



- Feature Articles
- 3D Culture on the Web, by Tony Gill
A Project on Preservation of Digital Data, by Raymond A. Lorie
- Highlighted Web Site—Shortcourses
- Calendar of Events
- Announcements
![]()
3D Culture on the Web
Tony Gill
Program Officer, Research Libraries Group
tony.gill@notes.rlg.org
Unflattening the World
The physical world that we live in has three spatial dimensions. Consequently, we have evolved with sophisticated sensory capabilities that allow us to perceive three-dimensional objects in three-dimensional spaces. Without these 3D capabilities, even simple tasks like navigating through an apartment would be extremely challenging, let alone more complex tasks such as hunting for food, building a shelter, or driving a car.
However, although most of us are fortunate to have these 3D sensory capabilities, we tend to view the world beyond our immediate surroundings through small, essentially flat, two-dimensional windows, such as televisions and computer screens. Clearly, this two-dimensional, smaller-than-life view of the world is not making the best use of our sensory capabilities. We are not getting all the sensory information, and so we are not having the most accurate, realistic, and compelling experiences.
As any science fiction fan will tell you, the notion of a fully immersive, lifelike simulated experience that is indistinguishable from "real-life" is not a new one, and was certainly around long before William Gibson coined the phrase "cyberspace" in Neuromancer (1) and "holodecks" became standard issue on Federation starships (2). As far back as the mid-seventeenth century, the French philosopher, scientist and mathematician René Descartes postulated the notion that the senses could, in theory, be completely fooled by a "malignant demon," (3) and that therefore everything we learn through our sensory apparatus should be treated as suspect. This notion is the basis for the philosophical method of inquiry known as Cartesian Skepticism, and more recently formed the basis for the plot of The Matrix (4). Descartes was also the originator of the Cartesian coordinate system, which provides the mathematical foundations of 3D graphics!
However, since it's currently not possible to pick up a holographic projector at the mall, or download sensory experiences directly into our brains, we're stuck with trying to simulate the most realistic 3D experience possible in an essentially two-dimensional format.
This article outlines some of the potential benefits of using 3D imaging to present cultural information over the World Wide Web, highlights a few examples, provides a brief overview of the enabling technology landscape, and concludes with some forecasts for the medium-term future. It does not attempt to cover more specialized applications or technologies, such as Geographic Information Systems (GIS), Computer-Aided Design and Manufacturing (CAD/CAM), 3D animation for commercial film and television, or immersive Virtual Reality (VR) hardware such as spatially-aware data goggles or data gloves.
Cultural Applications of 3D
Most "memory institutions," such as museums, libraries and archives, have missions to both preserve and provide access to the collections in their care—missions that are not, in general, mutually compatible. One of the most compelling arguments for digitizing collections is that it helps institutions to address this dilemma; in theory, by putting digital representations of collections online, they can provide cheap, global access, 24/7/365, without any preservation risks whatsoever. Of course, this begs the question about the effect online collections access has on the level of demand for physical access, but the verdict is still pending on that debate.
Clearly, for online collections to be useful, they must support the research needs of those who want access to them. This means that the digital representations of the items in the physical collection must contain enough detail to support the kinds of research that are required. This is relatively straightforward for many types of research using flat collections such as photographs or manuscripts, which can often be supported by good quality 2D digital images, because the images are sufficiently good reproductions that they can act as surrogates of the original for research purposes.
However, digital images are less effective as surrogates for three-dimensional collections, because so much spatial information has been lost. The whole dimension of depth (the elusive z-axis) cannot be encoded in the surrogate, so the three-dimensional form of the object or space has to be flattened onto a two-dimensional view from a single perspective. In computer graphics the distinction between an object and a space is really just a matter of your point of view.
Multiple 2D views can often help, and can even be used to simulate a 3D experience. For example, this QuickTime VR movie from the National Museum of the American Indian's Creation's Journey exhibition allows the object, an Inka goblet in the shape of a jaguar's head, to be rotated 360° and tilted by 90°, allowing the viewer to see the shape and overall design of the goblet and how it is constructed by stitching together multiple pieces.

However, although this type of simulated 3D works well for some applications, it only provides limited navigation, and does not allow the physical form and dimensions of the object to be digitally captured in detail. This requires a geometrically accurate model of the object or space in three dimensions, along with information about the colour and texture of the various surfaces.
In order to see a 2D projection of the 3D scene on the computer screen, one or more light sources and viewpoints also need to be added to the model before it can be rendered in a process known as "ray tracing." Ray tracing is a computationally intensive process, in which the path of every single ray of light is traced from the light source(s) as it reflects off or refracts through each of the surfaces in the model, until it eventually reaches the viewpoint or camera.
There are many different types of ray tracing techniques that offer varying degrees of realism, but the cost of additional realism is invariably longer rendering time. Simple 3D scenes created using relatively unsophisticated rendering algorithms can be generated quickly enough to produce real-time animation on current personal computer hardware, a technique used to good effect in games like Doom and Quake (5). However, to generate more complex scenes to a level of realism that is virtually indistinguishable from reality (for example, in the production of movie special effects), more powerful computers need to crunch the numbers for longer periods of time. Some images can take hours or even days to render, which is one of the reasons movie special effects are so expensive.
Perhaps the most immediately compelling example application of 3D modeling is in the field of archaeology, a discipline that involves irreversible processes, such as excavations, in which spatial coordinates in three dimensions are of key importance. For example, information about the location at which items are discovered is often vital when building a case for a particular interpretation or reconstruction of the site. Normally the excavation process itself requires that the items be removed. In short, archaeological research often results in the destruction of the site being researched, and so it is of paramount importance to capture as much spatial information as possible at the time of the dig.
Unsurprisingly, archaeologists have taken advantage of GIS, or Geographic Information Systems, and 3D modeling tools to help them record information about archaeological sites. Later, these models can also be used as the basis for reconstructions of habitats long since eroded.
Using these 3D modeling techniques, complex virtual worlds can be constructed that contain representations of both objects and their contextual environments, which may be prohibitively remote or hazardous to experience first hand. For example, marine archaeologists could go for a virtual scuba dive around the ruins of an underwater city without getting their feet wet, and an economy-class space tourist could spend some time aboard the International Space Station without having Dennis Tito's vacation budget.
Since there is no requirement that the virtual world mimic the real world, objects, structures, and environments can be virtually reconstructed, allowing hypotheses about form and function to be explored in a shared, networked environment. The Museum of Reconstructions, for example, is a non-profit corporation that "uses computer modeling technology to develop accurate and complete reconstructions of buildings, artworks, artifacts, and sites," although currently their Web site only provides 2D renderings of their 3D models.
Similarly, environments that have never existed physically can be created as 3D models to provide an appropriate conceptual or architectural environment. The Virtual Museum of Arts El Pais, for example, places digital images of contemporary Uruguayan art in a virtual museum that was designed by professional architects, but will never actually be constructed due to prohibitive cost. Again, the Web presentation is based on a series of linked 2D images generated from a 3D model, but it is sufficient to illustrate the principle.
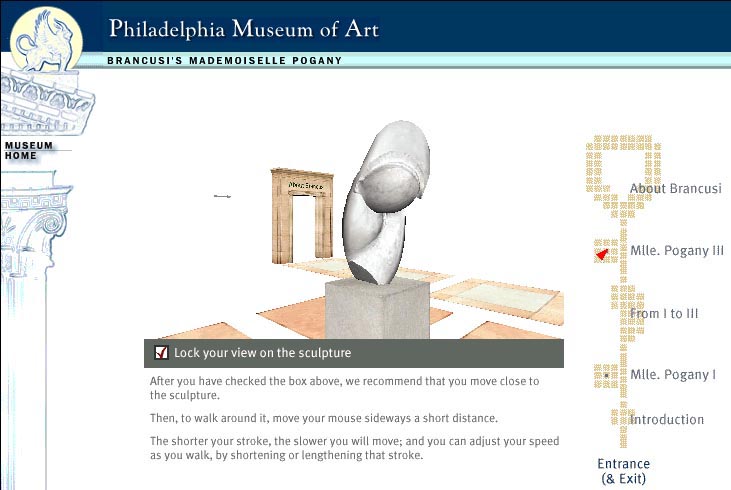
The Philadelphia Museum of Art, on the other hand, has used VRML to create "an online exhibition in three dimensions," Constantin Brancusi's Mademoiselle Pogany. This exhibition is a genuine 3D world that places two of Brancusi's sculptures in an ethereal gallery space without visible walls, and allows the visitor to navigate through a series of text panels before "walking" around 3D models of the sculptures themselves. A two-dimensional map with a "You Are Here" marker helps to orient the visitor. A VRML browser plug-in, such as Cosmo Player, is needed to view the VRML presentation:
3D modeling also opens the door to virtual repatriation, allowing cultural artifacts that have been dispersed around the world to be returned, in virtual form at least, to their original settings and cultures. Additionally, the objects in the virtual world can be programmed with behaviours, so that the user can interact with them in ways that are limited only by the imagination of the model builder.
Some Relevant 3D Technologies
3D graphics is both a huge, complex research discipline and big business (consider movie special effects and the computer game industry, to name two particularly lucrative examples), so providing any kind of comprehensive review of the pertinent technologies is impossible in an article of this length and scope. However, there are a smaller number of evolving technologies that are particularly relevant to the delivery of 3D cultural content via the Web, which I've attempted to group and summarize below.
Web3D
Web3D is the name given to a family of standards and related technologies that have been approved by the Web3D Consortium for delivering true interactive 3D content over the Web. The Web3D Consortium is a non-profit membership corporation, founded in 1994 as the VRML Consortium, comprised of technology companies that have a stake in the field of 3D graphics on the Web. The Web3D Consortium also has a close relationship with the World Wide Web Consortium, or W3C.
Table 1: Web 3D Standards and Related Technologies
|
VRML (usually pronounced "vermal") 97 is the latest public release of the Virtual Reality Modeling Language, the original and still the most popular way to deliver 3D information over the Web. It is also ISO/IEC standard 14772-1:1997 (and in fact set a record for the fastest time-to-standard within ISO of 18 months). VRML is a relatively simple scene description language and common interchange format that uses a scene graph programming model. Primitive objects such as cylinders, boxes, spheres and cones are assembled hierarchically into ever-more complex groups in order to build up the geometry of more complex objects, such as office buildings or automobiles. |
|
|
Java 3D is a multimedia extension to the Java 2 platform. It comprises a collection of classes that define a high-level application programming interface, or API, for interactive 3D development within the Java framework. |
|
|
ISO/IEC JTC1/SC29/WG11, an international group better known as the Moving Picture Experts Group, developed MPEG-4, also known as ISO/IEC standard 14496. Like its predecessors MPEG-1 (which includes the popular MP3 audio format) and MPEG-2, MPEG-4 is a standard that defines how digital audio and video media can be encoded, compressed, streamed for efficient delivery over networks, and reassembled correctly for presentation. MPEG-4 also allows media streams to be scaled according to the capabilities of the client terminal, and introduces an object-oriented paradigm, allowing multiple audio/video objects to be delivered and composed into an interactive MPEG-4 scene in either 2 or 3 dimensions. |
|
|
X3D, or Extensible 3D, is a standards development initiative to capture the best capabilities of VRML 97, and allow them to be expressed in XML (it was originally called VRML Next Generation, which gives some clue as to its evolutionary nature). Like VRML, the Web3D Consortium is developing X3D, and it will be backwards compatible with VRML 97. However, unlike the extensive VRML 97 specification that requires users to download large, unwieldy browser plug-ins, the X3D specification is based on a small, lightweight core that can be easily extended with additional components as necessary. The standard is almost complete, and is due for release in 2001. |
QuickTime VR
Apple's QuickTime VR, often known as QTVR, is actually not a 3D image file format at all, but uses an interactive set of compressed still images that have been stitched together by special authoring software to give the illusion of a 3D interaction. In essence it offers sophisticated interactive animation. There are two types of QuickTime VR movie: Panoramic movies, which allow the user to navigate a panoramic view of up to 360º from a single viewpoint; and Object movies, which allow the user to view a fixed object from multiple viewpoints. The jaguar head Inka goblet from the Smithsonian is a good example of a QuickTime VR object movie.
In addition to this radial navigation, QuickTime VR movies can support zooming in and out, and embedded hyperlinks that can take the user either to a new QuickTime VR movie, or to a completely new Web page.
Although QuickTime VR is not a genuine 3D format, the intuitive navigation of photo realistic scenes and objects—coupled with the ubiquity of the QuickTime browser plug-in and the relatively low cost of authoring QTVR movies—make this an effective and appealing approach for presenting 3D cultural information on the Web.
Acquiring 3D Models
Unfortunately, acquiring 3D models is still a relatively costly and complex process, although it is getting cheaper and easier all the time. There are currently two techniques for acquiring 3D models: creating them from scratch using some of the increasingly affordable and user-friendly software products available, including recent products that can help generate 3D models by overlaying 3D geometry onto 2D digital images; and using a 3D scanner, a device that can scan the geometry of an object using laser range-finding technology. Some 3D scanners also have optical sensors, so that they can capture visual information as a digital image that is then wrapped around the 3D model, in a process known as texture mapping.
Forecasts
Most industry pundits agree that the Web 3D revolution is now long overdue. Typical desktop computers are now sufficiently powerful to render reasonably detailed 3D models in real time, network bandwidth is improving all the time, users are increasingly sophisticated and demanding, and there is a growing standards framework that will support collaborative development.
All that is needed now is the killer app—the application of the technology that transforms it from an esoteric gimmick into an indispensable business tool. Perhaps the presentation of cultural information on the Web is that killer app.
Footnotes
(1) Gibson, William, Neuromancer, Ace Science Fiction, 1984. (Back)
(2) Star Trek, Paramount Pictures, 2001. (Back)
(3) Descartes, René, The Metaphysical Meditations, 1641. (Back)
(4) The Matrix, Warner Brothers, 1999. (Back)
(5) Doom and Quake, id Software, Inc, 2000. (Back)
References
Foley, James D., van Dam, Andries et al, Computer Graphics: Principles and Practice, Addison Wesley, 1990.
Walsh, Aaron E. & Bourges-Sévenier, Mikaël, Core Web3D, Prentice Hall, 2001.
![]() A Project on Preservation of Digital Data
A Project on Preservation of Digital Data
Raymond A. Lorie
IBM Almaden Research Center
lorie@almaden.ibm.com
The challenging problem of preserving digital information for the long term is getting more and more attention from the computer science community and from the various communities that are responsible for the preservation of born or re-born digital documents (1). In order for a document to be readable in the future, two conditions must be met. First, the bits that constitute the document must be readable from the medium and transferable to a computer memory. Then, software must be available to interpret the data. Our project on long-term preservation is an initial effort at studying this precise problem. We assume that we know how to preserve the bits (periodically copying from one medium to another seems to be the classical—and probably only—solution), and we focus our attention exclusively on the interpretation of the preserved bit stream.
The preservation of documents has, for centuries, been equated with the preservation of pages written or printed on paper or on an equivalent two-dimensional medium. Actually, what paper preserves is one particular representation. Even if the text is initially captured digitally, the individual character values are lost; only character recognition, always prone to errors, can recreate the information. On the contrary, electronic documents offer the opportunity to do much better, and a viable preservation scheme should take advantage of their capabilities. Consider a PDF document. Although the main goal of PDF is to save the rendering, it would be a pity to lose the individual character values, quite valuable for indexing or for insertion into another application (2).
Two basic techniques have been proposed for preserving information: conversion and emulation.
Conversion
It is the most obvious, business-as-usual, method. When a new system is installed, it coexists with the old one for some time, and all files are copied from one system to the other. If some file formats are not supported by the new system, the files are converted to new formats and applications are changed accordingly. However, for long-term preservation of rarely accessed documents, conversion becomes an unnecessary burden. Another drawback of conversion is that the file is actually changed repeatedly—and the cumulative effect that such successive conversions may have on the document is hard to predict.
Methods Based Exclusively on Emulation
In an important article for Scientific American, Jeff Rothenberg proposed a method to save not just the data but also the program that was used to create/manipulate the information in the first place. He suggested that the only way to decode the bit stream would be to run the old program, which would require the use of an emulator. Several different methods for defining how an emulator can be specified have been suggested, but the feasibility of these methods has not yet been fully demonstrated.(3, 4, 5)
The emulation approach suffers from two other drawbacks.
1. Saving the original program is justifiable for re-enacting the behavior of a program, but it is overkill for data archiving. In order to archive a collection of pictures, it is hardly necessary to save the full system that enabled the original user to create, modify, and enhance pictures when only the final result is of interest for posterity.
2. The original program generally shows the data (and more often, results derived from the data) in one particular output form. The program does not make the data accessible; it is therefore impossible to export the original data from the old system to the new one. It is interesting to note the similarity with what was said above about paper information.
In the context of a project on long-term archiving of digital data, initiated last year in IBM Research, we are considering an approach that relies only partially on emulation (6). Our objective is to find remedies to the two drawbacks to emulation noted above. In order to do that, we differentiate between data archiving, which does not require full emulation, and program archiving, which does.
For data archiving, we propose to save a program P that can extract the data from the bit stream and return it to the caller in an understandable way, so that it may be exported to a new system. The program P is written for a Universal Virtual Computer (UVC). All that is needed in the future for executing P is an interpreter of the UVC instructions. The execution of P in the future will return the data with additional information, according to the metadata (which is also archived).
To archive a program behavior, emulation cannot be avoided. We propose to use the same Universal Virtual Computer to write today a UVC program that will emulate the current computer when interpreted on a future one.
Since the UVC obviously plays a central role in our proposal, let's begin with a brief overview.
A Universal Virtual Computer
The UVC architecture relies on concepts that have existed since the beginning of the computer era: memory, registers, and a set of low-level instructions. The fact that the computer is virtual and that performance is of secondary importance allows for a simpler, more logical, maybe less optimized, design.
The memory of the computer is composed of a certain number of spaces. A space contains an arbitrarily large set of registers and a sequential bit-addressable memory (see Fig. 1). Instructions only address pointer registers by specifying a space and a pointer register number. A pointer register "points" to a register that contains an integer or to a position in the bit-addressable memory. Registers are of unlimited length; an integer value occupies as many bits as necessary at the right of the register. The sign is a separate bit.
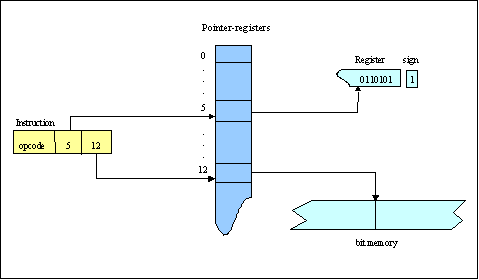
Figure 1: Memory model for the UVC
The instruction set contains register-to-register arithmetic instructions, a memory-to-memory move of any bit string from one address to another, a similar comparison operation, an instruction to load an integer of any number of bits from memory to a register (and its inverse store), and arithmetic operations on addresses. For flow control, a branch instruction is conditional on the value of a return code set by most instructions.
Archiving Data
As illustrated in Fig. 2, an application program written today would generate a data file, which is archived for the future. In order for the file to be understood at a later date, a program P would also be archived, which can decode the data and present it to the client in an understandable form. Program P would be written for a UVC machine.
In the future, a restore application program reads the bit stream and passes it to a UVC interpreter, which executes the UVC program. During that execution the data is decoded and returned to the client according to a logical view (or schema). The schema itself must also be archived and easily readable so that a future client may know what the schema is (not shown in Fig. 1). In our approach, the logical schema is an XML-like structure. When read (actually, decoded by the UVC program), all data items are returned to the user, tagged with a semantic label. The structure of the returned data and the tags are defined in the metadata (also archived).
In order to be able to read and understand the metadata, a similar mechanism defines a "schema to read schemas." Its predefined structure and tags are part of a convention, which must be universally known, now and in the future. It does not need to be stored with each object but needs to be replicated in many places so that it remains accessible to anybody, anywhere, and at any time.
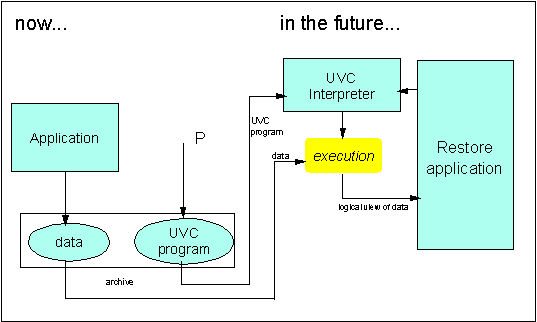
Figure 2: Data archiving - scenario 1
In the scenario described above, the archive contains the data produced or used by today's program. In Fig. 3, an additional transformation reformats the original data into data', under a format that simplifies the implementation of the UVC program to decode it. The first scenario has the advantage of maintaining the original format; the second one capitalizes on tools that exist today for transforming the data, therefore simplifying the writing of the UVC program.
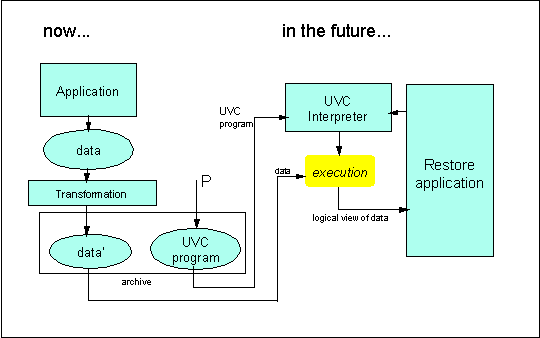
Figure 3: Data archiving - scenario 2
Archiving Programs
When the object to be archived is a program, the current code must be stored and later executed under emulation. Note that some simple program may not require the saving of other packages or operating systems. However, if the object is a full-fledged system with Input/Output interactions, then the operating system must be archived as well.
The UVC approach can be naturally extended to support the archiving of programs, providing for a way to essentially write the emulator today, even if the target machine is not known. Instead of archiving the data bit stream and a program to decode it, we would store the original program, together with an emulator of the old machine, written in the UVC machine language, and any data file required to run the original application program (see Fig. 4). In the future, the UVC Interpreter interprets the UVC instructions that emulate the old instructions; that emulation essentially produces an equivalent of the old machine, which then executes the original application code. The execution yields the same results as the original program. The metadata must simply contain a user's guide explaining how to run the program.
This mechanism suffices if the program does not have any interaction with the external world (Input/Output operations or interrupts). In practice, I/O devices will have to be emulated as well. We have not addressed this problem yet, but it does not seem to be unsolvable.
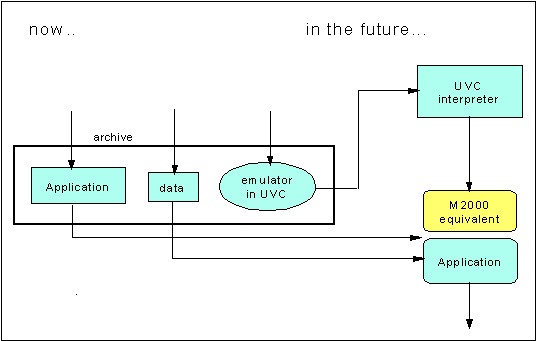
Figure 4: UVC-based Emulation
Summary and Conclusions
In this paper, we have briefly reviewed the challenges of archiving digital information for the very long term and discussed a new approach. We make a distinction between the archiving of data and the archiving of a program behavior. The same technique is used to solve both problems, relying on a Universal Virtual Computer. For archiving data, the UVC provides a means for writing methods that interpret the archived data stream. For archiving a program behavior, the UVC provides a means to specify the functioning of the original computer.
What the proposed method accomplishes is to decrease the dependency of applications on standards. Essentially, for any new format, writing the UVC program to decode it will ensure the preservation of its data. The method also tends to do preparatory work now—when the information is well known—rather than postponing it to the future when the difficulty would be much greater.
Since the approach calls for writing UVC programs, there will always be a need for a good compiler from a popular (at that time) high level programming language to the UVC machine language. It is reasonable to assume that some open software organization will take care of that requirement. Maybe every ten years or so, the source language will change and the compiler will need some work.
Suppose an organization introduces a new format (such as PDF or Word). This, fortunately, does not happen too often. The ideal is for the organization to produce a program able to decode the data structure and to return the data according to a logical structure. That program can be compiled onto UVC and packaged for archiving.
In some cases, it is even possible to get away with not developing a decoding program. Consider the various image formats that exist today, with the multitude of conversion programs. Even if a particular image exists in a JPEG format, it could be converted to, say, TIFF and archived as such—together with the TIFF decoding program. Multiple formats exist because of different inherent characteristics. For long-term archiving these characteristics are secondary. Any data representation is acceptable (if it does not lose information and is memory efficient).
In the future, there must be an interpreter of the UVC for the new machine. Metadata will provide information on what the logical data model is. A logical model is much more general and more stable than an actual physical representation optimized for performance reasons. This means that multiple decoding programs will yield the same logical view of data, thus reducing the effort to write applications in the future that use the archived data.
While most documents are supported by relatively few formats, not all data belong to a document. A large table may be seen as a document in Excel. But many files still exist that contain data with an arbitrary application-dependent format. In this case, it is the responsibility of the developer to provide a decoding program.
It is also important to note that many of these non-document data files end up today in a database system. An archiving solution must ensure that a utility is always available to extract a table or a set of tables (speaking in relational terms), to store the data in a bit stream, and provide a UVC program to extract logical data elements from the stream. For example, with this kind of scenario, a single DB2 utility, with a single UVC program, would support all DB2 data. The issues of extracting XML structures from relational databases are being studied by the database community (7).
A note on the verification of the correctness of programs that will be used in the future: if a UVC program is written today, it can be tested on a UVC interpreter written today for the current machine. If ten years from now, a new machine architecture is introduced, a new UVC interpreter will have to be written. The executions of the UVC program under the old and new interpreters must yield the same results.
We realize that solving the archiving problem is not simply a technical challenge. For example, the success of any effort would hinge on a minimal agreement of all parties involved in generating new technologies or creating new types of data. But that cannot happen before some solutions are developed and evaluated. Our project's purpose is to evaluate the feasibility of a UVC solution. Our first priority is data archiving, specifically for documents that are still published on paper but archived in digital form. Our real world connection is through a joint project with the Koninklijke Bibliotheek, the national library of the Netherlands, in The Hague. It involves a proof of concept for some specific data formats.
Footnotes
(1) D. Waters and John Garret: Preserving Digital Information. Report of the Task Force on Archiving of Digital Information. Commissioned by the Commission on Preservation and Access and the Research Libraries Group, Inc., May 1996. (Back)
(2) J. M. Ockerbloom: Archiving and Preserving PDF Files, RLG DigiNews, February 2001. (Back)
(3) J. Rothenberg: Ensuring the Longevity of Digital Documents. Scientific American, 272(1), January 1995. (Back)
(4) J. Rothenberg: Avoiding Technological Quicksand: Finding a Viable Technical Foundation for Digital Preservation. A report to the Council on Library and Information Resources, January 1999. (Back)
(5) S. Granger: Emulation as a Digital Preservation Study, D-Lib Magazine, October 2000. (Back)
(6) R. Lorie: Long-term Archiving of Digital Information, IBM Research Report, No RJ 10185, March 2000, revised July 2000. A newer version is to be published in the Proceedings of the First Joint Conference on Digital Libraries, Roanoke, VA, June 2001. (Back)
(7) J. Shanmugasundaram et al.: Efficiently Publishing Relational Data as XML-documents, VLDB 2000. (Back)
|
Highlighted Web Site ShortCourses
|
FAQ
Microfilm Scanning
Q. "My institution is considering a microfilm scanning project, and I need to decide whether we should buy a film scanner, or outsource the work to a service bureau. Can you give me any help in locating information?"
If you have not purchased a microfilm scanner before, you should plan on doing extensive research before making a decision. Unfortunately, there is no uniformly reliable source of information on scanners. As much as possible, you should consult professionals from other libraries and archives who have undertaken projects similar to yours. Try sending an inquiry to one of the listservs dedicated to imaging technologies and digital collection development. You should consult these not so much to learn about particular scanners (as always, opinions expressed on Internet bulletin boards should be taken lightly), but particularly to gain insights from other projects that may help you decide which questions to ask vendors. The IMAGELIB listserv focuses on imaging projects by libraries, and it has a searchable archive available online. A search of the archives indicated some interest in microfilm scanning in recent years. You may also want to consult the DIGLIB listserv, which covers a wide range of issues facing digital libraries.
Before making a purchasing decision, you should prepare a detailed assessment of your equipment needs for the particular work you wish to undertake. Given the relatively high cost of these machines, it is important to understand the many trade-offs in image quality, speed and usability you may encounter. In many cases, you will find that manufacturers themselves may be the most comprehensive source of information about their products. This is especially true regarding high—and medium—volume production scanners, which are made by a handful of companies, including SunRise Imaging, Mekel Technology, and the UK firm Wicks and Wilson. Each of these firms offers considerable product information on their Web sites, which may be enough to help you get started in your search for a scanner. Third-party resellers may also provide some useful information, albeit with the same caveats that apply to manufacturers. One reseller, Amitech, is listed as the sole U.S. dealer for Wicks and Wilson microfilm scanners. Some information about high-volume machines may also be gleaned from trade publications, such as Advanced Imaging magazine. However, the market for these machines is too small to attract more than passing attention from publications dedicated to the lower-end professional and consumer markets.
In our attempt to compare microfilm scanners, we did find some useful information on the manufacturers' Web sites, which is summarized in the tables below. We supplemented this information through email and telephone calls to the manufacturers and one third-party reseller. The tables compare the three leading high-volume microfilm scanners mentioned above, with two medium-volume scanners. Pricing information is approximate, and is based on the manufacturer's list price rather than the actual sale price of a particular machine.
High- and Medium-Volume Microfilm Scanners
| Scanner |
CCD
elements
|
Speed
(at 200 dpi)
|
Bit
Depth
|
Maximum
Resolution
|
Pricing
|
| SunRise 2000 |
8,800
|
170/min
|
Bitonal,
Grayscale
|
600
dpi
|
$85,000-95,000
|
| Wicks and Wilson 4100 |
7,500
|
105/min
|
Bitonal,
Grayscale
|
400
dpi
|
$63,000
|
| Mekel 525 |
8,192
|
100/min
|
Bitonal,
Grayscale
|
500
dpi
|
$53,000
|
| Wicks and Wilson 4001 |
7,500
|
42/min
|
Bitonal
|
400
dpi
|
$37,500
|
| Wicks and Wilson 4002 |
10,000
|
25/min
|
Bitonal
|
600
dpi
|
$42,500
|
| Scanner |
Output
File Formats/Compression
|
Film
Types
|
| SunRise 2000 |
bitonal:
TIFF (Group 4)
grayscale: TIFF uncompressed, JPEG, GIF |
16/35mm
reels, cartridges, aperture cards, microfiche
|
| Wicks and Wilson 4100 |
bitonal:
TIFF (Group 3, Group 4), CALS
grayscale: JPEG |
16/35mm
reels, cartridges
|
| Mekel 525 |
bitonal:
TIFF (Group 3, Group 4), BMP
grayscale: TIFF uncompressed, BMP, JPEG |
16/35mm
reels, cartridges
|
| Wicks and Wilson 4001 |
TIFF
(Group 4), CALS
|
16/35mm
reels, cartridges
|
| Wicks and Wilson 4002 |
TIFF
(Group 4), CALS
|
16/35mm
reels, cartridges
|
Given the cost of a microfilm scanner and the central role it will play in your imaging project, you should be prepared to ask many questions and to work closely with manufacturers' representatives and/or third-party resellers. By thoroughly investigating your own technical requirements in advance, and by consulting with other libraries that have already been through the process, you should be well prepared to make the right decision for your project and institution.
Hiring a Service Bureau
The alternative to buying a scanner yourself is to hire a service bureau to do the work. In 1997, RLG DigiNews conducted a survey of 15 service bureaus providing these services, 11 of which responded. The results were published in the August 1997 issue, under the title "Technical Review: Outsourcing Film Scanning and Computer Output Microfilm (COM) Recording." For this issue, we sought to update the information from the 1997 survey. We were unable to contact two companies, Zuma Corporation International, and CEScan, Inc. When we attempted to call the latter, an assistant informed us that CEScan had "exited the microfilm scanning business." Nevertheless, we were able to get updated information from all of the other firms that responded to the 1997 survey, as indicated in the table below.
| Microfilm Scanning | |
| Service Provider |
Technical
Specifications
|
|
Electronic Imaging
Systems |
Hardware: Mekel Output:
|
|
Lason Systems, Inc. Contact: Mike Polo or Erin McCarthy |
Hardware: Mekel, Sunrise,
Wicks & Wilson Output:
|
| microMEDIA
Imaging Systems 1979 Marcus Avenue Lake Success, NY 11042 (516) 355-0300 ext. 132 Contact: info@imagingservices.com http://www.imagingservices.com/ |
Hardware: Sunrise
& Photomatrix Output:
|
| Northern
Micrographics 2004 Kramer Street La Crosse, WI 54603 (608) 781-0850 Contact: Tom Ringdahl http://www.normicro.com/ |
Hardware: Mekel, Photomatrix,
Wicks & Wilson, Nikon Output:
|
|
Preservation Resources |
Hardware: Imaging Output:
Xerox DocuImage 620S duplex sheetfed scanner. Direct scanning up to 11"x17" Output:
UMAX Image II color/transparency
scanner Output:
DPI:
Hardware: Reproduction Subsystem Hewlett-Packard 5000
D640
|
| Zuma Corporation 6167 Bristol Pkwy #104 Culver City, CA 90230 (310) 670-1498 Contact: Wayne Brent, President http://www.zumacorp.com/ |
Hardware: Mekel, Wicks
& Wilson and Photomatrix film scanners Output:
|
| Computer Output Microfilm (COM) | |
| Service Provider |
Technical
Specifications
|
|
Anacomp Contact: Ryan
Brausa |
Hardware: Anacomp
XFP 2000
Maximum Output Level
on Film: 300 dpi output at 48x |
|
Image Graphics |
Hardware: MicroPublisher
6000 (Image
Graphics)
Image Files Supported:
Film Formats: 16mm,
35mm, 105mm fiche, 70mm film and 5 inch film |
|
Lason Systems, Inc. Contact: Mike Polo or Erin McCarthy |
Hardware: Anacomp,
MTC, Bell & Howell
Maximum Output Level
on Film: 240 dpi at a reduction ratio of 42x
Film Format: 105mm
fiche |
| Output
Technology Solutions 2534 Madison Kansas City, MO 64108 (816) 843-7082 Contact: Cathy Burgess |
Hardware: GID (formerly
MTC) |
—PKB
Calendar of Events
The First ACM/IEEE-CS Joint
Conference on Digital Libraries (JCDL 2001)
June 24-28, 2001, Roanoke, VA
The Association sponsors this conference for Computing Machinery and the
Institute for Electrical and Electronics Engineers. The goals are to advance
the state of the art in digital libraries, help to identify best practices,
and facilitate sharing and enhance collaboration between researchers and practitioners.
Seminar on Cultural Heritage Collaboration in The Digital Age
June 28-29, 2001, Denver, CO
The Colorado Digitization Project and the Western Council of State Librarians
are sponsoring this leadership seminar for library and museum leaders on building
cultural heritage cooperative projects in the digital age. The topics will range
from why museums and libraries should collaborate on digitization initiatives
to digital archiving, to specific issues encountered in implementation including
standards, training and incentives for participation. For additional information
contact Liz Bishoff.
DELOS Workshop on Interoperability in Digital Libraries
Call For Papers: Due June 29, 2001
To be held: September 8-9, 2001, Darmstadt, Germany
This international workshop is sponsored by the EU Delos project, a "Network
of Excellence" in Digital Libraries. The workshop is intended to bring together
researchers and developers working on digital libraries and related areas for
in-depth analysis and discussion of new models, theories, frameworks, and solutions
to interoperability in digital libraries. For further information contact: Program
Co-Chairs: hemmje@darmstadt.gmd.de
or umeshwar_dayal@hp.com.
U.K. Seminar on Content-Based
Image Retrieval
July 6, 2001, Newcastle upon Tyne, England
July 20, 2001 University of Manchester, England
The Manchester Visualization Centre and the Institute for Image Data Research
are hosting two free seminars/workshops sessions during the summer of 2001 on
content-based image retrieval. The seminars will bring together leading representatives
from the field to discuss how the technology can be used to extend digital image
collections as an information resource.
Summer Seminars at
Oxford's Humanities Computing Unit
July 23-27, 2001, University of Oxford, England
The seminars cover a range of topics on humanities computing. They include:
creating and using digital texts, video, sound and still images, managing digital
projects, documenting and cataloguing digital resources, working with XML and
the TEI, and putting databases on the Web.
Managing Digital Video
Content Workshop
August 15-16, 2001, Atlanta, GA
Sponsored by the Coalition for Networked Information, Internet2, Southeastern
Universities Research Association, and ViDe (Video Development Initiative),
the workshop will focus on practical applications of current and emerging standards.
These include Dublin Core, ODRL, XrML, and MPEG7, for describing and managing
video assets for any digital video collection, as well as for sharing collection
information in the global environment using the Open Archives Initiative (OAI)
protocol.
Preserving Photographs
in a Digital World: Balancing Traditional Preservation With Digital Access
August 18-23, 2001, Rochester, NY
Sponsored by George Eastman House, the Image Permanence Institute, and
the Rochester Institute of Technology this annual seminar focuses on the preservation
of photographic materials and on digitizing photographic collections.
SEPIA (Safeguarding European
Photographic Images for Access) Workshop on Management of Photographic Collections
September 3-7, 2001, Amsterdam, Netherlands
Sponsored by the European Commission on Preservation and Access (ECPA),
this workshop will focus on the role of digital technology and how it will combine
with established preservation methods in an integrated strategy, to ensure optimal
access today as well as in the future.
Announcements
Folk
Heritage Collections in Crisis
In December 2000, a group of folklorists, sound engineers, preservation experts,
lawyers, librarians, and archivists met to discuss what would be needed to ensure
the long-term accessibility of folk heritage collections. The American Folklore
Society and the American Folklife Center at the Library of Congress convened
the meeting, with support from CLIR, the National Endowment for the Arts, and
the National Endowment for the Humanities. Available on the Web, this report
includes the text of the three keynote presentations.
Higher Education Digitisation
Service (HEDS) Awarded Grant From the Andrew W. Mellon Foundation
This study will study how pricing structures are determined for delivering digital
versions of rare or unique items in libraries, museums, archives and similar
public institutions; investigate how these digital pricing structures compare
to those used for the delivery of the same or similar resources in analogue
form; explore the thresholds that determine the point at which an organization
charges for the sale of content and other rights to their digital holdings and
the reasons given for such charges.
The Virginia Historical
Inventory
Now available as part of the Library of Virginia's Digital Library Program (DLP)
is the Virginia Historical Inventory Project. The Virginia Historical Inventory
(VHI) is a collection of detailed reports, photographs, and maps, documenting
the architectural, cultural, and family histories of thousands of 18th and 19th-century
buildings in communities across Virginia.
Managing
Web Resources for Persistent Access
The National Library of Australia has just produced a set of guidelines designed
to assist those responsible for the management of online materials to ensure
that links made to those resources continue to work. The guidelines provide
advice on determining the categories of resources that require persistent access
and systems for managing persistence such as redirects, resolver databases or
persistent identifier services. The guidelines also provide information on how
to organize a Web site to reduce the need to move material around, and to keep
older material accessible.
University
of Michigan Offers Free Access to Digital Library Software
The University of Michigan library is providing free access to a suite of software
designed to facilitate communication between the Web and digital library tools
such as search engines. To facilitate the further development and to assist
the information community in building and deploying electronic resources, the
UM library will provide free Open Source access to these tools, inviting users
to modify and adapt the classes and to share the innovations with the broader
community.
DLI2 (Digital Libraries
Initiative) Listserv Initiated
In an effort to further assist communication within this international community,
the Digital Libraries Initiative is providing a single, permanent site for relevant
discussion lists.
Harvard University Library and Key Publishers Join Forces for Electronic
Journal Archive
Sponsored by the Andrew W. Mellon Foundation, the Harvard University Library
and three major publishers of scholarly journals, Blackwell Publishing, John
Wiley & Sons, Inc., and the University of Chicago Press, have agreed to work
together on a plan to develop an experimental archive for electronic journals.
The focus will be the preservation and the archiving of electronic journals.
For further information contact: Dale
Flecker.
IDF Funds Study of Multimedia Intellectual Property Rights
The International DOI Foundation (IDF) is funding a feasibility study for the
development of a Rights Data Dictionary (RDD), a common dictionary or vocabulary
for intellectual property rights. The aim of the development will be to propose
standard rights terms to enable the exchange of key information between content
industries for e-commerce trading of intellectual property rights. For more
information contact: Norman Paskin, Director
of the IDF.
![]()
Publishing Information
RLG DigiNews (ISSN 1093-5371) is a newsletter conceived by the members of the Research Libraries Group's PRESERV community. Funded in part by the Council on Library and Information Resources (CLIR) from 1998-2000, it is available internationally via the RLG PRESERV Web site (http://www.rlg.org/preserv/). It will be published six times in 2001. Materials contained in RLG DigiNews are subject to copyright and other proprietary rights. Permission is hereby given for the material in RLG DigiNews to be used for research purposes or private study. RLG asks that you observe the following conditions: Please cite the individual author and RLG DigiNews (please cite URL of the article) when using the material; please contact Jennifer Hartzell, RLG Corporate Communications, when citing RLG DigiNews.
Any use other than for research or private study of these materials requires prior written authorization from RLG, Inc. and/or the author of the article.
RLG DigiNews is produced for the Research Libraries Group, Inc. (RLG) by the staff of the Department of Preservation and Conservation, Cornell University Library. Editor, Anne R. Kenney; Production Editor, Barbara Berger Eden; Associate Editor, Robin Dale (RLG); Technical Researchers, Richard Entlich and Peter Botticelli; Technical Assistant, Carla DeMello.
All links in this issue were confirmed accurate as of June 12, 2001.
Please send your comments and questions to preservation@cornell.edu.
![]()
Want
a faster connection?
Trademarks, Copyright, & Permissions
