



- Editor's Interview
Collaboration of RLG/OCLC With Digital Archiving Initiatives, an Interview with Robin Dale and Meg Bellinger
- Feature Article
- Highlighted Web Site—eXtensible Name Service
- FAQ—Image Search Engines
- Calendar of Events
- Announcements
Editor's Interview
![]() Collaboration
between RLG and OCLC With Digital Archiving Initiatives
Collaboration
between RLG and OCLC With Digital Archiving Initiatives
Robin Dale
Robin.Dale@notes.rlg.org
Meg Bellinger
bellingm@oclc.org
Editor's Note
Our interviewees are Robin Dale, Program Officer, Member Programs and Initiatives,
Research Libraries Group and Meg Bellinger, Vice President, OCLC Digital &
Preservation Resources. Robin leads one of RLG's key initiatives, the Long-term
Retention of Digital Research Materials, as well as RLG's PRESERV community,
a program that focuses on preserving and improving access to endangered research
materials. Meg is responsible for establishing services that help libraries
and other cultural institutions create, access and preserve existing collections;
collaborate to build new digital collections; and learn about digitization and
preservation issues.
Anne R. Kenney, Editor
In March 2000, RLG and OCLC issued a joint press release indicating that the two organizations were going to cooperate to create infrastructure for digital archiving. How did this collaboration come about?
Robin: Prior to March 2000, a number of ideas for cooperative initiatives coalesced during a meeting between Jim Michalko (RLG's president) and Jay Jordan (OCLC's president). Agreement for cooperative activities on several fronts, including digital archiving, came out of that meeting. Both organizations identified two activities as being of primary importance—the development of a framework for a reliable digital archive for the library, archive and museum community; and the identification and development of a framework for preservation metadata elements. As well, the chosen activities paralleled nicely with RLG and OCLC's desire to operate within the context of existing or emerging international standards and best practices. Since both organizations were already participating in the emerging Open Archival Information System (OAIS) Reference Model, it was decided to incorporate the promising model into both activities.
Your first two collaborative efforts are focusing on preservation metadata and attributes of a digital archive. It appears that OCLC is taking the lead on the former and RLG on the latter. Is this true?
Both: Yes. With Dublin Core, metadata harvesting, CORC and MARC-related activity in its portfolio, OCLC has obvious bona fides in the metadata area, so it was natural that OCLC lead that activity. At the same time, RLG has been actively pursuing digital archiving activities for the past 7 years. Early cooperative activities with the Commission on Preservation and Access led to the Task Force on the Archiving of Digital Information's seminal report, Preserving Digital Information. Follow-on activities addressed many of the recommendations from the report through working groups composed of RLG PRESERV members. The result is that RLG has established quite a body of work and experience in this area and so it was natural for us to take the lead on developing attributes of a digital archive.
Meg can you describe the rationale and work to date on the joint preservation metadata initiative? What future activities are planned in this area, both at OCLC and jointly with RLG?
Meg: The rationale for the work was based on the recognition that excellent work had been done in a number of test bed environments and what was needed was an authoritative synthesis of this before further work could be undertaken.
Composed of the planning committee (OCLC & RLG staff) and 11 experts from organizations around the world, the working group brings together key stakeholders in the area of digital preservation to review existing practices, share expertise, and identify best practices and common approaches.
The OCLC/RLG Preservation Metadata Working Group articulated two primary goals to pursue.
First, to develop a comprehensive preservation metadata framework applicable to a broad range of digital preservation activity. The benefits of such a framework are that it would provide a template for institutions beginning new initiatives, contribute to future interoperability of digital archival repositories; and facilitate the inclusion into the metadata creation process of information producers and others external to the archive.
Second, to review the existing implementations and recommend a metadata framework for libraries to use to guide and inform their own digital preservation efforts. This will be reported in two parts; content information and preservation description information.
The first paper, a 50-page review of the state of the art, focuses on the Open Archival Information System (OAIS) reference model and how that document has informed the development of preservation metadata in four different initiatives. The second white paper, on content information, examines concepts and issues, recommends a hierarchy of the elements that is more specific than in OAIS and is geared to the library community. It includes an expansion of the conceptual model and a metadata set. A similar white paper on preservation description information is forthcoming. The hope of the working group is that libraries will use these papers to guide and inform their own digital preservation efforts.
The OCLC/RLG Preservation Metadata working group's white papers are an important contribution to digital preservation research. This activity is significantly informing OCLC's development to create a digital preservation service. The development of the digital archive is one of the major initiatives in OCLC's strategic plans for the next three years. As such, we will continue to be heavily engaged in the OAIS work as well as other initiatives such as METS.
As we come closer to the completion of the current areas of collaboration, OCLC and RLG will examine where it makes the most sense to continue to lend our mutual support.
Robin, can you tell us about the rationale and work to date on the efforts to characterize reliable archiving services? What are the next steps for RLG and for the collaboration with OCLC in this area?
Robin: The rationale behind the work is fairly simple. RLG has continued to address the recommendations from the 1996 Task Force report in order to meet the needs of our member institutions. One of those recommendations called for the development of a "deep infrastructure" to support reliable digital archiving, and several significant global developments and successful projects have informed us enough to move forward and begin to articulate key elements within such an infrastructure. Secondly, having been involved with and invested in the development of the emerging international standard of the OAIS, we believe that the reference model is of great value to institutions developing digital repositories. At the same time, the OAIS document can be daunting (over 140 pages) to the non-specialist, so we are combining promulgation and educational efforts and explaining key elements of the model in straightforward language, accessible to all members of the research resources community.
The efforts to characterize reliable digital repositories—a clarification the working group has advocated—have been fairly successful thus far. The working group produced a draft report that identified both the attributes and responsibilities of trusted digital repositories. The report also identifies certification as a key component for measuring performance and reliability of digital repositories and articulates a framework for the development of a certification program. The draft was released for public review in August 2001 and the resulting comments submitted by interested parties are now being incorporated into the final document.
The final report from this joint working group will go a long way towards articulating the requirements of digital repositories that take on long-term maintenance, storage, and possibly access to research resources. The report will also identify and provide a way forward for critical next-step activities that have yet to be tackled, including the design and implementation of a certification program. When completed, we will be able to offer tools and guidance for institutions with responsibility for digital collections—whether an institution is creating its own repository, working in conjunction with publishers, or planning to contract for third-party services. Collaborative opportunities with OCLC will undoubtedly be articulated in the recommendations of the final report or through community input. Specific areas for joint activity will become clearer within the next few months.
Both organizations have inaugurated major initiatives in digital archiving. RLG has identified the long-term retention of digital research resources as one of its top priorities in this decade, and OCLC has launched a digital archiving program. How do these two efforts complement each other?
Both: Part of RLG's long-term retention initiative includes the construction of a testbed digital repository for research resources such as digital materials from the Marriage, Women and the Law collection, which resulted from the 1996-1998 Studies in Scarlet project. The first phase of OCLC's project involves the capture, creation of preservation metadata, ingest, and dissemination of Web-based documents from the Government Printing Office and several other organizations. Hence, the types of documents being tested by each organization are complementary rather than duplicative.
RLG's testbed will not only test the premise of a reliable digital repository, but will also test some of the tools we believe will contribute to the long-term retention of these materials—notably, the Metadata Encoding and Transmission Standards (METS) and the preservation metadata framework being developed by the joint OCLC/RLG working group.
OCLC's digital archive development is occurring in tandem with both of the collaborative efforts. Therefore OCLC's current practical implementation is both informed by and informing the activity of the working groups.
Are there other plans for joint digital preservation initiatives?
Robin: We anticipate the recommendations from the final report to suggest other areas for further collaboration. Once that is done, we can evaluate the prioritized activities and see where collaborative activities make sense.
Our initiatives and the digital preservation initiatives as a whole are part of a larger international community effort. The goal right now is to get the recommendations and tools out to the community and the future will likely see us working side-by-side as part of larger community efforts.
You have collaborated on reports and recommendations, but have you given consideration to collaborative programs?
Robin: Further collaborative opportunities with OCLC and others will be articulated in the recommendation of the final report and through community input. Collaborative programs are not out of the question, but we will have to wait and see what is needed.
Meg: At OCLC we are introducing a Digital and Preservation Co-op which will be the administrative home for ongoing collaborative programs in multiple areas—development of best practices for digitization and archiving, digital content creation, and educational development opportunities. With 40,000 participating libraries, OCLC needs to serve a wide range of needs and we can only achieve this through collaborative effort.
What do you see as the greatest obstacles to overcome in digital preservation?
Robin: Current obstacles to digital preservation can be categorized into three broad groups: legal, economic, and organizational. And based on what I have heard at several digital preservation-related meetings in the past few weeks, I think most people would agree with this.
In the United States, the Digital Millennium Copyright Act restricts what libraries and archives are permitted to do to preserve digital information. So too, do licensing agreements with publishers. As we begin to think in terms of international cooperation and collaboration to preserve digital information, the often-conflicting rights laws of different nations will cause further problems. Intellectual property issues will be difficult to address and laws will be difficult to change, but changes are critically needed.
The economics of digital preservation present another obstacle. Why? We just don't know how much it will cost. Several institutions and organizations have produced documents that discuss some of the economic issues, but we lack actual models and concrete figures that would allow us to calculate the real cost of real activities in production environments. Further, we cannot yet answer the question “Who will or should bear the cost of digital preservation?” We need to know much more about how costs can most effectively be shared across regions and nations, sectors and consortia. And we need reliable models for cost-sharing that can be tested and evaluated by a range of groups in production environments. The economic obstacles can only be addressed through experience.
Finally, most libraries and archives lack the organizational infrastructure necessary to support digital preservation. This widely-acknowledged problem was first identified and articulated in the Task Force on Digital Archiving's report Preserving Digital Information. Over the past several years, initiatives such as the OAIS and the RLG/OCLC working groups have worked to address the complex challenges within the organizational infrastructure domain. As well, larger institutions have begun to restructure and reposition themselves to meet the needs of their increasingly digital collections. Collectively, these collaborative and individual efforts are beginning to inform and provide guidance for the larger, international community. Some thorny issues have yet to be resolved in this area though projects and collaborative initiatives now underway continue to examine and address them. I am anxious to see the activities and results that the coming year will bring.
![]() Emulation vs. Migration:
Do Users Care?
Emulation vs. Migration:
Do Users Care?
Margaret Hedstrom and
Clifford Lampe,
University of Michigan
hedstrom@umich.edu
cacl@umich.edu
Introduction
Determining user needs is a prevalent dilemma for librarians and archivists.
For whom is information being saved, and how is that best accomplished? In recent
discussions of emulation and migration as digital preservation strategies, the
issue of adequate preservation has necessarily raised the specter of both current
and future user needs as a factor in choosing preservation methods. This paper
will discuss the application of user needs analysis to an evaluation of digital
preservation strategies, present initial findings, and discuss additional research
based on user testing to evaluate different approaches to digital preservation
(1).
The research discussed in this paper is part of the on going CAMiLEON project being conducted jointly at the University of Michigan, School of Information and the University of Leeds in the UK. CAMiLEON is a three-year International Digital Library Initiative Project funded by the National Science Foundation and the Joint Information Systems Committee. The goals of the CAMiLEON Project are to test the feasibility of emulation as a digital preservation strategy, to evaluate its effectiveness in preserving the original "look and feel" and behavior of various types of complex digital objects, and to define the attributes of different types of digital objects that must be preserved to satisfy user needs and requirements. As described in the August 2001 issue of RLG DigiNews our colleagues at the University of Leeds are conducting most of the research on the technical feasibility of emulation. The University of Michigan team is conducting user assessments of various approaches to digital preservation.
Emulation and Digital Preservation
The most widely used methods for preserving digital information involve a combination
of adopting standards that limit the variety of digital formats that a digital
repository accepts, converting digital materials to a standard format when they
are accessioned into a digital repository, and migrating the digital information
from obsolete to current formats so that the information can be accessed using
current hardware and software (2). In today's digital environment,
electronic resources are increasingly being made available in multi-media formats,
with the intellectual content being bound to the structure, form, and behavior
of the digital medium in which it has been produced or published. This presents
particular challenges for long-term preservation, not only in terms of the technical
solutions required to preserve data where the look and feel may be an integral
part of understanding the intellectual content of the digital object, but also
in terms of collection management decisions and cost-benefit implications of
preservation decisions.
Some computer scientists have proposed emulation as an alternative strategy for long-term preservation. According to this approach, emulation of obsolete systems on future unknown computer platforms would make it possible to retrieve, display, and use digital documents with their original software. Recent research has begun to demonstrate the feasibility of several different technical approaches that use emulation to preserve digital objects (3). One purported advantage of emulation is that this approach retains not only the intellectual content of digital information, but also the "look and feel" and functionality of the original. With the exception of the research reported in this paper, however, there are no empirical studies that evaluate the effectiveness of emulation in preserving the original look and feel or behavior of digital information. In fact, user needs rarely have been taken into account in choosing preservation strategies. This is particularly problematic for digital information because preservation methods that preserve features, behaviors, or attributes of documents in excess of what users need will be costly and wasteful; whereas methods that fail to retain all of the attributes or functionality that users need may preserve digital information that is not useful to researchers.
What can we learn from users?
One goal of the CAMiLEON Project is to assess users' needs and requirements
for preserved information. Hedstrom has argued that the requirements of libraries,
archives, and other custodians for simple, affordable, and easily implemented
preservation methods may not satisfy all of the requirements of current and
future users.
By making preservation requirements explicit from both the users' and custodians' perspectives, libraries and archives will be better able to balance competing demands and to integrate digital preservation into overall planning and resource allocation (4).
The focus of this work is on developing a more explicit understanding of end user requirements and on evaluating how well different preservation methods meet those requirements. User testing can play an important role in understanding user requirements by assessing user needs in relation to archived digital objects that are preserved via different methods, such as reformatting, conversion, and emulation.
The CAMiLEON project uses methods based on research in the field of Human-Computer Interaction (HCI) to analyze the needs and preferences of end users. HCI uses a wide range of techniques to assess the effectiveness of developed systems and to determine user habits and behaviors in terms of needs. Olson lists several types of research that can be applied to the assessment of user needs (5). Methods include lab and field observations, interviews, focus groups, and surveys. It is also important to note that there is a crucial difference between the purpose and types of user studies commonly used for HCI research and user studies to inform decisions about digital preservation. Most HCI research is intended to improve the design of current systems for current users and for tasks that are known or can be readily envisioned. In the case of digital preservation, we are gathering data from current users to inform decisions that will affect the usability of preserved digital objects in the future. Although the subjects of our research are proxies for future users, we believe that they can supply useful insights for evaluating digital preservation methods.
Users, Migration, and Emulation
We started with an empirical test of users' interaction with a computer game
that was preserved using both emulation and migration. We chose a computer game
because it is a good example of a legacy digital object that is highly platform-dependent
with many complex characteristics, including screen display size and resolution,
color graphics, input/output speed variation, and user interactivity. Similar
features are prevalent in contemporary complex digital objects, such as dynamic
Web pages. We selected Chuckie Egg, a game that was popular in the United Kingdom
in the mid-1980s, as our digital object. Chuckie Egg is a "vertical maze"
game where a player-controlled character climbs ladders, jumps chasms, and avoids
killer characters in order to pick up some item. The game was originally developed
for the BBC Micro, a microcomputer of similar vintage to the Apple IIe in the
US. There were two advantages to using the Chuckie Egg game. First, three different
versions of the game were available: the original game that ran on the BBC Micro,
a disk image that could be played on a BBC emulator, and a migrated version
where the program code had been rewritten for a Windows platform. Second, because
the original Chuckie Egg game was written to run on a platform that was only
available in the UK, we expected that our research subjects (university students
in the United States) would be unfamiliar with the original game. This created
a situation that is more analogous to future use scenarios, where users of preserved
digital objects will not have experience using the original and long obsolete
hardware and software.
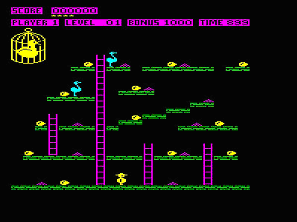
Figure 1. Screenshot from Chuckie Egg
We acquired and set-up a working BBC Microcomputer. Participants were asked to play the game on the original equipment for one hour. After completing the training session, they switched to one of two conditions on a modern PC. One group played the version of the game that emulated the BBC Micro and the other group played the migrated version. All interactions were taped for later coding analysis. In order to measure performance, participants were asked to complete the end of the second level of the game as quickly as possible. After recording completion time, they were asked to play again, and time was recorded. After the second timed trial, participants played one more game during which they talked out loud about differences they noticed between their test condition and the training condition. Each participant also filled out a questionnaire asking about different dimensions of user satisfaction and perceived ease of use. Project staff compared the ratings between the two groups using t-tests.
Findings
We collected a variety of data to measure four aspects of the user experience:
There were no statistically significant differences between subjects in the migrated and emulated condition on the measures of satisfaction and perceived ease of use. Irrespective of experimental condition, the game was considered easy to use, while satisfaction fell almost in the middle of the scale. On the performance measure, there was no significant difference between times to reach level two, or in time difference between levels one and two.
Qualitative data on differences that users noticed between playing the game on the original BBC Micro and in the emulated or migrated condition is more interesting than the statistical data on user behavior. The following chart provides comments from the experimental groups about the differences they noticed between playing the game on the original BBC Micro and the migrated or emulated test condition.
| Emulation Group | Migration Group |
|
"The screen is more squished together." "There's a new bar," (The bar related to an artifact from the emulation software.) "Character flashes, makes it easier to recognize" "Seems easier, but that could be related to the keyboard." "I liked the other screen better, it reminded me of the last time I played a game like this." "The keys are nicer, a softer touch." "The character can jump farther." "Nicer than the first one." "Screen seems vertically compressed." "Might be a little softer, or it could be the hardware." "Looks like the screen is scrunched." "All elements move faster, can get through the levels quicker." |
"Blue birds are smarter." "Seems faster." "Different from the Commodore 64 feeling you get with the first one." "Sounds are a little sloppier." "The (increased) speed makes it a little harder to time your jumps." "The old version flickers more." "You can see Chuckie's legs, which makes it easier to time stuff." "Can jump further, and catch stuff above you, which you couldn't do before." "Sounds are more annoying." "Keyboard makes it easier to control Chuckie." "Better looking because the pixels aren't so big." "Something different about how it responds, I think it's the keyboard." |
| Figure 2: Subjects' Answers to the Question: "What Differences Did You Notice Between the Original Version of the Game and the Second Game You Played?" |
Discussion
The Chuckie Egg study is, to our knowledge, the first empirical test of the
theory that emulation better preserves the original "look-and-feel"
of digital objects. The assertion that emulation better preserves original "look-and-feel"
is based on the fact that the user interacts with an exact copy of the original
bit stream running on an emulator that mimics the behavior of the original computing
environment. Migration, on the other hand, may involve conversion, reformatting,
or rewriting the program code so that the preserved digital object is compatible
with a current computing environment. Given the assertion that emulation is
a better method for preserving the original look and feel and behavior of complex
digital objects like the Chuckie Egg game, we expected that the subjects who
played the game in the emulated condition would find it more like the original
than those who played the game in the migrated condition. The fact that we found
no statistically significant differences in users' satisfaction, performance,
or perceived ease of use raises a number of questions about the benefits of
emulation versus migration as a digital preservation strategy.
The lack of statistically significant differences between the users who played the migrated and emulated versions of the game suggests that high-level comparisons of emulation versus migration may not produce results that can be used meaningfully to evaluate different digital preservation strategies. As both Charles Dollar and Paul Wheatley have argued, migration is not a single, unified concept. Rather there are different types of migrations that entail varying degrees of change to the original digital object (6). Likewise, all emulators are not equally effective at reproducing the behavior of the original computing platform. Emulating the behavior of input and output devices, such as the keyboard, joystick, display, and tape or disk drive, are notoriously difficult problems in computer science, yet interacting with these aspects of the original computing environment are particularly consequential to the experience of using a complex interactive object like a computer game. Based on casual comparison of the migrated and emulated versions of the Chuckie Egg game and on anecdotal evidence about the quality of these two versions, we suspect that the migrated version did a better job of reproducing the behavior of the original game than the emulated version. Future comparisons of emulation and migration need to take into account the type and quality of the emulated and migrated objects that are being compared.

Qualitative feedback from our test subjects about differences between playing the game on the original BBC Micro and playing either the emulated or the migrated version on a current PC platform has encouraged us to further refine what we mean by original "look and feel." Many of the differences that users observed between the original BBC Micro and the test condition, whether emulated or migrated, concerned the hardware environment. Many users noted differences between the quasi-mechanical BBC Micro keyboard and the modern PC keyboard, and several noted differences in the screen display, including aspect ratio, size, resolution, and flickering. If a goal of digital preservation is to preserve or replicate the original experience of interacting with a digital object, this raises questions about how to circumscribe the experience that we are attempting to preserve. Given that it is technically impossible to preserve obsolete hardware, such as processors, screens, and keyboards, should we nevertheless attempt to emulate all aspects of the hardware environment? If not, which aspects really matter to users? Qualitative data from our subjects also raises questions about the appropriate balance between preserving as much of the original authentic experience as possible and the usability of preserved digital objects. Many users reported that both the emulated and migrated versions of the game were easier to play using the modern PC keyboard even though this changed the experience of playing the game on the original BBC Micro hardware.
A striking finding from this limited test was the sensitivity of users to small changes in the digital object. Users noticed small differences in graphics, sounds, character motion, and speed of game play. Although some of these attributes may be unique to interactive games, this user test suggests that archivists and librarians need a much more refined definition of the characteristics of digital objects that may warrant preservation, regardless of whether emulation or migration is the preferred technical strategy. Users in our study identified attributes such as motion, speed, and sound quality, which are present in many contemporary interactive digital objects but have received scant attention in discussions of digital preservation.
We are not prepared to draw any definitive conclusions about the effectiveness of emulation or migration based on this initial user test. Our attempt to advance the application of user needs analysis to digital preservation is proceeding. We are conducting more tests on different versions of preserved textual documents and on Web pages where different features are preserved. Future tests will expand techniques to determine the sensitivity of users to changes in digital objects that result from preservation methods and identify which significant attributes of digital objects matter when they are altered or lost.
Conclusions
Based on our initial user test we can draw two broad conclusions about digital
preservation strategies and user testing. First, emulation is not necessarily
superior to migration for preserving the original look and feel of complex digital
objects. We compared emulated and migrated versions of a computer game on performance,
perceived ease of use, satisfaction and "sameness" in the two conditions.
Our results showed few significant differences between the two groups. This
suggests that a high quality migration can be as effective as emulation in preserving
the original look and feel of complex digital objects. Further research on the
effectiveness of emulation and migration needs to account for the quality of
the emulator, the impact of specific approaches to migration on document attributes
and behaviors, and on numerous aspects of the original computing environment
that may affect authenticity and user experience.
Second, user needs analysis and testing can inform choices of digital preservation strategies and suggest areas for further research. The subjects in our study noticed numerous differences between the original computer game and both the migrated and emulated versions. Without observations from users, we would not have noticed many of these attributes. Our user test also suggests that there may be a tension between preserving authentic digital objects and their usability. In some cases, users may prefer versions of digital objects that have been converted to run in a current operating environment even though they deviate considerably in their look and feel and behavior from the original object. The CAMiLEON project is conducting additional user studies in order to substantiate or reject this claim and to develop a clearer understanding of the attributes of digital objects that need to be preserved to make them usable for particular purposes.
Footnotes
(1) For additional information on the CAMiLEON Project, see http://www.si.umich.edu/CAMILEON. Support for the US portion of this research is provided by NSF Award # 9905935.
(2) Margaret Hedstrom and Sheon Montgomery, Digital Preservation Needs and Requirements in RLG Member Institutions : A study commissioned by the Research Libraries Group (December 1998), Mountain View, CA: RLG.
(3) Jeff Rothenberg, Avoiding Technological Quicksand: Finding a Viable Technical Foundation for Digital Preservation, (Washington, D.C.: Council on Library and Information Resources, January 1999); See also, Jeff Rothenberg and Tora K. Bikson. Carrying Authentic, Understandable and Usable Digital Records through Time (RAND Europe,1999); Raymond A. Lorie, "Long Term Preservation of Digital Information," in Proceedings of the First ACM/IEEE-CS Joint Conference on Digital Libraries, Roanoke, VA, June 24-28, 2001 (New York: ACM, 2001), pp. 346-52; and David Holdsworth and Paul Wheatley, "Emulation, Preservation, and Abstraction," RLG DigiNews 5: 4 (August 15, 2001).
(4) Margaret Hedstrom, “Digital Preservation: A Time Bomb for Digital Libraries,” Computers and the Humanities 31: 3 (1997), pp. 189-202.
(5) Judy Olson and Tom Moran, “Mapping the Method Muddle: Guidance in Using Methods for User Interface Design,” in M. Rudsill, C. Lewis, P.B. Polson and T. McKay, eds., Human-computer interface design: Success cases, emerging methods, and real world contexts (New York: Morgan Kaufmann, 1996), pp. 269-302.
(6) Charles M. Dollar, Authentic Electronic Records: Strategies for Long-term Access (Chicago, Ill.: Cohasset Associates, 1999). See also, Paul Wheatley, "Migration—a CAMiLEON discussion paper," Ariadne 29 (September 2001).
|
Highlighted Web Site eXtensible Name Service
|
FAQ
Several Web search engines now offer an "Image Search" option. How is the searching accomplished and how well do these work for finding specific images on the Web?
In the December 15, 2000 RLG DigiNews, this feature examined the state of inventories of digitized collections on the Web. At the time, we bemoaned the lack of coordination amongst the existing inventories and the absence of item-level access to images across collections. With image search capabilities now appearing in association with some of the Web's largest and most comprehensive search engines, it is natural to wonder whether a mechanism for finding images that meet specific criteria is finally at hand.
The state of image searching on the Web
It wasn't too long ago that searching for images on the Web was a rather
crude proposition. One could do a text search that combined some keywords related
to the "subject" of the image along with the terms "gif"
or "jpg" and hope that the resulting page would contain a relevant
image. Results were unpredictable, slow (since you had to load each Web page
to see if it included a desired image), and often disappointing.
Today, there are enough image-specific search facilities that they merit a separate category in inventories of search engines (see, for example, the BIG Search Engine Index). There is even a meta-search engine for images called Ithaki that simultaneously searches six different image search engines.
However, the available image search facilities differ significantly in function and content. Yahoo's Picture Gallery, for example, provides access to copyrighted stock photographs and fine art images from specialized collections such as Corbis. Others utilize member-provided photographs, like Excite's Webshots, or combine professional photos with Web-derived images such as GoGraph. These private collections are not evaluated in this FAQ. Also not included are search engines, such as Hotbot, that allow a search to be narrowed by specifying that the pages returned must include an image, but that don't index the images themselves.
Table 1 provides a rundown of search engines that attempt to index publicly accessible image files available on the Web.
A few notes about the image search engines. With the exception of FAST and Lycos, the engines profiled here seem to be based on truly different collections of images. FAST and Lycos are clearly related, since they often return the same images, in the same order. However they are not identical. FAST has a much superior interface, allowing more sophisticated filtering of results. Also, some identical searches given to Lycos and FAST generate different results, including different numbers of hits and different ordering of hits. In some of our test searches, Lycos presented more relevant images in its initial listing than FAST.
The Cobion image search engine is used at several different German Web sites. The Cobion demonstration site is in English and has more filtering options than the German sites that use it, but it only displays the first 24 images returned from a search. In some cases we used DINO Online to complete searches using the Cobion engine.
| Site Name | Text search features | Image search filters | Presentation features | Mature Content Filter |
| FAST search or alltheweb advanced image search | Boolean AND, Boolean OR, exact phrase | File format (JPEG,
GIF, BMP); Bit depth (color, grayscale, line art); Background (transparent, non-transparent) |
Thumbnail, file name, text excerpt, pixel dimensions, file size, file format, mime type, last modified date, transparency, links to page and image | available |
| Google advanced image search | Boolean AND, Boolean OR, Boolean NOT, exact phrase | File format (JPEG,
GIF); Bit depth (Full color, grayscale, black and white); Domain; Size (icon, small, medium, large, etc.) |
Thumbnail, file name, pixel dimensions, file size, links to page and image | available |
| altavista advanced image search | Boolean AND, Boolean OR, Boolean NOT, exact phrase | Bit depth (color, black
and white); Image type (photos, graphics, buttons and banners); Top level domain, host, HTML title and URL text |
Thumbnail, file name, pixel dimensions, file size, text of ALT tag, link to page | available |
| Lycos multimedia | Boolean AND, Boolean NOT, exact phrase | Thumbnail, pixel dimensions, file size, link to page | available | |
| Ditto | Thumbnail, file name, keywords, pixel dimensions, file size, page title, links to page and image | always on | ||
| Picsearch | Bit depth (color, black
and white); Image type (animation or still); Size (horizontal pixel dimension) |
Thumbnail, file name, keywords, pixel dimensions, file size, file format, number of colors, links to page and image | always on | |
| Cobion
DINO online |
Search for text OCR'd from image | Cobion
only: File format (JPEG, GIF, BMP); Bit depth (color, black and white) Cobion and DINO online: Image type (photos, graphics, exclude banner ads); Image content (with or without people) |
Thumbnail, pixel dimensions, file size, links to page and image | available |
How image search engines work
It's no coincidence that many of the image search engines are offered by
the same services that also offer text indexing of the Web. The Web crawlers
employed by altavista, Google, Lycos, etc. travel from Web site to Web site,
pulling in the contents of Web pages. These pages form the basis for the familiar
text searching indexes. Since image files linked to by the Web pages can be
identified by MIME type or file extension (e.g. GIF, JPG or PNG) and downloaded
by the same Web crawlers, cataloging images is a natural extension of what the
search engines are already doing.
The difficulty comes in deciding how to index an image so it can be searched using text. The simplest and most automated way is to use the text "near" the image. Candidates for indexing that are closest to the image include its file name (which may be cryptic and include abbreviations), its caption (which may not be easy to identify without human intervention) or the HTML ALT tag, sometimes used to provide a verbal description of an image for users of non-graphical browsers or for visually impaired users. Text that is not as closely affiliated with a particular image, such as the directory name, the HTML page title, or other text that appears on the same Web page can also be indexed, though its utility in identifying the content of a particular image is more dubious. Use of the ALT tag is now a requirement for ADA (Americans with Disabilities Act) compliance and should see increased use.
If all the image search engines based their indexing on the same text, one wouldn't expect much variation among them, but refinements to the process do make a difference. Although most of the sites don't go into much detail about how they create their indexes, those that do provide some insight into the process.
For example, Google claims that it "analyzes the text on the page adjacent to the image, the image caption and dozens of other factors to determine the image content" and that it "uses sophisticated algorithms to remove duplicates and ensure that the highest quality images are presented first in your results." In other words, steps are taken to try to improve the relevance of images displayed. Techniques might include giving heavier weighting to text more tightly bound to the image (such as the ALT tag) as opposed to text that simply appears on the same page. Also, taking into account which images are most often selected by users in response to particular searches could be used to improve relevance over time. Google uses a similar technique (usually referred to as relevance feedback) to improve the relevance of its Web site searching.
Ditto, which is exclusively an image search engine, claims that it achieves improved relevance by employing "a proprietary filtering process that combines sophisticated automated filtering with human editors." Similarly, Picsearch claims that it has a "relevancy unrivalled on the web due to it's [sic] patent-pending indexing algorithms." As with Google, details are not provided.
Other approaches to searching for images are available. The main alternative to text-based searching of images is called content-based searching or pattern matching. Content-based searching takes into account visual characteristics of an image, such as color, texture, and shapes. Automated systems for analyzing images for content have been undergoing development for many years, but many are still confined to the lab. A few of the more mature technologies are available commercially, such as IBM's Query by Image Content and Excalibur's Visual RetrievalWare.
However, retrieval engines for Web images that have used content-based retrieval techniques have not had much success yet. Columbia University's WebSEEk performs a color analysis of the images it catalogs and can search for images within categories that match particular color profiles. But the site has not been updated much since it indexed over 650,000 images back in 1996. More recently, Bulldozer Software offered the Diggit! search engine to demonstrate its content-based image retrieval software. Premiering in February 2001 with 6 million Web images and expanding to 12 million in June, Diggit! attracted initial praise, but by late July, it had shut down, citing lack of venture capital.
It is not clear whether any of the search engines profiled here use content-based searching. Cobion claims to employ "visual content image search" and "deep image search" technology, but Cobion's user interface does not allow searches that specify visual characteristics of the desired image, except in broad categories. For example, one can specify that a search must contain images of people, or must not be a banner ad, but not that it must include certain colors, shapes or textures. It is possible that Cobion uses some form of pattern matching to automatically classify images into categories that correspond to the filters available when searching. However, they have not made content-based searching directly available to end users.
How well do they work?
In order to assess the functionality of the image search engines, we carried
out several informal tests. First we looked at how well the engines could find
relevant images of a particular item, using descriptive vocabulary. Some sample
searches were chosen for their interest to the RLG DigiNews audience,
others to test the ability of the search engines to accommodate ambiguity.
Table 2 shows the results of our efforts to retrieve images of an overhead scanner, also known as a planetary scanner or an open book scanner. We searched each engine using two different phrases. For each phrase, we first tried a free text search, followed by an "exact phrase" search, which forces the terms to be immediately adjacent to each other. Finally, we searched using the model number of a specific overhead scanner. We searched the model number both with no spaces (as used by the manufacturer) and with a space inserted, to represent a variant that a searcher might try.
For each search, Table 2 shows the total number of hits returned, the number of relevant hits out of the first twenty ('OK'), and the percentage of the first twenty images displayed that were judged relevant. Note that when the total number of hits was fewer than 20, the percentage column shows the percentage of relevant hits out of that total. If a search returned only one image, and the image was relevant, the percentage column shows 100. Ideally, an image search engine should find as many relevant images as possible, show the most relevant images first, and minimize irrelevant images. To fully evaluate a search from the data given below, look at the numbers in all three columns. Given the scope of the Web, a search that returns only a single image, no matter how relevant, may be indicative of a narrow collection of images, inadequate indexing, or poor choice of search terms.
Before evaluating the results, keep in mind that these tests were unscientific. Our judgments of relevance were necessarily subjective. In Table 2, if the returned image looked like an overhead scanner used for digital imaging, it was counted as relevant. Other types of overhead scanners, such as those used for medical diagnosis, were not counted. This may be unfair to the search engines, but it helps to replicate a typical situation wherein the user has a particular image in mind, even though the terms used to search it may legitimately be used to refer to multiple items.
A few results are worth highlighting. The use of "exact phrase" searching greatly improved the precision of the searches. That is, the percentage of relevant hits went up, meaning you'd have to wade through fewer false hits to find the image you want. However, it had virtually no effect on the total number of relevant images found. At least for the terms searched here, "exact phrase" searching should be used, if possible.

The best results came in response to the model number search without the space, though many of the images retrieved were identical or very similar. The introduction of a space within the model number dramatically reduced the effectiveness of the searches.
The standout in all these searches was Google. It consistently returned the highest number of relevant images. While the addition of the space to the model number reduced the number of relevant images to zero for most of the engines, Google still returned eight in the first twenty images. This may indicate that the other engines rely heavily on file names (which cannot include spaces), while Google makes better use of other text related to the image.
Notes on the searches:
In general, features to improve search accuracy were used, if available. For
example, if an option to exclude banner ads was available, it was used. Otherwise,
searches were done very broadly, without limitation by file format, pixel dimension,
bit depth, etc. Search results were not screened for duplicates.
Cells in tables 2 and 3 are marked with a dash when the search could not
be performed. Ditto, Picsearch and Cobion do not support exact phrase searching.
Also, Cobion searches only alphabetic text and thus could not perform the model
number search.
| Site name | overhead scanner | "overhead scanner" | planetary scanner | "planetary scanner" | ps7000 | ps 7000 | ||||||||||||
| hits | OK | % | hits | OK | % | hits | OK | % | hits | OK | % | hits | OK | % | hits | OK | % | |
| FAST search or alltheweb advanced image search | 30 | 1 | 5 | 5 | 1 | 20 | 5 | 1 | 20 | 1 | 1 | 100 | 8 | 3 | 38 | 104 | 0 | 0 |
| Google advanced image search | 116 | 5 | 25 | 14 | 5 | 36 | 26 | 6 | 30 | 7 | 5 | 71 | 33 | 15 | 75 | 296 | 8 | 40 |
| altavista advanced image search | 4,437 | 0 | 0 | 0 | 0 | 0 | 3,363 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 100 | 16,318 | 0 | 0 |
| Lycos multimedia | 30 | 1 | 5 | 5 | 1 | 20 | 5 | 1 | 20 | 1 | 1 | 100 | 8 | 3 | 38 | 121 | 0 | 0 |
| Ditto | 0 | 0 | 0 | — | — | — | 0 | 0 | 0 | — | — | — | 0 | 0 | 0 | 0 | 0 | 0 |
| Picsearch | 1 | 1 | 100 | — | — | — | 2 | 1 | 50 | — | — | — | 4 | 2 | 50 | 6 | 0 | 17 |
| Cobion
(demonstration site, English) DINO Online (full search, German) |
24,530 | 0 | 0 | — | — | — | 24,912 | 0 | 0 | — | — | — | — | — | — | — | — | — |
| Anomalies | pictures of the solar system, satellite dish | picture of a Sony PlayStation video game console | ||||||||||||||||
As reported in Table 3, we performed some additional searches using variants of terms for some plants and animals. The results show how hit-or-miss the process of image searching can be.
For whatever reason, all the engines other than Ditto did reasonably well finding images of acorn squash, but quite poorly finding images of acorns. The more specific search "oak acorn" (not searched as an exact phrase) was an improvement over plain "acorn" but the number of relevant hits was still low.
The term "bush baby" (a small, nocturnal, arboreal primate from Africa) was chosen for its ambiguity, and did not disappoint. Some of the more humorous false drops included pictures of George W. Bush (with and without his twin daughters as babies), and those of other babies, fetal sonograms, Britney Spears, and various bushes. Surprisingly, searching the terms as an exact phrase only slightly improved the number of relevant images retrieved and the addition of a third descriptive term ("primate") had a mostly negative impact. In some cases it was possible to see where the image engines had gone wrong. For example, in one case a "bush baby" search returned a picture of a lemur. A look at the page containing the lemur photo showed that it also included a bush baby photo. In fact, the lemur photo was directly below the bush baby photo and its caption. Apparently the engine associated the photos with the caption above, rather than the correct one, below.
Google was not nearly as dominant for these searches. Cobion
and Picsearch excelled with "acorn squash," with the former returning
12 relevant images out of a total of 15, and the latter 13 out of 20. Ditto
and Lycos had the best results for "bush baby."
| Site name | acorn squash | acorn | oak acorn | bush baby |
"bush baby" |
bush baby primate | ||||||||||||
| hits | OK | % | hits | OK | % | hits | OK | % | hits | OK | % | hits | OK | % | hits | OK | % | |
| FAST Search or alltheweb advanced image search | 91 | 11 | 55 | 4,891 | 0 | 0 | 274 | 3 | 15 | 186 | 4 | 20 | 56 | 7 | 35 | 1 | 1 | 100 |
| Google Advanced Image Search | 339 | 10 | 50 | 11,800 | 3 | 15 | 796 | 4 | 20 | 782 | 4 | 20 | 186 | 6 | 30 | 5 | 2 | 40 |
| Altavista Advanced Image Search | 1,621 | 6 | 30 | 711 | 1 | 5 | 5,547 | 0 | 0 | 41,701 | 4 | 20 | 7 | 4 | 57 | 41,797 | 5 | 20 |
| Lycos Multimedia | 109 | 11 | 55 | 5,203 | 1 | 5 | 309 | 5 | 25 | 295 | 8 | 40 | 59 | 7 | 35 | 1 | 0 | 0 |
| Ditto | 1 | 0 | 0 | 289 | 0 | 0 | 2 | 0 | 0 | 6 | 5 | 83 | — | — | — | 0 | 0 | 0 |
| Picsearch | 15 | 12 | 80 | 1,403 | 1 | 5 | 50 | 4 | 20 | 18 | 4 | 22 | — | — | — | 0 | 0 | 0 |
| Cobion
(demonstration site, English) DINO Online (full search, German) |
12,583 | 13 | 65 | 6,572 | 1 | 5 | 56,786 | 2 | 10 | 134,707 | 1 | 5 | — | — | — | 137,856 | 13 | 15 |
| Anomalies | pictures of squash players on a squash court and pictures of someone squashing a hat | a picture of a Borg cube from Star Trek | pictures of gumball machines |
pictures of George W. Bush; George Bush's twin daughters as babies; human babies; bushes, sonograms, Britney Spears |
||||||||||||||
Our final tests involved attempts to locate specific, unique images, including works of art, photographs and manuscript pages. The results are in Table 4. We chose images that we knew to be available on the Web, and that are accessible to Web crawlers (that is, they have static URLs, rather than ones generated on-the-fly from a database). The collections were chosen at random, as were the individual images.
In each case, we first tried to locate the image based on its file name. This was done to verify the presence of each image in each image search collection. The file names are mostly quite cryptic, and would not likely be employed by a real user. However, if a file name search comes up empty, chances are the image is not present in the collection. Each image was also searched by title (HTML title tag) or figure caption, as well as by descriptive keywords (chosen by us).
In table 4, results are marked either 'y' if the image was found by the search technique indicated, or 'n' if it was not. For the most part, we examined the entire result set. In a few cases the result set was extremely large, so we reduced it by filtering for file format, something a user probably wouldn't do, since they wouldn't know the file format ahead of time. However, the technique permitted us to complete the study, indicating whether the image in question could be found, if the user was patient enough.
We performed searches for four known items—a post card, a manuscript page, and two photographs. Just to confirm that these search engines do index "serious" images, we also did searches for a famous work of art (Salvador Dali's "The Persistence of Memory") and a famous photograph (Alfred Stieglitz' "The Steerage.") All seven engines were able to find the Dali and the Stieglitz, whether searched by title or by title fragment combined with the artist's last name.
The results for the less well-known images were far less exact. Searched by file name, two of the images were found by three of the seven search engines, and two by one of the seven. Google found at least one version of all four images, Cobion found two, and altavista and Picsearch found one each. So, for starters, it appears that most of the image search engines haven't bothered to collect the images from the digital image collections we chose to search.
The title and keyword searches were even less impressive. Only Google was able to find any of the four images by title, caption or keywords, and it succeeded in finding three-out-of-four by keyword search, and for those that had titles, it found two-out-of-three by title. The ability to locate images using descriptive text is critical, since for most images and most users, an image that can only be found by a file name search might just as well not be there.
Overall, Google was the standout. Of the eight unique test images (including different-sized versions of the same image), Google had seven in its collection (missing only the full-sized image of the Denver City Park fountain) and it was able to retrieve most of them in response to descriptive queries.
Notes on the searches:
Where a table cell contains multiple 'y' or 'n' notations, there was more than
one version of the image available, such as a thumbnail and one or more larger
versions. In those cases, the result for the thumbnail is given first, followed
by progressively larger versions. Cobion was unable to perform some of the searches,
due to its inability to search numerals. However in one case we were able to
find an image in Cobion by searching just the non-numeric portion of the file
name.
| Site name | ||||||||||||||||||
| file name | title | key-word | file name | title | key-word | file name | title | key-word | file name | title | key-word | file name | title | key-word | file name | title | key-word | |
| FAST search or alltheweb advanced image search | n/n | n/n | n/n | n | n | n | n/n/n | — | n/n/n | n/n | n/n | n/n | — | y | y | — | y | y |
| Google advanced image search | y/n | n/n | y/n | y | y | y | y/y/y | — | n/n/n | y/y | y/y | y/y | — | y | y | — | y | y |
| altavista advanced image search | n/n | n/n | n/n | n | n | n | n/n/n | — | n/n/n | y/n | n/n | y/n | — | y | y | — | y | y |
| Lycos multimedia | n/n | n/n | n/n | n | n | n | n/n/n | — | n/n/n | n/n | n/n | n/n | — | y | y | — | y | y |
| Ditto | n/n | n/n | n/n | n | n | n | n/n/n | — | n/n/n/ | n/n | n/n | n/n | — | y | y | — | y | y |
| Picsearch | n/y | n/n | n/n | n | n | n | n/n/n | — | n/n/n | n/n | n/n | n/n | — | y | y | — | y | y |
| Cobion
DINO Online |
y/y | n/n | n/n | — | n | n | — | — | n/n/n | y/y | n/n | n/n | — | y | y | — | y | y |
Image #1 notes
Collection name=On-Line Postcards From the Colorado State Archives Postcard
Collection
URL for collection=http://www.archives.state.co.us/tour/caps.htm
URL for page=http://www.archives.state.co.us/tour/pcdecp.htm
(thumbnail) http://www.archives.state.co.us/tour/pcde18.htm
(full size)
File name=pcde46.gif (thumbnail); pcde18a.gif (full size)
Title/Caption=Denver City Park Electric Fountain and Pavilion
Keywords=Electric Fountain
Image #2 notes
Collection=Captain Cook's Journal 1768-71 Endeavour
URL for collection=http://www.nla.gov.au/pub/endeavour/
URL for page=http://www.nla.gov.au/pub/endeavour/mantran/manu01.html
File name=489b.jpg
Title/Caption=Captain Cook's Endeavour Journal - The Manuscript
Keywords=Captain Cook Endeavour
Image #3 notes
Collection=William Gedney Photographs and Writings
URL for collection=http://scriptorium.lib.duke.edu/gedney/
URL for page=http://scriptorium.lib.duke.edu/gedney/thumbs/composers/composers1.html
(thumbnail); http://scriptorium.lib.duke.edu:80/gedney/photographs/CM/CM00/CM0004-72dpi.jpeg
(72 dpi); http://scriptorium.lib.duke.edu:80/gedney/photographs/CM/CM00/CM0004-150dpi.jpeg
(150 dpi)
File name=CM0004-thm.jpeg (thumbnail), CM0004-72dpi.jpeg (72 dpi), CM0004-150dpi.jpeg
(150 dpi)
Title/Caption=None
Keywords=Leonard Bernstein
Image #4 notes
Collection= The Construction of the Empire State Building, 1930-1931
URL for collection= http://www.nypl.org/research/chss/spe/art/photo/hinex/empire/empire.html
URL for page= http://www.nypl.org/research/chss/spe/art/photo/hinex/empire/empire.html
(thumbnail); http://www.nypl.org/research/chss/spe/art/photo/hinex/empire/rivets.html
(full size)
File name=rivets.gif (thumbnail), rivets.jpeg (full size)
Title/Caption=Crew Attaching Rivets
Keywords=Empire State Building rivets
Image #5 notes
Title=The Persistence of Memory
Keywords=persistence memory dali
Image #6 notes
Title=The Steerage
Keywords=steerage stieglitz
Conclusions (or what's wrong with this picture?)
Despite the inherent weakness in basing indexing on text that is loosely
affiliated with the image, image search engines work reasonably well if the
evaluative criterion is the ability to bring up at least a few relevant images
in response to a query. If the desired image is not too obscure and can be described
adequately in two or three words, chances are it can be found. Search terms
may require some tinkering, especially if ambiguity is a potential problem.
Nevertheless, serious limitations remain when the task is the ability to locate specific images within collections of digital images created from library and archival holdings. There are a number of reasons for this. Foremost is that many such collections are simply inaccessible to the Web crawlers on which all the search engines rely. This includes collections that are stored in databases and those that are created for Web display on-the-fly in response to queries and where the master images are not directly Web accessible. Other sites may not be accessible because of robot exclusion or copyright issues.
However, as our tests indicated, most of the image search engines have failed to index many images that are Web-crawler accessible. Whether this is by policy or by chance isn't known. Some images valued by libraries and archives, particularly those of pages from books, journals, and manuscripts, may not be deemed "collectable" by the image search engines.
For most image searching tasks, Google's Image Search appears to be a good starting point. It's fast and flexible and appears to have a more comprehensive collection than any of the others. In our tests, only Google was able to find specific digital image files from identified digital image collections using descriptive query terms. As of this writing, Google claimed to have the largest image search on the Web with more than 330 million images indexed.
But in the long run, while these image search engines may be fun to use, and genuinely useful as basic reference tools and image sources (copyright issues aside), they do not provide the keys to unlock access to repositories of digital images. Even the best of the image search engines cannot reach the vast collections hidden in the "deep" Web, while for those images that are accessible, the lack of widely adopted metadata standards hinders effective indexing. With Web content produced mainly in English, the use of file names and nearby text to index images also means that many non-English image searches will fail.
Efforts such as the Dublin Core Metadata Initiative and the Open Archives Initiative Protocol for Metadata Harvesting will likely form the basis for tools that will eventually permit the currently dispersed collections and buried treasures of digital images to be conveniently searched and accessed. Until they become widely implemented, the tools profiled in this review will have to suffice.
—Richard Entlich
Calendar of Events
Joint Conference on Digital
Libraries: JCDL 2002
Call for Papers: Due January 14, 2002
To be held: July 14-18, 2002, Portland, OR
The Joint Conference on Digital Libraries is an international forum focusing
on digital libraries and associated technical, practical, and social issues.
The intended community for this conference includes those interested in all
aspects of digital libraries such as infrastructure, metadata, and digital preservation.
Seminar on Digital Preservation of the Record of Science
February 14-15, 2002
Paris, France
The International Council for Scientific and Technical Information (ICSTI),
has been encouraging discussion, debate, and actions to ensure that scientific
records be preserved. With the movement towards digital production and distribution
of scientific information there is a risk that these materials will be lost.
The objectives of the meeting in February include: ensuring that all the parties
are aware of all current activities in the field, evaluating the need for co-ordination
of the efforts, and implementing coordination of these activities. For further
information contact: icsti@icsi.org.
Announcements
ERPANET (Electronic Resource
Preservation and Access NETwork)
The Humanities Advanced Technology and Information Institute (HATII) of Glasgow
University has begun a new digital preservation initiative: ERPANET (Electronic
Resource Preservation and Access NETwork). This European consortium will further
the study of digital preservation of cultural heritage and scientific materials.
This program has been launched by four partners who will share information on
key issues, best practice and skills development in the digital preservation
of cultural and scientific materials, and stimulate new research in the incorporation
of preservation lessons into new generations of software.
The
Evidence In Hand: Report of the Task Force on the Artifact in Library Collections
The final report of the Council on Library and Information Resources task force
concludes an 18-month effort by scholars and librarians to confront issues about
the disposition in the digital era of information recorded on physical media.
Commercial
Entities Developing Digital Rights Management Standard
EDItEUR (European Group for Electronic Commerce in the Book and Serials Sectors)
and the International DOI Foundation (IDF) will be joined by the Motion Picture
Association of America (MPA), the Recording Industry Association of America
(RIAA), the International Federation of the Phonographic Industry (IFPI), Accenture,
ContentGuard, Enpia Systems, and Melodies and Memories Global (a subsidiary
of Dentsu) in a consortium formed to develop a rights data dictionary. This
will be a common dictionary or vocabulary for digital property rights management.
Institute for Museum and Library
Services Announces Digital Library Forum Reports
In spring of 2001, IMLS convened a Digital Library Forum to discuss the implementation
and management of networked digital libraries, including issues of infrastructure,
metadata, thesauri and other vocabularies, and content enrichment. Forum members
include representatives from a range of libraries and museums who have been
involved in digital library initiatives. The Forum discussions led to the development
of two reports: Report
of the IMLS Digital Library Forum on the National Science Digital Library Program,
and A Framework
of Guidance for Building Good Digital Collections.
IMLS has posted both reports on its Web site and invites comments from the professional
community interested in the creation, management, and preservation of digital
information resources.
Managing
the Digitisation of Library, Archives and Museum Materials
Produced by the National Preservation Office of the British Library, this
is now available from their Web site.
Report
Issued on Digital Collections Strategies
Strategies for Building Digitized Collections, by Abby Smith, is now
available from the Digital Library Federation and the Council on Library and
Information Resources. It reports on how libraries are answering questions about
developing and sustaining digitized collections and integrating them with existing
material and services.
Distinguished
Fellowships Offered
The Council on Library and Information Resources (CLIR) and the Digital Library
Federation (DLF) are seeking applicants for their Distinguished Fellows Program.
It provides three-to-twelve-month fellowships for individuals distinguished
in their fields who are working on matters of interest to CLIR and the DLF.
Electronic
Mathematics Archiving Network Initiative
The long-term availability of electronic content is being addressed by Springer-Verlag.
They are joining with the international library community in creating an electronic
information archive and repository for mathematics. Partners include Springer-Verlag
and Tsinghua University Library (China), Goettingen State and University Library
(Germany), and Cornell University Library (USA). The goal is to ensure the preservation
and dissemination of mathematical information.
These two newly redesigned Web sites are worth a look.
Joint Information
Systems Committee (JISC) Web Site
Cedars Project Web Site
![]()
Publishing Information
RLG DigiNews (ISSN 1093-5371) is a newsletter conceived by the members of the Research Libraries Group's PRESERV community. Funded in part by the Council on Library and Information Resources (CLIR) from 1998-2000, it is available internationally via the RLG PRESERV Web site (http://www.rlg.org/preserv/). It will be published six times in 2001. Materials contained in RLG DigiNews are subject to copyright and other proprietary rights. Permission is hereby given for the material in RLG DigiNews to be used for research purposes or private study. RLG asks that you observe the following conditions: Please cite the individual author and RLG DigiNews (please cite URL of the article) when using the material; please contact Jennifer Hartzell, RLG Corporate Communications, when citing RLG DigiNews.
Any use other than for research or private study of these materials requires prior written authorization from RLG, Inc. and/or the author of the article.
RLG DigiNews is produced for the Research Libraries Group, Inc. (RLG) by the staff of the Department of Preservation and Conservation, Cornell University Library. Editor, Anne R. Kenney; Production Editor, Barbara Berger Eden; Associate Editor, Robin Dale (RLG); Technical Researchers, Richard Entlich and Peter Botticelli; Technical Coordinator, Carla DeMello.
All links in this issue were confirmed accurate as of December 14, 2001.
Please send your comments and questions to preservation@cornell.edu.
![]()






