- Feature Articles
Digital Reproduction Quality: Benchmark Recommendations, by Daniel Greenstein and Gerald George
- Metadata for Archival Collections: The University of Toronto's 'Barren Lands' Project, by Marlene van Ballegooie
- Highlighted Web Site—The XML Cover Pages
- FAQ—Monitor Resolution: Debunking Misconceptions
- Calendar of Events
- Announcements
![]() Digital Reproduction Quality: Benchmark Recommendations
Digital Reproduction Quality: Benchmark Recommendations
Daniel Greenstein and Gerald George
Digital Library Federation (DLF)
dgreenstein@clir.org
jgeorge@clir.org
In the early days of digitization, as leaders at Cornell, the University of Michigan, the Library of Congress and elsewhere started building online collections, they began to realize how much their individual collections could be enhanced if they were made interoperable with others. Online patrons could then access books and serial publications digitized and managed at many different sites.
Until recently, discussions of interoperability tended to focus on the use of cataloguing (metadata) standards, such as MARC, Dublin Core, and EAD, and on search-and-retrieval protocols, such as Z39.50 and the Open Archives Initiative (OAI).
But to make collections interoperable, it would also be desirable to have consistent formatting in accordance with some minimum set of standards or benchmarks for digitizing items with fidelity. This aspect of the discussion grew in a meeting, sponsored by the Digital Library Federation (DLF) in April 2001, to consider development of a service that would register digitized books and journals maintained in disparate collections. Participants asked whether the service would register only collections that were digitized in accordance with some standard of quality.
No, was the group's answer, because new, exclusive standards could reduce the registry's usefulness by keeping out of it some large and valuable legacy collections. Besides, users could make their own judgments about whether any particular digitized items would meet their needs. Nonetheless, DLF followed the April meeting with one in May 2001 that produced a recommendation for "a minimum benchmark for a faithful digital reproduction of a printed book or serial publication." For more on the benchmark and background, see Registry of Digital Reproductions of Paper-based Books and Serials.
Benchmark Specifications
The group defined "the minimum benchmark" as "a preservation digital master"—"a digital facsimile that is a faithful rendering of a printed text (including texts with illustrations and rare and early printed texts)." A preservation digital master, the group continued, "must include digital page images," which will meet or exceed the following "minimum level characteristics."
| Printed
texts
(may include simple line drawings or descreened halftones) |
Illustrated
texts
(black and white) |
Illustrated
texts
(color) |
Rare and
early printed texts
|
| 600 dpi,
1-bit TIFF image using ITU-T.6 compression (may be dithered up from a 400 optical dpi 1-bit image) |
400 dpi, 8-bit, TIFF (uncompressed or using lossless compression) | 400 dpi, 24-bit, TIFF (uncompressed or using lossless compression) for color illustrations | 400 dpi, 8- or 24-bit TIFF (uncompressed or using lossless compression) |
The group further recommended that preservation digital masters have descriptive, structural, and administrative metadata, available in well-documented formats such as XML; and that structural metadata include page-level information (e.g., as required for page turning and related application software). The group recommended a "minimum list of structural metadata elements" in an appendix to its report. Additionally, the group specified that preservation digital masters may also include machine-readable text as follows: either uncorrected OCR or corrected OCR that is below 99.995% accuracy, or corrected text (keyboarded or OCR) that is at or above 99.995% accuracy, as well as text that is encoded (at any level, e.g. as specified in TEI Text Encoding in Libraries, Guidelines for Best Encoding Practices, Version 1.0, July 30, 1999). The benchmark is available for review at Draft benchmark for digital reproductions of printed books and serial publications.
Rationale Behind Recommended Benchmarks
Book illustrations are treated as parts of books rather than as unique objects. They require different benchmarks than printed texts, and particularly greater bit depth. The relief, intaglio, and planographic processes used to create book illustrations offer fine granular detail that may not be captured with bitonal scanning, which also cannot capture color.
Rare and early printed materials require different benchmarks than circulating printed texts because digital preservation masters used for forensic purposes may require a richer file. Their printing is often very fine with a great deal of variation. And rare books often contain marginalia or annotations that are best captured tonally. Given the nature of rare and early printed materials and the use to which their preservation digital masters may be put, a case can be made for setting a benchmark minimum resolution at 600 dpi, but 600 dpi may be expensive with little to no appreciable gain in information capture. Therefore institutions may prefer to digitize at lower resolutions.
Why It Matters
The group does not intend to promote or define methods for creating digital replacement copies for source documents. It is presumed that many of them will be retained even as their digital surrogates are used to enhance access. Nor does the group intend to make an absolute statement of best practice. Such a statement would assume that digitization methods will not improve, but they will, and best practice with them. That is why the group defined preservation digital masters as digital objects with minimum characteristics. The group also has no intention of disparaging the importance of legacy digital collections, forcing their rescanning, or encouraging poor management of them. The recommendations look forward, suggesting that from now on preservation digital masters be made to meet or exceed the recommended minimum characteristics.
What Good Will This Do?
By agreeing to a benchmark for a preservation digital master, libraries and other organizations can reduce risks in producing and maintaining digitized texts, and inspire users' confidence in them. Because preservation digital masters will be considered viable for meeting future needs, repositories investing in them will be secure in the knowledge that re-digitizing will not be necessary even as production techniques improve. Because digital masters will have well-known and consistent properties, they will support a wide variety of uses (including uses not possible with printed texts). As more printed texts become digitized, collection managers may investigate alternatives to preserving redundantly multiple copies of them, such as considering a network of specialist print repositories.
Building consensus about desirable characteristics for preservation digital masters can also help libraries and related organizations to:
Implementation, Research, and Next Steps
Several factors will need consideration in determining which benchmark levels to apply and whether to digitize at or above the benchmark level. The factors include the extent and nature of illustrations in the source material, the intended use of the digital preservation master, and the scale and cost of the digitization effort. For example, if an institution is digitizing 10,000 printed books and only a small fraction of the pages have grayscale images, it may opt to do the lot as printed text (600 dpi bitonal images). Libraries will decide individually how to characterize early and rare printed materials.
The group identified the following needs for additional research:
After participants in the group have reviewed the draft report, it will be posted to the DLF Web site, and DLF members will consider whether to endorse the benchmarks. A more public review of the recommendations will be sought as well, through the Association of Research Libraries (ARL), the DLF Forum, relevant ALA discussion groups, various digital preservation lists, and in September, 2001 at the National Endowment for the Humanities brittle books meeting.
![]() Emulation, Preservation, and Abstraction
Emulation, Preservation, and Abstraction
David Holdsworth
Paul Wheatley
University of Leeds
D.Holdsworth@leeds.ac.uk
P.R.wheatley@leeds.ac.uk
Introduction
Emulation is a digital preservation strategy that holds great promise for the future. By emulation, we mean the re-creation on current hardware of the technical environment required to view and use digital objects from earlier times. As the digital preservation community increasingly takes emulation seriously there is still considerable debate about how to deploy the technique. Until recently, the lack of any real practical work has left these arguments on a purely theoretical (or more correctly hypothetical) level, and the CAMiLEON Project (1999-2002) is attempting to redress the balance. This is the project's first low level look at the use of emulation as a real and practical preservation strategy, which we will be developing and testing over the remaining period of the project.
Within the CAMiLEON project we are working with material from the 1970s and 1980s as a way of showing how we can map from one architecture (namely an old one) to one that is radically different. The goal is to deliver a result in which a preserved digital object of some complexity can be run in emulation with sufficient verisimilitude to reproduce the significant properties of the original experience.
An earlier longer version of this paper gives more justification for the views expressed here, especially from a computer science perspective.
Emulation in a Nutshell
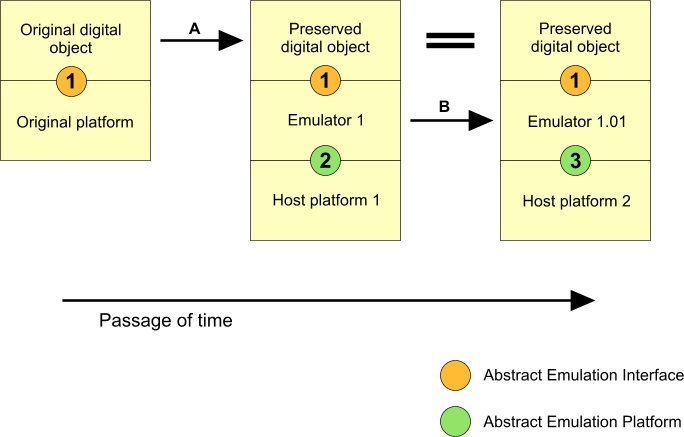
Figure 1.
The above diagram purports to show first the transformation (arrow A) of an original digital object into a preserved digital object, which can then be run under emulation to give adequate access to the significant properties of the original. This step ensures continued access as the original platform becomes obsolete. Further passage of time leads to the transformation shown by arrow B, in which the obsolescence of platform 1 is handled by the updating of the emulator to run on a different platform. The large equals sign indicates that the preserved digital object consists of the same byte-stream forever.
The crux of our argument is that the transformations indicated by the two arrows can be implemented economically. Key to this is the design of the abstract interfaces indicated by the numbered circles on the junctions between digital components. Our own experience in preserving material from decades ago offers strong evidence that this approach will work.
The interface labeled 1 is the API (Application Program Interface) necessary for the successful operation of the original digital object. Emulator 1 recreates this interface in the abstract world of emulation. This interface remains the same forever. The emulator itself is a digital object and relies on interface 2 for its successful operation. A key strategic goal is "future-proofing" by choice of interface 2 involving only features that are likely to survive the test of time with little modification. Thus interface 3 will be very similar to interface 2, and the emulator for host 2 (emulator 1.01) will be readily derived from emulator 1.
There may well be many digital objects that operate via interface 1. Where that is the case, the effort in emulator 1 and its subsequent modification to run on later platforms will be repaid many times.
Emulation Elsewhere
Jeff Rothenberg (a long-time advocate of the emulation strategy) has conducted an experiment in emulation as a preservation strategy for the Dutch Royal Library. In a report on this project he proposes the development of an Emulation Virtual Machine.
The June, 2001 issue of RLG DigiNews contained an article by Raymond Lorie of the IBM Almaden Research Center who reports on a project (see Lorie 2001) to design a Universal Virtual Machine (UVM), which can then be used for actual emulator implementation.
We are aware of two products in the marketplace that emulate the world of Wintel on non-Intel platformsSoftWindows (review) and Virtual PC (review). The existence of these products underlines the feasibility of emulation, even for modern systems, not merely for yesterday's historical curiosities. These are commercial products, and at present we cannot comment on their likely portability to platforms of the future. For open source emulation of Wintel we can look to Wine. Although it requires an Intel platform Wine works on most popular Intel Unixes and is not restricted to Linux.
There is ample evidence on the World Wide Web of unorganised amateur enthusiasts reviving interest in classic arcade games via emulation. Surely it is not beyond an organised and funded preservation world to make rewarding and practical use of emulation using this approach.
Emulation in CAMiLEON
The CEDARS project work on representation information (PDF—in USA or HTML—in UK) reveals the importance of identifying the significant properties of a digital object, and of selecting an appropriate abstract representation that preserves these significant properties. Preservation then proceeds by mapping that abstract representation (e.g., a file tree) into a byte-stream, which is then preserved indefinitely—along with preserving the ability to reverse the mapping.
A similar selection of an appropriate abstraction is vital to successful emulation. We would argue strongly that this abstraction is unlikely to be at the level of actual hardware. This may be quite easy at the CPU level, but presents all sorts of difficulties with regard to peripherals. The abstraction discussed here is the specification of interface 1 in figure 1.
This abstract emulation interface needs to be identified within the original system. For a modern day Windows application running on a PC platform, we would have to choose between candidates such as the underlying hardware, the PC BIOS, and the Windows API. For such a platform, the third option would probably be the most appropriate. The Wine project gives some hope that this would be the case.
We do not yet have hard and fast rules for selection of the abstract emulation interface, although we can identify a number of factors that should influence the choice.
Longevity
There is also the issue of selection of an appropriate platform upon which to run the emulator. The selection of this initial abstract emulation platform (interface 2 in figure 1), with a view to its trouble-free evolution into interface 3, is the key determiner of the ultimate longevity of the emulator.
Our preference is for a software platform, such as the C programming language and the socket library, which supports the communication requirements of the application. The Wine project is already emerging as an emulation of the Wintel platform running on the UNIX API (which includes the C programming language and the socket library).
See the longer, earlier version of this paper for details of our use of this platform in preserving software from the 1970s. A companion paper Emulation: C-ing Ahead proposes using a subset of C as the programming language.
We wish to challenge the view taken by Rothenberg and Lorie that a high-level language is too transient, and will not stand the test of time. History teaches us that some languages do achieve such pre-eminence (and have so much software investment dependent upon them) that they outlast virtual architectures. C was standardised in 1973. Modern FORTRAN compilers will still process most of FORTRAN66 (1966). Pre-eminent virtual architectures are harder to find. Pascal P-code, which is cited as influential in the design of the Java virtual machine, has nothing like the exposure of C or FORTRAN.
Timeliness
Our emulation work with 1970s and 1980s material has sometimes encountered difficulties because of material having been lost with the passage of time. We believe that we have succeeded with the 1970s material just in time. When we started work, there was one remaining live installation of the system, and interaction with the people running that system was invaluable.
We would advise getting emulation working at least to the proof-of-concept stage while real instances of the system to be emulated still exist in working order, and the people who know how it works are still compos mentis. This places extra stress on the need for longevity of the emulator implementation.
Conclusion
We believe that our approach to preservation by emulation, as summarised in Fig 1, offers a practical route to preserving complex digital objects, with respect to technical feasibility and affordability. Our longer paper gives more substance to this claim, including a description of the rebirth of ICL's George3 system by emulation. We contend that choosing to define our abstract emulation platform in terms of a programming language offers the best assurance that the emulator can evolve over time.
This process of evolution of the emulator is actually a form of migration, as described in a discussion paper on migration by Paul Wheatley. This is not to say that migration is actually always better than emulation, but that some systems lend themselves to migration and some do not. In fact, migration is most effective when the original object was produced with portability in mind. This is particularly the case with our approach to writing emulators.
Emulation should not be over-sold as the answer to all digital preservation issues. It is just part of the armoury necessary for defending our digital heritage against the ravages of time in a world where innovation (and hence change) is highly prized. Vital to any preservation is the identification of the significant properties that form the preservation goal, and thus to the identification of appropriate abstractions that are necessary for the digital object to manifest these significant properties. In some cases these appropriate abstractions constitute the functionality of an actual computer system, and the best way to preserve these abstractions long term is to emulate them. In so doing we preserve meaningful access to the original digital object(s).
Metadata for Archival Collections: The University of Toronto's 'Barren Lands' Project
Marlene van Ballegooie
Digital Archive Coordinator,
University of Toronto Library
m.vanballegooie@utoronto.ca
Introduction
Since the Web explosion of the 1990s, a wide variety of digital collections have emerged on the Internet. While digital collections may differ in content or structure, they all share one commonality—the need for metadata. Frequently described as "data about data," metadata is a critical component of all digital collections. Metadata facilitates the discovery and retrieval of information, it provides for resource presentation and navigation, and it contains the information needed to preserve digital data files. While several digital collections of books have been created for the Internet, it is only recently that libraries and archives have begun to digitize archival collections for Web delivery. The purpose of this paper is to describe the descriptive, structural, and administrative metadata requirements for the University of Toronto's most recent digital project, entitled: The Barren Lands: J.B. Tyrrell's Expeditions for the Geological Survey of Canada, 1892-1894. It will also describe the ways in which the metadata created for the Barren Lands project facilitates the discovery and retrieval of information within the digital collection.
Project Background
The Barren Lands project is a full-text online collection of archival material related to two exploratory surveys conducted by the Canadian explorer, geologist, and mining engineer, Joseph Burr Tyrrell (1858-1957). The collection is centred on Tyrrell's 1893 and 1894 explorations of Canada's Barren Lands region west of Hudson Bay, in the area now known as Nunavut. Drawing on materials from the J.B. Tyrrell collection and related collections at the Thomas Fisher Rare Book Library, University of Toronto, the digital collection includes over 5,000 images from original field notebooks, correspondence, photographs, maps, newspaper articles, and published reports.
Representing Archival Collections Online
The first major challenge associated with the Barren Lands project centred on how to represent archival material within an online environment. A search of the Internet for similar archival projects revealed that online archival collections were most often presented in one of two ways: as an online exhibition or as a simple database of independent archival documents. Following the "exhibition" method, institutions presented archival collections online in much the same way as they would present an exhibition of physical materials; narrative descriptions or transcriptions of items were presented with links to digital representations of those items. These Web sites tended to be small in size and highlighted materials that were considered important. The second approach followed by many institutions was to create a database-driven Web site with basic search and browse techniques. In these digital repositories, each archival document was treated as a separate entity and basic descriptive metadata elements such as title, author, and date were given for each item.
Although the Barren Lands project team found aspects of both methods of delivery appealing, they decided that neither approach was fully compatible with their vision of the project. While the "exhibition" approach provided an abundance of narrative contextual information, this method was deemed impracticable for the size of the digital collection. Similarly, a strict database approach was also not favoured, as it did not retain the contextual linkages between the documents. Instead, the Barren Lands project team decided to create two levels of descriptive metadata to provide the necessary contextual information for the archival materials and to allow for comprehensive searching.
Descriptive Metadata—A Two-Tiered Approach
In most digital collections, each book, article, map, etc. is considered to be an independent digital object. The Barren Lands project was different in that the archival collection consisted of many documents that were inter-related with each other. For example, in the case of J.B. Tyrrell's correspondence, the meaning and significance of an individual letter can only be understood if it is read within the context of a series of letters. It was essential that these natural connections be retained within the digital environment. At the same time, it was necessary that each document remain an independent digital object for the purpose of resource discovery and retrieval. The solution to this problem was to adopt a two-tiered approach to the creation of descriptive metadata—one tier to describe the archival materials as a collective unit and another to describe each digital object.
Tier 1—Describing Archival Collections
Although paper-based finding aids and item listings for some of the materials did exist for the J.B. Tyrrell and James W. Tyrrell collections, the project team was unable to use this information in the construction of the online collection. Problems with the pre-existing descriptive metadata were three-fold: first, the metadata was not in electronic format; second, the metadata did not contain all of the necessary descriptive information; and third, the archival materials were not described consistently according to archival descriptive standards. Because of these problems, the project team decided to re-describe both collections according to the Canadian descriptive standard, the Rules for Archival Description (RAD). (1)
Once the descriptive metadata was complete, it was necessary to encode this information in a standard data structure. In order to retain the relationships between archival materials, the project team adopted the Encoded Archival Description (EAD) data structure standard, which is jointly administered by the Society of American Archivists and the Library of Congress. EAD is a non-proprietary standard in the form of a Standard Generalized Markup Language (SGML) and Extensible Markup Language (XML) Document Type Definition (DTD). Developed specifically for archival finding aids, the EAD standard has the ability to accurately represent the multilevel nature of archives in a machine-readable format. Consequently, the EAD standard facilitates access by allowing users to "drill down" into an archival finding aid, beginning at the fonds (2) or collection level description down to the descriptions of individual items.
In the Barren Lands project, the descriptions of the J.B. Tyrrell and James W. Tyrrell fonds were encoded using the XML version of the EAD DTD. In these multi-level records, users are provided with descriptions of the entire fonds, the various series of documents that make up the fonds, and file level descriptions (e.g. descriptions of photo albums and letterbooks) if they exist. Within the description of each series or file containing digitized objects, a link is made from the title of the object to a separate item level description. While EAD does provide the capability to describe archival materials down to the item level of description, the project team decided that within the context of our project, the standard was unsuitable for that purpose. Item level descriptions could not be included in the EAD description for three reasons. First, the EAD standard did not provide for the inclusion of all the required descriptive metadata elements for item level records. Second, EAD did not have the capability to embed the OCR or rekeyed text within the item level description. And third, the standard did not allow for the incorporation of the structural metadata needed for the project. Because the EAD standard could not adequately handle these specific needs, the project team opted to create a second tier of metadata for each individual digitized item.
Since no existing data structure standard contained all of the features needed for our item level descriptions, the decision was made to create a customized XML DTD based on the Text Encoding Initiative (TEI). (3) Not all features of the TEI DTD were needed for the project; in fact, only the elements contained within the TEI Header and the paragraph <p> and page break <pb> elements were included in the DTD. Furthermore, as the structure and features of the online collection became more defined, it was clear that many of the descriptive metadata elements in the DTD would need to be customized for the Barren Lands project.
The customized DTD contains many of the standard fields found in descriptive metadata schema such as title, author, extent, subject, and others that facilitate in the discovery and retrieval of information. Features that make the metadata schema unique are attributes to determine whether records are published or not, as well as attributes to identify the various types of notes and subject heading standards (e.g. LCSH, LC Thesaurus for Graphic Materials, etc.) that are used in the item level record. The DTD also enables linking between documents—users can link from an item level record to the EAD encoded finding aid—as well as between item-level records, if a relationship has been defined.
File Naming Systems for Multiple Media Collections
Another significant metadata challenge with archival materials is how to incorporate different document types into an online collection. The problems associated with multiple media collections do not generally lie in the presentation of various media, but rather in their preparation for online delivery. The Barren Lands project consists of a variety of documentary forms, all of which needed to be handled in a slightly different manner. For example, published reports required OCR, manuscript letters and newspaper clippings needed to be manually re-keyed, and no additional work was required for maps and photographs. To simplify the development of the digital collection, it was necessary to create a method for quickly identifying the document type for each digital object.
As a form of structural metadata, the file naming structure was used to distinguish between documentary forms. Directories were created for each type of document, such as letters, diaries, published text, maps, photographs, and so on. Then, as each archival document was scanned, a unique identifier, containing a letter to identify the documentary form followed by a five-digit number, was recorded in a relational database. For example, letters were numbered L10001, L10002 and photographs were numbered P10001, P10002. Next, each page comprising a digital object was given a sequential four-digit number. The resulting directory structure is as follows:
| Directory structure for a 2 page letter: | tyrrell/letters/L10001/0001 tyrrell/letters/L10001/0002 |
| Directory structure for a photograph: | tyrrell/photographs/P10001/0001 |
The project team felt strongly that no semantic information be included in the file naming system as this type of information would likely become confusing rather than helpful in the long run. This file-naming system not only ensured that we had a simple, well-organized repository for our images, it also allowed the team to quickly identify which image files required OCR and which files needed rekeying.
Using Structural Metadata to Link Descriptions to Images
Once the images were scanned and item level descriptions complete, the final challenge was to create the linkages between the two. Collecting an adequate amount of structural metadata is critical to this linking process. In the Barren Lands project, structural information such as unique identifiers, page sequence numbers, page numbers as stated on the document, special features such as tables of contents and indexes, and other relevant information was collected in a relational database at the point of scanning. Some descriptive metadata relating to individual pages of the digital object, such as titles of maps or illustrations and content dates were also recorded in the database.
To create a link to the images, the project team followed the method used in the Making of America (MOA) and Early Canadiana Online (ECO) projects—all structural information was embedded in an empty page break <p> element in the body of the item level record. An example of the metadata contained within the <p> element is as follows:
<pb id="tyrrell/text/T10001/0004" n="0" type="ill" title="A Valley in the Barrens" rotate="yes">
What this example indicates is that the fourth page image associated with the digital object numbered T10001 can be found by following the path "tyrrell/text/T10001/0004". This image contains an illustration entitled "A Valley in the Barrens" and it does not have a page number associated with it. Finally, in order to view this image properly, it must be rotated.
Also embedded in the body of the item level record are the OCR or re-keyed text files. The Barren Lands project team decided to follow the practices of the MOA and ECO projects and encode the physical pages of text within the paragraph <p> tag of the item record. While this practice is technically a TEI tag violation, it was a practical decision made to unite the text with the image. The decision to encode document structure to the page level only, using the <p> element, was made to balance the user's resource discovery needs against the labour costs of highly structured encoding. The chosen level of encoding allows the user to search and retrieve text within specific pages; the appropriate page image is then presented to the user. Further structural encoding could have offered some refined searching capabilities, but was rejected as being both too costly and too time-consuming.
For an example of a fully encoded item level record, follow this link.
Administrative Metadata
In addition to descriptive and structural metadata, the Barren Lands project team also captured administrative or technical metadata during the scanning process. As each image was scanned, information relating to the source type, file format, scanning date, and scanner was captured in a relational database. Other types of administrative metadata, such as file compression format, image resolution, and image height and width were captured in the TIFF tags associated with each image. Although this administrative information was not used in the construction of the digital collection, it was important to capture this technical information just in case it was needed in the future.
Conclusion
Metadata creation for archival collections, as with any digital project, is an important and complex undertaking. To create useful and effective metadata, it is necessary to conceptualize how an archival collection will function in an online environment. From our involvement in the Barren Lands project, we have learned that it is essential to spend an adequate amount of time researching metadata requirements and establishing schemes for its creation. By creating metadata according to existing standards and following or carefully extending current practices, we can make certain that our digital collection has both the durability and innovation that will ensure its long-term viability.
Footnotes
(1) Bureau of Canadian Archivists, Rules for Archival Description. Ottawa: Bureau of Canadian Archivists, Planning Committee on Descriptive Standards, 1996. (back)
(2) According to the Rules for Archival Description (Ottawa: Bureau of Canadian Archivists, 1990), fonds is "[t]he whole of the documents, regardless of form or medium, automatically and organically created and/or accumulated and used by a particular individual, family or corporate body in the course of that creator's activities or functions." (back)
(3) The Text Encoding Initiative (TEI) is an international standard for the preparation and interchange of electronic texts for scholarly research. See http://www.tei-c.org/ for more information regarding the standard. (back)
|
Highlighted Web Site The XML Cover
Pages
|
FAQ
I've heard that image files prepared for Web delivery should be scanned at 72 dpi for viewing under MacOS and 96 dpi for Windows, supposedly to match the monitor resolutions used by the two systems. Do I really need to make two derivatives of each image if both Macintosh and Windows users will be accessing my site?
Not only will one copy of each image serve both Macintosh and Windows users, but also the question is based on what appears to be a widely held misconception. A quick search of the Web reveals numerous sites making statements such as:
"If scanning for a Web site or monitor image, scan at 72 dpi."
"You will always need to work in RGB at 72 dpi for the Web. This is because 72 dpi is the resolution of computer screens."
"Monitor resolution is usually 72 dpi (Macintosh) or 96 dpi (Windows)."
" ... images we see on our monitors range from 72 dpi for the Macintosh to 96 dpi for Windows."
"Windows-based Computers and Macintosh Systems operate on different video signals, which is why monitors are not interchangeable between the two platforms. Macintosh computers operate at 72 dpi, while Windows Systems use a 96 dpi signal. Because these video signals are "hardwired" to the computer's system board, they are not changeable. And, it is best to match the resolution of your images to the video signal."
Finding the flaws in these statements requires a review of some scanning and technology basics. Let's examine the underlying assumptions.
Myth #1—Computer monitors use a fixed resolution (72 dpi for Macintoshes, 96 dpi for Windows)
This was partially true in the early days of personal computing. For example, the original all-in-one Macintoshes had a 9" CRT with 512 x 384 pixel dimensions. They produced a fixed image of approximately 72 dpi. However, most modern CRT monitors are multi sync, meaning they can be run at a variety of pixel dimensions.
My home computer is a Macintosh with a 13" diagonal monitor set to 800 dots wide x 600 dots high. The physical dimensions of the monitor image, measured with a ruler, are 10" wide by 7.5" high. So the resolution of the monitor image in dpi is 800 dots divided 10" or 80 dpi. The other dimension gives the same answer, 600 dots divided by 7.5" is also 80 dpi. I can also set my monitor at 640 x 480. Since the same 10" x 7.5" area is used to display the image, the resolution of the monitor declines to 640 dots/10" or 64 dpi.
At work I have a Windows machine with a 19" diagonal monitor. I usually run it at 1280 x 1024. The physical image is 14" wide, so the resolution is 1280 dots/14" or about 91.5 dpi. However, the video circuitry in my computer allows me to choose monitor settings from 640 x 480 up to 1600 x 1200. If I were to set it at 800 x 600, the resolution would drop to 800 dots/14" or about 57 dpi.
In fact, anything that affects the ratio of the image size to the number of dots displayed changes the monitor's resolution, including changing the monitor's horizontal and vertical size adjustments. Clearly there is nothing fixed or magical about 72 dpi or 96 dpi.
Myth #2—When you are looking at an image on a monitor, the resolution of that image is the same as that of your monitor.
Actually, video systems aren't "aware" of the resolution of image files at all. Only the pixel dimensions matter to your video card and monitor. To illustrate this point I have provided examples below.
These instructions are for Adobe Photoshop® 6.0 for Windows, but other image editors could also be used.
I opened a JPEG in Photoshop. I chose 'Image Size' from the 'Image' menu. The top of the Image Size window gave the pixel dimensions for the file and the bottom gave the print size information. Note that resolution is only stated for printing.
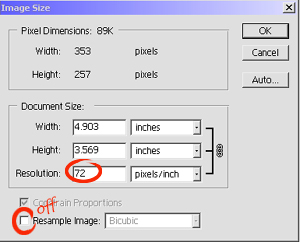
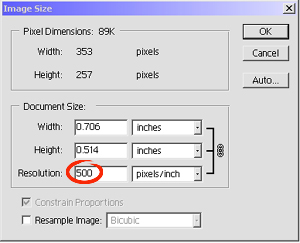
I made sure that the 'Resample Image' check box was not checked. I changed the figure in the resolution box from 72 dpi to 500 dpi. From the 'File' menu I chose 'Save As' and gave the file a new name in order to be able to distinguish it from the original. I then closed the original file.
I reopened both files in Photoshop. As you can see below they appear identical. Same size, same magnification, same detail. There is no way to tell on-screen that the two images will print at completely different sizes. (Note: if you want to compare printouts, save each image from the browser as a separate file and print from an image editor. If printed from the browser, the images will appear the same size because browsers scale images when printing.


Figure 1. The image on the left is 72 dpi and the image on the right has been scaled up to 500 dpi without resampling.
Myth #3—All images should be scanned at a particular resolution (most commonly stated as 72 dpi) for display on the Web
We've established that the resolution of monitors on both platforms can vary quite a bit. Nevertheless, the variety of monitor resolutions that result from different combinations of physical monitor size, size adjustments and other factors should not determine how to scan for Web delivery.
Remember that when set at 800 x 600, my 13" home monitor displays 80 dpi, while my 19" monitor at that same setting displays at 57 dpi. Let's say I were to access an image on a Web site that measures 700 x 500 pixels and view it on both monitors at 800 x 600. The only consequence of the difference between the monitors would be the fact that the image on the 19" monitor would be physically larger. Both images would carry exactly the same level of detail, and both would occupy exactly the same percentage of their respective monitor's available display space.

Figure 2a. 640 x 480 view on 11" monitor;
magnified 4x with respect to original.

Figure 2b. 640 x 480 view on 21" monitor;
magnified 7.3x with respect to original. (1)
However, there are important considerations in planning to scan for Web delivery. The choice for any particular document depends on factors such as the presence of fine detail, the physical dimensions of the document and the tonal range. For most library or archives materials, scanning master files at 72 dpi makes no sense at all. Most materials in libraries and archives contain detail that is finer than scanning at 72 dpi could detect and scanning at that resolution would limit the utilization of the resulting file.
Consider an 8" wide x 10" high text page scanned at 200 dpi 8-bit for full informational capture. The resulting scan will be 200 dots x 8" wide by 200 dots x 10" high or 1600 x 2000 dots and would require about 3.05 Mb of storage in uncompressed form. Such an image would be cumbersome to use on a Web site but there is nothing inherent in monitor technology that prevents us from doing so. If this image were made available to Web users it would take a long time to transmit and would require a lot of scrolling in both directions on a monitor set to an 800 x 600 display (for example, about 1/6 of the image would appear at one time on an 800 x 600 display).
If we scanned at 72 dpi, much detail would be lost. On the other hand, using the 200 dpi digital master for Web access clearly has major drawbacks. In most cases, we would scale the digital master and create a derivative at an intermediate resolution for use on the Web. For more information see the section on presentation in Moving Theory into Practice: Digital Imaging Tutorial.
The choice of how much to scale the image should result from careful consideration of the file size, image quality and image completeness. If it was most important that the complete image appear on an 800 x 600 monitor, we would scale the document until its height was somewhat less than 600 dots, to allow some space for the title bar and border. Cornell has created a calculator in Moving Theory into Practice: Digital Imaging Tutorial for figuring the percentage of an image that is displayed.

Figure 3. Displayed at 200 dpi on an 800 x 600 monitor, one
can only see a small portion of the page (left).
At 60 dpi, the whole page is fully displayed, but at the expense of legibility
(bottom-right).Scaling the image to
100 dpi offers a compromise by maintaining legibility and limiting scrolling
to one dimension (top-right).
Meanwhile, other technological changes are helping to minimize the compromises in making high quality images Web accessible. Increasing deployment of broadband networking eases concerns about file size. New file formats that support high levels of compression with minimal loss of detail and multiple resolution views (e.g. MrSID® and JPEG 2000) also help.
Still confused? The Digital Imaging and Preservation Research Unit at Cornell is developing an application that will allow users to experiment with different scanning and display resolution inputs and to evaluate the impact on file size, image completeness and quality. Watch the pages of RLG DigiNews for an announcement of its availability.
—RE
Footnote
(1) Digital Imaging for Libraries and Archives, Anne R. Kenney and Stephen Chapman, Ithaca, NY: Cornell University Library, 1996. (back)
Calendar of Events
The
Fundamentals of Digital Projects
August 28, 2001, Urbana, IL
September 20, 2001, Urbana, IL
The Illinois Digitization Institute is offering a fall series of free one-day
workshops on the fundamentals of digitization for cultural heritage institutions.
Each workshop will explore the basic theories and practices of digitization
and will include numerous opportunities for hands-on learning.
Intellectual
Property and Multimedia in the Digital Age: Copyright Town Meeting
September 24, 2001, New York, NY
October 27, 2001, Cincinnati, OH
November 19, 2001, Eugene, OR
The National Initiative for a Networked Cultural Heritage will offer three
more Copyright Town Meetings for the cultural community during the year 2001.
Issues to be covered include intellectual property and multimedia, creating
policies, and strategies.
Computing
Arts 2001, Digital Resources for Research in the Humanities
September 26-28, 2001, Sydney, Australia
Computing Arts 2001 seeks to bring together scholars, academic researchers,
publishers, librarians and archivists in the region and beyond, with key speakers
in the field, to exchange ideas and to extend the use of digital resources,
techniques and tools in humanities research and teaching.
DC-2001: International
Conference on Dublin Core and Metadata Applications
October 22-26, 2001, Tokyo, Japan
DC-2001, ninth in this series, is an international conference for the broader
metadata community. It will provide a forum to discuss further development of
the Dublin Core and related metadata standards. There will be an exchange of
ideas and tutorials on the creation, management, and use of metadata applications.
Announcements
New Web site on National
Academies and Intellectual Property
The Science, Technology and Economic Policy (STEP) board has launched a new
Web site, which will serve as a guide to the Academies' extensive work on intellectual
property and a forum to discuss ongoing projects.
Metadata Encoding
and Transmission Standard
The METS schema is a standard for encoding descriptive, administrative, and
structural metadata regarding objects within a digital library, expressed using
the XML schema language of the World Wide Web Consortium. The standard is maintained
in the Network Development and MARC Standards Office of the Library of Congress,
and is being developed as an initiative of the Digital Library Federation.
Sun
Microsystems Inc. Digital Library Toolkit Second Edition
This second edition is an update of the original April 1998 edition.
National
Library of Australia: Electronic Information Resources Strategies and Action
Plan 2001-2002
Now available on the Web is the National Library of Australia's strategies and
action plan in relation to Australian electronic resources. Issues covered include
collecting, preservation, access, and support for sharing of electronic resources.
The European Library
(TEL)
The British Library is coordinating a planned single European library in the
TEL project. The goal is to create a new virtual library that will allow searching
and access to digital and other collections. The objective of TEL is to set
up a cooperative framework that will lead to a system for access to the major
national and deposit collections in European national libraries. TEL will investigate
how to make a mixture of traditional and electronic formats available in a coherent
manner to both local and remote users.
Open
Archives Initiative Protocol
A multiple disciplinary group has posted details of the Open Archives Initiative
Protocol for Metadata Harvesting (OAI), designed to supply and promote an application
independent interoperability framework that can be used by a variety of communities
that publish content on the Web.
Web site for
The Andrew W. Mellon Foundation's e-journals archiving program.
The Digital Library Federation is maintaining a Web site for a program funded
by The Andrew W. Mellon Foundation and involving seven grant-funded research
libraries in processes designed to plan the development of e-journal repositories.
The seven libraries participating in the process are the New York Public Library
and the university libraries of Cornell, Harvard, MIT, Pennsylvania, Stanford,
and Yale. The site contains original project proposals, working papers, and
occasional progress reports on the planning projects.
![]()
Publishing Information
RLG DigiNews (ISSN 1093-5371) is a newsletter conceived by the members of the Research Libraries Group's PRESERV community. Funded in part by the Council on Library and Information Resources (CLIR) from 1998-2000, it is available internationally via the RLG PRESERV Web site (http://www.rlg.org/preserv/). It will be published six times in 2001. Materials contained in RLG DigiNews are subject to copyright and other proprietary rights. Permission is hereby given for the material in RLG DigiNews to be used for research purposes or private study. RLG asks that you observe the following conditions: Please cite the individual author and RLG DigiNews (please cite URL of the article) when using the material; please contact Jennifer Hartzell, RLG Corporate Communications, when citing RLG DigiNews.
Any use other than for research or private study of these materials requires prior written authorization from RLG, Inc. and/or the author of the article.
RLG DigiNews is produced for the Research Libraries Group, Inc. (RLG) by the staff of the Department of Preservation and Conservation, Cornell University Library. Editor, Anne R. Kenney; Production Editor, Barbara Berger Eden; Associate Editor, Robin Dale (RLG); Technical Researchers, Richard Entlich and Peter Botticelli; Technical Assistant, Carla DeMello.
All links in this issue were confirmed accurate as of August 12, 2001.
Please send your comments and questions to preservation@cornell.edu.
![]()
Want a faster connection?
Trademarks, Copyright, & Permissions