals in digital form. Is there any information available on these projects?"
In December 2000, The Andrew W. Mellon Foundation launched the Mellon Electronic Journal Archiving Program, a one-year effort to plan the development of digital archives for long-term retention of scholarly journals in digital form. Seven institutions received grants to design trusted archives for a wide spectrum of journal holdings. Yale, Harvard, and the University of Pennsylvania will focus on developing comprehensive strategies for archiving journals produced by large publishers. By contrast, Cornell and the New York Public Library will focus on archiving journals representing particular scholarly disciplines. MIT will explore the problem of archiving "dynamic" electronic journals, whose content is not fixed in time like a traditional serial publication. Finally, Stanford will contribute software for a distributed digital preservation system. The Digital Library Federation will provide access to reports and working papers for the program, along with links to individual project sites.
The Mellon Electronic Journal Archiving Program builds directly upon an earlier initiative, sponsored by CLIR, DLF and CNI, in which a group of research libraries and publishers defined a set of minimum criteria for preserving digital journals for at least 100 years. This effort set forth a number of research issues, some of which are being addressed in the Mellon-funded projects. One critical task is to apply the minimum criteria in developing archiving strategies and in designing trusted repositories for digital content.
Another important task in archiving electronic journals is to set the mission of a repository in a way that explicitly identifies the scholarly communities it will serve and the preservation responsibilities it chooses to undertake. Participants in the Mellon initiative will work with publishers to establish routine deposit agreements that will govern the acquisition of specific resources, as well as preservation and access rights. Planning for secure repositories may include developing standard procedures and specifications for storing and preserving files along with preservation metadata. Access concerns will also be addressed, including the question of whether permission can be obtained to permit wide access to archived material, or whether it will be necessary to build "dark archives," providing limited access.
Harvard's contribution to the Mellon initiative will be a comprehensive plan to archive the journal holdings of at least one large "core tenant" publisher. The library will develop archival methods for validating files, organizational and business models, and a technical plan for implementing and expanding the archive. The library also plans to select a number of born-digital publications for archiving on a case-by-case basis, rather than through across-the-board agreements with publishers. Contact Dale Flecker for more information on Harvard's project.
The University of Pennsylvania will collaborate with at least two major university presses, building on the library's experience with an ongoing electronic books project that has included work on data migration for long-term preservation. Initially, Penn intends to build a prototype archive around a broad range of born-digital content, with a partial focus on lowering per-volume archiving costs through automation. The library's proposed architecture will also be designed to integrate materials converted from print sources. The Penn project is being directed by John Ockerbloom (For a discussion of some of the technical issues Penn and other participants are addressing, see John M. Ockerbloom "Archiving and Preserving PDF Files" in RLG DigiNews (February 2001).
Yale will work with Elsevier Science to explore a set of core issues in the development of a model archive for the publisher's approximately 1,100 electronic titles. Elsevier Science will supply SGML versions of recent (since 1998) materials, along with image-based file formats (TIFF and PDF) for earlier content, along with all metadata directly associated with these materials. Among other issues, Yale will examine the nature of "triggering events" that could result in the transfer of control of content from publisher to archival agent. In general, Yale's planning efforts will draw upon traditional archival theory to define the organization and potential uses of a digital archive. Paul Conway is coordinating the Yale project.
Cornell's contribution will be Project Harvest, in which the library will focus on archiving agriculture journals in electronic form. This project, led by Peter Hirtle, builds on Cornell's leading role in preserving and providing access to agriculture literature, in part through its work with USAIN (United States Agricultural Information Network, which oversees the National Preservation Program for Agricultural Literature . Through negotiations with publishers, the library will create a model agreement for the deposit of scholarly journals in agriculture and other scientific disciplines. Planning will be carried out on the technical design for a repository, and an organizational model will be developed for managing electronic resources over time. By basing its planning on journals in a particular subject area, Cornell expects to work with a wide range of publishers and a variety of file formats. This focus will also enable the library to investigate issues related to scholarly acceptance of an electronic journal archives.
The New York Public Library will concentrate its planning efforts on archiving journals in the performing arts, one of the library's historic strengths, along with related fields such as history and media studies. Building a trusted repository for these fields will require working with small, independent publishers--in some cases individuals or small groups of scholars--as well as more established organizations worldwide. Another challenge to be addressed in archiving performing arts journals is the common use of embedded multimedia and extensive links to other Web resources, and the relative importance of "ephemera" that may be difficult to preserve alongside conventional text-based HTML pages. Contact Jennifer Krueger for more information on this project.
MIT will explore issues related to archiving "dynamic e-journals," which the project classifies as a new type of on-line knowledge environment that provides access to a variety of information resources to specific user communities. Unlike traditional journals, the content found in dynamic e-journal sites is routinely updated, and does not follow the print convention of being organized in distinct issues fixed in time. Archiving such sites will entail choosing strategies for preserving different classes of digital files, setting schedules for capturing content at regular intervals, appraising materials for long-term retention, and deciding how much of the user experience or "look and feel" should be preserved in addition to the basic data. The library will work with MIT Press and other dynamic e-journal publishers on these issues. The Project Director is Carol Fleishauer.
Stanford's role in the Mellon initiative is to conduct a large-scale beta test of LOCKSS (Lots Of Copies Keep Stuff Safe). LOCKSS is an open-source digital preservation appliance designed to enable libraries to take custody of the web-published journal volumes to which they subscribe. Each LOCKSS system behaves as a Web cache that selectively acquires and retains the content the library wishes to preserve. The distributed LOCKSS caches cooperate to detect and repair damage to particular files. The system is designed to be a practical and reliable way for libraries to ensure access to born-digital content. Contact Vicky Reich for additional information.
![]()
Calendar of Events
Digital Preservation in Practice Workshop
April 25, 2001, London, UK
The long-term preservation and continuing accessibility of digital materials
is a growing area of concern for many research libraries and repositories. The
workshop will be of interest to those currently archiving digital materials.
For further information contact: Dr. Stewart Granger, CAMiLEON UK Project Coordinator,
stewartg@dial.pipex.com.
Intellectual
Property In The Digital Environment: Exploring The Possibilities
May 6-9, 2001, Madison, WI
The University of Wisconsin-Madison Law School and School of Education
will co-sponsor an intellectual property conference that will address issues
such as copyright and the Internet, fair use in cyberspace, and copyright infringement
and digital technologies.
Open Archival
Information System (OAIS) Workshop
May 14-16, 2001, San Francisco, CA
Many libraries and archives are now using the Reference Model for an Open
Archival Information System (OAIS), which is used for management of large-scale
digital repositories. This workshop will explore and study its use.
Moving
Theory Into Practice Workshop
October 1-5, 2001, Ithaca, NY
Registration opens June 4, 2001, 12:00 noon EST
Offered by the Cornell University Library, Department of Preservation and
Conservation, this workshop series aims to promote critical thinking in the
technical realm of digital imaging projects and programs. The National Endowment
for the Humanities funds the workshop.
Preservation in the Digital Age
May 27-30, 2002, Paris, France
Call for papers deadline: June 15th, 2001 The Fourth Association pour la
recherche scientifique sur les arts graphiques (ARSAG) International Symposium
will focus on the relationships between digitization and preservation of cultural
heritage materials. Papers are being solicited on the following topics: policy,
implementation and economics of digitization of collections; preservation, conservation,
and digitization of collections; preservation of traditional materials. For
further information contact: Françoise Flieder - Sibylle Monod, ARSAG, monod@mnhn.fr.
Digital Cultural Heritage III:
Finding Aids and Analysis Tools in Archives and Memory Institutions
July 11-14, 2001, Maastricht, The Netherlands
This seminar is concerned with integrating developments in finding aids
(virtual reference rooms) with innovations in text and other analysis tools
that will allow varied and rich access to cultural and historical information.
Digitisation
for Cultural Heritage Professionals
July 15-20, 2001, Glasgow, Scotland
The Humanities Advanced Technology and Information Institute (HATII) announces
the fourth annual international Digitisation Summer School. This course, designed
for archive, library, and museum professionals, delivers skills, principles,
and best practices in the digitisation of primary textual and images resources,
with a strong emphasis on interactive seminars and practical exercises.
Digital Resources for the Humanities
Conference
July 8-10, 2001, London, England
This is the major forum for all those involved in, and affected by, the
digitization of our cultural heritage. Papers at the conference include, managing
the digital environment, visualization of data, and how to develop worldwide
access to digital resources.
DELOS International Summer
School on Digital Library Technologies
July 9-13, 2001, Pisa, Italy
The DELOS Network of Excellence is announcing its first International Summer
School on Digital Library technologies. The school will focus on fundamental
issues related to the multidisciplinary area of digital libraries.
Announcements
Report on Preserving
Digital Image Collections at Cornell University Library
Cornell University Library has produced the first of a two-part report on depository
guidelines for digital image materials. This work has been funded in part by
the Institute for Museum and Library Services. The first section outlines requirements
for those wishing to transfer digital image resources to the central depository,
and covers selection criteria, legal issues, technical imaging requirements,
metadata, and storage. The second part of this report will detail the role and
responsibilities of the central depository staff. This section will be available
in fall 2001. Cornell welcomes comments
and suggestions on part one of the report.
AHDS
Case Studies Collection
New examples of good practice in digitization are now available from the
Arts and Humanities Data Service. Included is the Digital Image Archive of Medieval
Materials, a project to digitize and restore fragments of medieval polyphony,
the digitization of the Suffragette Banners, and the literary collections of
Charles Darwin and James McNeill Whistler.
The
Evidence in Hand: the Report of the Task Force on the Artifact in Library Collections
This report on the importance of the artifact in library collections, written
by a task force of scholars, librarians, and archivists, is designed to address
the critical need to preserve the valuable evidence of artifactual material
held in research institutions. As the volume of information collected by libraries
grows, and with it the demand for electronic resources, so does the demand by
scholars to access original, unreformatted resources. Libraries are caught between
building digital collections and infrastructures, and the increasing preservation
need of many print and audiovisual resources. The Council on Library and Information
Resources welcomes public comments on this report.
SCHOLNET and CYCLADES
The European Research Consortium for Informatics and Mathematics Digital Library
Working Group provided the framework for two Digital Library (DL) projects funded
under the Information Society Technologies Programme. SCHOLNET aims to develop
a DL test bed, providing a set of specialized services to meet the requirements
of networked scholarly communities. It will support textual services and non-textual
data types. The main objective of CYCLADES is to develop advanced Internet accessible
mediator services to support scholars both individually and as members of networked
communities when interacting with large interdisciplinary electronic (e-print)
archives.
CAMiLEON Project:
Creative Archiving at Michigan and Leeds: Emulating the Old on the New
Funded under the Joint Information Systems Committee (JISC) and the National
Science Foundation (NSF) International Digital Libraries Programme, the CAMiLEON
Project is investigating emulation as a strategy for the long-term preservation
of and continuing access to digital materials. Papers on emulation and data
migration are now available.
United
Kingdom Digital Preservation Coalition Meeting Papers Now Available
In January 2001, a summit meeting was held to discuss forming a UK digital preservation
coalition. Now available is a discussion paper on the coalition, list of attendees,
and the report from the meeting.
Archiving
Web Resources: Guidelines for Keeping Records of Web-based Activity in the Commonwealth
Government
The National Archives of Australia has released guidelines that establish the
archives policy on the status and management of Commonwealth Government Websites
and other online resources as Commonwealth records.
The Metadata
Engine Project (METAe) Newsletter Now Available
This European project is working on developing software that will automatically
generate metadata during the digitization of printed material. The goal is to
make large-scale digitization of printed material, such as books and journals,
more reliable in terms of digital preservation, more cost-effective in terms
of automation, and more user-oriented in terms of future applications.
The Visual Arts
Data Service New Projects
The Design Council Archive online image collection and the London College of
Fashion College Archive are part of the JISC Image Digitisation Initiative (JIDI).
This is a contribution to the ongoing effort to make accessible important collections
of value to historians and scholars.
Digital
Information Infrastructure and Preservation Program
The Library of Congress has received funding by the U. S. Congress to develop
a national program to preserve the burgeoning amounts of digital information,
especially materials that are created only in digital formats, to ensure their
accessibility for current and future generations.
RLG News
In the last issue, the RLG News provided an update on two major activities within its digital preservation initiative. The two activities—the OCLC/RLG Working Group on Preservation Metadata for Long-Term Retention and the RLG/OCLC Working Group on the Attributes of a Digital Archive for Research Repositories—use the emerging international standard of the Reference Model for an Open Archival Information System (OAIS) as the foundations for their respective work. As work moves forward on the joint working groups, so too does the work on the Reference Model.
RLG, OCLC, many members of our respective organizations, and several groundbreaking international projects have played key roles in shaping the reference model and in adapting the reference model for use in libraries, archives and research repositories. The next few months provide an excellent opportunity for those interested in digital archives and digital preservation to also play a role in these important activities. Here are a few opportunities in which you can take part:
As always, comments or questions regarding these initiatives can be sent to Robin Dale, RLG or Meg Bellinger, OCLC.
Hotlinks Included in This Issue
Feature Article 1
William
Y. Arms, Web Preservation Project: Interim Report http://www.cs.cornell.edu/wya/LC-web/interim.doc
George W. Bush http://www.georgewbush.com/
HTTrack http://httrack.free.fr/
editors'
interview with Colin Webb http://www.rlg.org/preserv/diginews/diginews5-1.html#feature1
Internet Archive http://www.archive.org/
Kulturarw3
http://www.ifla.org/IV/ifla66/papers/154-157e.htm
Minerva http://www.loc.gov/minerva/
National Library of Australia
http://www.nla.gov.au/
National Library of Sweden
http://www.kb.se/eng/kbstart.htm
National Research
Council, A Digital Strategy for the Library of Congress http://www.nap.edu/books/0309071445/html/
The National Research
Council, The Digital Dilemma http://www.nap.edu/html/digital_dilemma/
Pandora http://pandora.nla.gov.au/pandora/
Section
407 http://www.law.cornell.edu/copyright/copyright.act.chapt4.html#17usc407
Web Characterization Project
http://wcp.oclc.org/
OCLC's Cooperative Online Resource
Catalog http://www.oclc.org/corc/
The White Hourse http://www.whitehouse.gov/
Feature Article 2
All the Web http://www.alltheweb.com/
Avoiding
a Data Crunch. Scientific American, May 2000 http://www.sciam.com/2000/0500issue/0500toig.html
Camileon
project http://129.11.152.25/CAMiLEON/dh/ep5.html
Center for Scientific Computing:
http://www.csc.fi/english/
Domaininfo http://domaininfo.com/
FAST http://www.fast.no
GNU zip
http://www.gnu.org/software/gzip/gzip.htm
Internet Corporation for Assigned
Names and Numbers http://www.icann.org/
Internet Archive http://www.archive.org/
Internet standard
RFC 1321 http://www.isi.edu/in-notes/rfc1321.txt
Linear Tape
Open http://www.storage.ibm.com/hardsoft/tape/lto/
Lingsoft http://www.lingsoft.fi/
Message Digest
number 5 http://www.isi.edu/in-notes/rfc1321.txt
MySQL http://www.mysql.com
National and University
Library of Iceland http://www.bok.hi.is/english/index.html
National Library of
the Netherlands http://www.kb.nl/index-en.html
Networked European Deposit Library http://www.kb.nl/coop/nedlib/
NEDLIB
Emulation Preservation Report http://www.kb.nl/coop/nedlib/results/emulationpreservationreport.pdf
NEDLIB harvester
http://www.csc.fi/sovellus/nedlib/
Nordic Web Archive http://nwa.nb.no/
Nordunet2 http://www.nordunet2.org/
Presentation
in the 66th IFLA Council and General Conference, http://www.ifla.org/IV/ifla66/papers/154-157e.htm
Royal
Library's Kulturarw3 project http://kulturarw3.kb.se/html/kulturarw3.eng.html
Search Engine Watch
http://www.searchenginewatch.com/
Whois
http://www.washington.edu/nic/addresses/whois.html
Conference Report
American Memory project
http://memory.loc.gov/
CLIR http://www.clir.org/
Conservation
Online http://palimpsest.stanford.edu/bytopic/audio/
Digital Millennium
Copyright Act ftp://ftp.loc.gov/pub/thomas/cp105/hr796.txt
Dublin Core http://dublincore.org/
Encoded Archival Description
http://www.loc.gov/ead/
Innovative Interfaces Inc. http://www.iii.com/
laser-based technology http://www.elpj.com/main.html
MPEG-7 http://www.darmstadt.gmd.de/mobile/MPEG7/
Research Libraries Group
http://www.rlg.org/preserv/
Highlighted Web Site
Cultivate Interactive
http://www.cultivate-int.org/
FAQ
Archiving
and Preserving PDF Files http://www.rlg.org/preserv/diginews/diginews5-1.html#feature2
Digital
Library Federation http://www.clir.org/diglib/preserve/presjour.htm
LOCKSS http://lockss.stanford.edu
minimum
criteria http://www.clir.org/diglib/preserve/criteria.htm
MIT http://libraries.mit.edu/admin/mellon.html
National
Preservation Program for Agricultural Literature http://preserve.nal.usda.gov:8300/npp/presplan.htm
Calendar of Events
DELOS International Summer
School on Digital Library Technologies http://www.ercim.org/delos
Digital Cultural Heritage III: Finding
Aids and Analysis Tools in Archives and Memory Institutions http://www.amsu.edu/
Digital Resources for the Humanities
Conference http://www.drh.org.uk/
Digitisation
for Cultural Heritage Professionals http://www.hatii.arts.gla.ac.uk/DigiSS01/
Intellectual Property
In The Digital Environment: Exploring The Possibilities http://ipconference.education.wisc.edu
Moving
Theory Into Practice Workshop http://www.library.cornell.edu/preservation/workshop/
Open Archival
Information System (OAIS) Workshop http://www.ccsds.org/meetings/iws2001spring/
Announcements
AHDS
Case Studies Collection http://ahds.ac.uk/casestudies/casestudies.html
Archiving
Web Resources: Guidelines for Keeping Records of Web-based Activity in the Commonwealth
Government http://www.naa.gov.au/recordkeeping/er/web_records/intro.html
CAMiLEON Project: Creative
Archiving at Michigan and Leeds: Emulating the Old on the New http://www.si.umich.edu/CAMILEON/
CYCLADES http://www.iei.pi.cnr.it/cyclades
Digital Information
Infrastructure and Preservation Program http://www.loc.gov/today/pr/2001/01-006.html
The
Evidence in Hand: the Report of the Task Force on the Artifact in Library Collections
http://www.clir.org/activities/details/artifact-docs.html
The Metadata Engine
Project (METAe) Newsletter Now Available http://heds.herts.ac.uk/METAe/news.htm
Report on Preserving
Digital Image Collections at Cornell University Library http://www.library.cornell.edu/imls/
SCHOLNET http://www.ercim.org/scholnet
United
Kingdom Digital Preservation Coalition Meeting Papers Now Available http://www.jisc.ac.uk/dner/preservation/dpcintro.htm
The Visual Arts Data
Service New Projects http://vads.ahds.ac.uk/search.html
RLG News
Cedars Project http://www.leeds.ac.uk/cedars/
comments
http://ssdoo.gsfc.nasa.gov/nost/isoas/isoas_feedback.html
Consultative Committee on Space Data
Systems (CCSDS) http://www.ccsds.org/
International Organization for Standardization
(ISO) http://www.iso.ch/
National Aeronautics & Space Administration
(NASA) http://www.nasa.gov/
National Library of Australia
http://www.nla.gov.au
new
draft of the OAIS Reference Model http://ssdoo.gsfc.nasa.gov/nost/isoas/us19/650x0_20010226.pdf
OCLC/RLG
Working Group on Preservation Metadata for Long-Term Retention http://www.oclc.org/digitalpreservation/wgmetadata.htm
Preservation
Metadata for Digital Objects: A Review of the State of the Art http://www.oclc.org/digitalpreservation/presmeta_wp.pdf
Registration
http://www.ccsds.org/meetings/iws2001spring/
RLG/Commission on Preservation
and Access Task Force on Archiving of Digital Information http://www.rlg.org/ArchTF/
RLG/OCLC Working
Group on the Attributes of a Digital Archive for Research Repositories http://www.rlg.org/longterm/attribswg.html
![]()
Publishing Information
RLG DigiNews (ISSN 1093-5371) is a newsletter conceived by the members of the Research Libraries Group's PRESERV community. Funded in part by the Council on Library and Information Resources (CLIR) from 1998-2000, it is available internationally via the RLG PRESERV Web site (http://www.rlg.org/preserv/). It will be published six times in 2001. Materials contained in RLG DigiNews are subject to copyright and other proprietary rights. Permission is hereby given for the material in RLG DigiNews to be used for research purposes or private study. RLG asks that you observe the following conditions: Please cite the individual author and RLG DigiNews (please cite URL of the article) when using the material; please contact Jennifer Hartzell at jlh@notes.rlg.org, RLG Corporate Communications, when citing RLG DigiNews.
Any use other than for research or private study of these materials requires prior written authorization from RLG, Inc. and/or the author of the article.
RLG DigiNews is produced for the Research Libraries Group, Inc. (RLG) by the staff of the Department of Preservation and Conservation, Cornell University Library. Editor, Anne R. Kenney; Production Editor, Barbara Berger Eden; Associate Editor, Robin Dale (RLG); Technical Researchers, Richard Entlich and Peter Botticelli; Technical Assistants, Carla DeMello, Robert S. Glase.
All links in this issue were confirmed accurate as of April 13, 2001.
Please send your comments and questions to preservation@cornell.edu.
![]()